

Containers continue to gain momentum as organizations look for greater efficiencies and lower costs to run distributed applications in their increasingly virtualized datacenters as well as for improving their application development environments. As we have noted before, containers are becoming more common in the enterprise, though they still have a way to go before being fully embraced in high performance computing circles.
There are myriad advantages to containers, from being able to spin them up much faster than virtual machine instances on hypervisors and to pack more containers than virtual machines on a host system to gaining efficiencies in everything from memory to storage. Much of this is due to the fact that containers share an OS under them, while VMs require separate operating system instances inside of them. Applications deployed in containers also are more secure than those simply running on an operating system.
However, there are drawbacks as well. Security can be a concern because containers share an OS. Another issue is that currently, most applications and microservices running in containers are lightweight and stateless – think of front-end web apps – a situation that not only limits the software that can run in them, but also the scalability and elasticity of the apps.
The issue is one of data persistence. Enterprise applications need to be able to not only access current information but also historical data – application history and configuration, for example – and legacy storage technologies don’t always work for containerized applications. In addition, some startups are rolling out point products designed to address the issue but that have to work with other data storage systems. Portworx is one, with its array of container data services that offers everything from persistence to encryption.
Commercial Hadoop distribution MapR is going in another direction by taking a platform approach to the situation. The company today is coming out with its Converged Data Platform for Docker, a persistent storage offering for containers that gives stateful applications and microservices access to files, database tables and message streams, and enables that data to be accessed from any infrastructure resource. It comes as organizations try to embrace the ongoing digitization that is reshaping their data centers, Jack Norris, senior vice president of data and applications, told The Next Platform.
“We’re in the midst of one of the biggest ‘replatformings’ of the datacenter,” Norris said. “A lot of the assumptions of what the enterprise stack is being called into question.”
As businesses look for their IT infrastructures to become more agile, scalable and secure in response to the ongoing digital transformation, it’s become increasingly important to converge the data and make it accessible to apps regardless of where they are or where the data is stored. MapR offers its Converged Data Platform, which integrates such big data tools as Hadoop, Apache Drill, and Spark into a single cluster and enables users to run multiple workloads on the cluster. It also lets users run analytics tasks on data that is both at rest and in motion. The vendor has been building on it over the years, most recently last fall, when it added event-driven support for microservices. MapR is now turning its attention to containers. Included in the Docker-aimed offering is the Persistent Application Client Container (PACC), which includes a pre-built Docker container that provides application access to MapR services like storage (for logging, configuration and binary state), NoSQL K/V and Document Database storage and event streaming for microservices, as well as authentication at the container level for improved security. MapR’s PACC offers containers that can restart or move to any node or datacenter and still access data, and includes a data repository that can be shared by multiple apps.
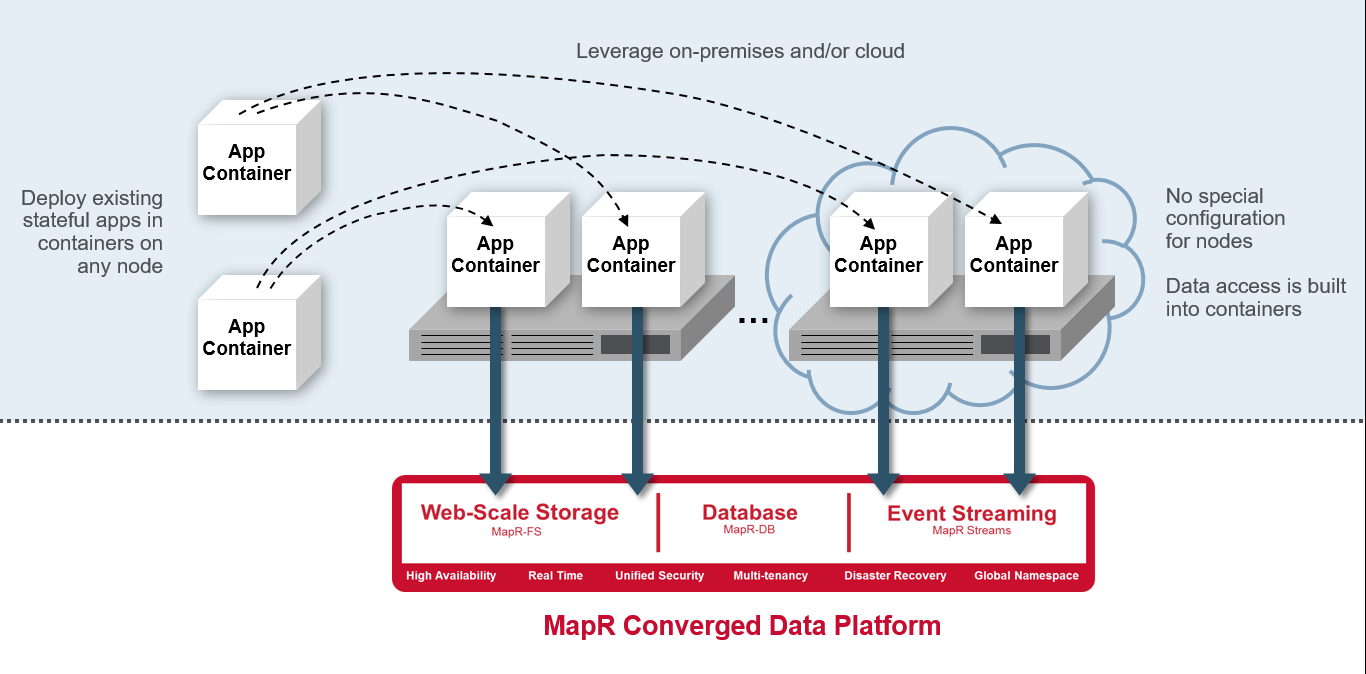
Bigger companies with large numbers of applications, particularly as they move more workloads to the cloud and develop new apps via microservices, will benefit from being able to run stateful apps in containers. Some can have hundreds of apps running in the cloud. Norris pointed to such companies as American Express – with more than $1 trillion in annual transactions – as an example of a company that is migrating more applications to the cloud. Being able to leverage stateful apps in containers will be key to improving the security and efficiency of those workloads. In addition, microservices need highly scalable data systems as well as what MapR calls “multi-dimensional statefulness” – which can include files for configuration, log and binary state, NoSQL database for operational state and persistent streams for communication state. All of these need persistence.
Norris and Dale Kim, senior director of industry solutions for MapR, talked about a number of use cases for the company’s PACC technology when talking about running existing applications in containers, including RDMBS persistence (MySQL, Vertica, and SAP), container image store (Docker registry), rapid-ingest logging (impressions and clicks), source control persistence (Git and Mercurial) and image stores, including thumbnails and high-resolution images.
“The timing [of rolling out the platform for Docker] is really, really good for us because a lot of organizations are in the midst of looking at containers closely and this fills a major gap they were facing,” Norris said. “We’re still in the early days when quite a few customers are adopting it and understand how to use it and a lot are in the beginning stages and learning how to use it.”


Taking Kubernetes Up To The Next Level
From the time Kubernetes was born in the labs at Google by engineers Joe Beda, Brendan Burns, and Craig McLuckie and then contributed to the open source community, it has become the de facto orchestration platform for containers, enabling easier development, scaling and movement of modern applications between on-premises datacenters …

The Ever-Reddening Revenue Streams Of Big Blue
Speaking in generalities across any aspect of history is always risky, but that is what the job of history is. The first wave of open source software in the enterprise in the 1960s through the 1980s was largely academic, and it wasn’t until the second wave of open source hit …
Red Hat Stacks Up Software To Contain AI On Nvidia Platforms
Nvidia and VMware have forged a tight partnership when it comes to bringing AI to the enterprise, which stands to reason given the prevalence of VMware’s ESXi hypervisor and vSphere management tools across more than 300,000 companies worldwide. But there is another important server virtualization and container platform provider: Red …
Be the first to comment