

Choosing the right interconnect for high-performance compute and storage platforms is critical for achieving the highest possible system performance and overall return on investment.
Over time, interconnect technologies have become more sophisticated and include more intelligent capabilities (offload engines), which enable the interconnect to do more than just transferring data. Intelligent interconnect can increase system efficiency; interconnect with offload engines (offload interconnect) dramatically reduces CPU overhead, allowing more CPU cycles to be dedicated to applications and therefore enabling higher application performance and user productivity.
Today, the interconnect technology has become even more critical than ever before, due to a number of factors:
- The exponential increase in the amount of data we collect and use
- The need to analyze data in real time
- The increase in model complexity for research and engineering simulations
- The increase in parallel execution of compute elements
In the Ethernet world, we have seen the development of many stateless offloads such that today there is no Ethernet controller that does not support these offloads. Myricom Myrinet and Quadrics QsNet both focused on enabling smart offload engines, and a case can be made that they lost market share because they were proprietary technologies. Cray Aries, IBM BlueGene, and InfiniBand are also examples for offload interconnect technologies; among them, InfiniBand is an industry-standard technology, which contributes to its leadership.
The adoption of offload interconnect has an impact well beyond high performance computing. For example, Microsoft reported at the Open Networking Summit conference that Remote Direct Memory Access enables moving data at zero CPU utilization, and has therefore standardized its cloud platform on this technology. (Microsoft has used InfiniBand in the past for certain workloads, but is deploying switches using RDMA over Converged Ethernet, or RoCE, in its latest infrastructure.)
There is one datacenter interconnect technology that does not include offload capabilities. That technology was introduced first by PathScale as InfiniPath, then was acquired by QLogic, which changed the name to TrueScale. Three years ago, the same technology was acquired by Intel, which changed the name again, this time to Omni-Path, similar to the original name.
PathScale’s justification for the development of an onload only technology was the emergence of multicore CPUs and the claim that users could not use all the cores, allowing some cores to be allocated for the network operations. That claim does not bear out in practice, as the need for more cores stemmed from the need to increase the system’s compute capabilities. The onload approach has had very limited adoption because it reduces CPU efficiency and overall application performance rather than improves them. For Intel, however, adopting this technology makes perfect business sense – it can help sell more Intel CPUs.
In October, 2016 at the HPC China conference, Intel presented a performance comparison between Omni-Path and InfiniBand, comparing CPU utilization during a data movement test. One would expect that an offload technology such as InfiniBand, which has reported “nearly zero CPU overhead,” would demonstrate lower CPU utilization versus the Omni-Path onload technology. But the Intel report surprisingly claimed the complete opposite:
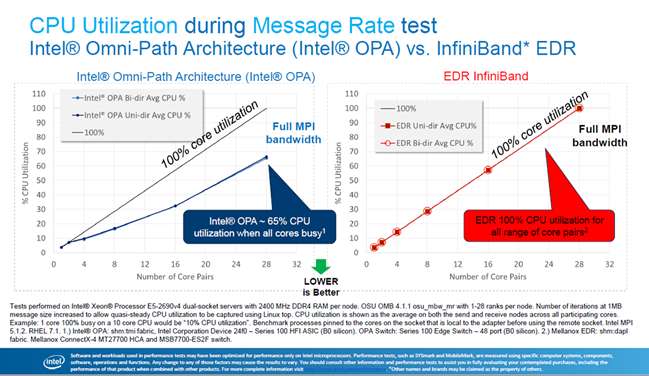
According to Intel’s testing results, Omni-Path consumes 65 percent of the CPU cycles in order to move the data, while InfiniBand consumes 100 percent, or all of the CPU cycles. While this sounds hard to believe, Intel also called out Mellanox’s article, Offloading vs. Onloading: The Case of CPU Utilization as spreading Fear, Uncertainty and Doubt, a term that dates from the early days of the mainframe era when computing first went commercial. This article from Mellanox presented a case for how to properly measure and compare CPU utilization with Omni-Path and with InfiniBand networks. Under this methodology, Mellanox found that Omni-Path required 60 percent CPU utilization while InfiniBand only used 0.8 percent. Interestingly, both Mellanox’s publication and Intel’s report claimed about the same CPU utilization over Omni-Path – Mellanox claimed 59.5 percent and Intel claimed 65 percent – yet there is a huge difference in utilization claims over InfiniBand (0.8 percent versus 100 percent).
The table below presents the results from Mellanox, and the following shows Intel’s labeling of the data as FUD.
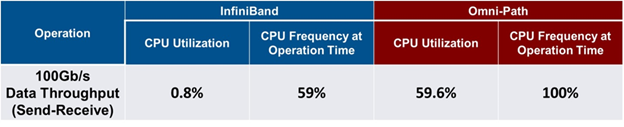

One natural question is how Intel claims to measure 100 percent CPU utilization with the InfiniBand network, while everyone else who reported performance results for InfiniBand claimed nearly 0 percent, including Intel in a prior publication (See, for example: Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store, by Christopher Mitchell, Jinyang Li and Yifeng Geng from New York University and the Tsinghua University; Comparative Performance of InfiniBand Architecture and Ethernet Interconnect on Intel Microarchitecture-based Clusters, by Lars E. Jonsson and William Magro from Intel; Achieving Mainframe-Class Performance on Intel Servers Using InfiniBand Building Blocks, from Oracle; and Improve Performance of a File Server with SMB Direct, from Microsoft).
The answer to the question lies in Intel’s use of the message rate benchmark for its comparative measurement. Message rate benchmarks count the number of messages sent from a source to a destination. In order to accurately count the number of messages, the CPU must constantly poll its memory to check for messages. As a result, the CPU always appears to be 100 percent busy, even if no messages are actually being sent. This test, therefore, is clearly not suitable for measuring CPU utilization. Furthermore, Intel’s test was modified to generate large messages, as opposed to a typical message rate test, which generates very small messages.
If Intel had used the same message rate test on Omni-Path as it used on InfiniBand, CPU utilization should have also been 100 percent for Omni-Path versus the reported 65 percent. The discrepancy appears due to the fact that when testing Omni-Path, Intel did not use CPU polling on memory but rather used other methods, such as CPU interrupt, which would result in lower CPU utilization.
The bottom line is that onload technology cannot consume fewer CPU cycles for network operations than an offload technology. Everyone agrees that Omni-Path consumes around 60 percent CPU (Intel actually claims 65 percent), and it is well established that one of the main advantages of InfiniBand is its extremely low CPU utilization. As long as the benchmarks are the same, the numbers bear that out, and InfiniBand produces better results.
The advantage of using offload technology and its corresponding lower CPU utilization is the ability to dedicate more CPU cycles to application work, which enables applications to run faster and facilitates higher efficiency and productivity in the overall system by supporting more simulations or application jobs at any given time. Of course, there are other factors involved in creating an efficient, high-performing system, including hardware-based acceleration engines such as data aggregation and reduction engines, MPI Tag Matching engines and more, all of which are part of the latest InfiniBand solutions.
InfiniBand implements offloading engines to reduce the overhead on the CPU and to accelerate data analysis, resulting in higher application performance and higher overall return on investment. The latest generation of InfiniBand technology adds support for in-network computing and in-network memory, in which the network delivers computing and memory throughout the network, wherever the data is distributed. This is essential in the transition of the data center from a CPU-centric architecture to a data-centric architecture, allowing the datacenter to overcome latency bottlenecks and to analyze greater amounts of data in real time.
Mellanox and other organizations have published several application cases in the past that have shown a clear advantage to using InfiniBand, Designing Machines Around Problems: The Co-Design Push to Exascale, by Doug Eadline. At the October 2016 OpenFOAM conference, a user who was testing on an Omni-Path system presented performance issues associated with onload technology. The reported issues centered around the inability to use all CPU cores effectively, resulting in degraded application performance. The work-around was to use only partial CPU cores, which allowed some CPU cores to handle communications instead of application tasks, which is counterintuitive and counterproductive.

In its October 2016 presentation, Intel referred to the reported application performance claims as FUD, as shown above. As a rule, an offloading technology should enable higher application performance. In application cases in which little data communication is required, the performance gap between offload technology and onload technology should be minimal. With added data communication, the performance gap increases. To reduce the performance gap, simply reduce the CPU cores being used on every server, allowing free CPU cores to manage and handle non-application operations, such as network management. In that case, the performance gap between offload and onload will be lower (assuming the offloading technology is also limited to a smaller number of CPU cores). Mellanox was able to reproduce Intel’s results above using this method. Of course, this method of testing does not reflect the system’s performance capabilities, nor does it reflect the user’s purchasing criteria. No one would purchase a server to use only part of the available CPU cores.
Mellanox has also updated the original InfiniBand testing results, and the overall performance comparison is presented below:
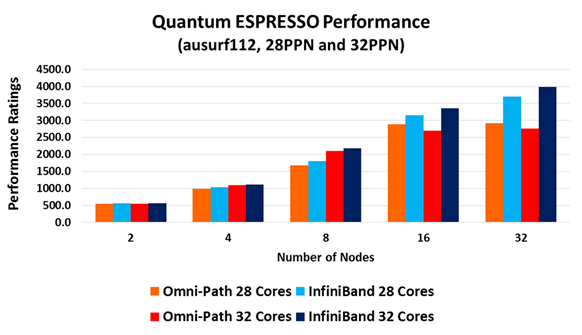
The benchmark cluster Mellanox used for the updated performance test included 32 servers, each with dual socket 16-core Intel Xeon E5-2697A CPUs. In one set of testing, only 28 CPU cores from the available 32 cores were used, and in a second set of testing, all of the available 32 cores per server were used. The results confirm the claims that lowering the number of cores that are available to the application improves the performance of the onload technology, albeit at great expense (paying for more cores than are being used).
Moreover, the results demonstrate the leading performance of offload technology (InfiniBand). Intel did not present results for 32 nodes, and the chart above suggests why. Omni-Path does not scale beyond 16 nodes, while InfiniBand does. InfiniBand enables 30 percent higher application performance for the 28-core case and more than 40 percent higher application performance when all 32 cores are utilized.
While application owners may care more about achieving absolute performance, focusing more on how fast they can analyze and solve research or engineering problems, datacenter managers are likely to be more interested in overall performance, factoring in cost/performance criteria. The testing results in the chart above clearly show that InfiniBand with 16 nodes outperforms Omni-Path with 32 nodes. This equates to about a 40 percent reduction in the cost of the system (including servers, CPUs, memory, and interconnect) to achieve the same application performance.
When choosing between onload and offload, the real numbers point to InfiniBand as the leading interconnect technology for today’s high performance computing storage and compute platforms.
Gilad Shainer has served as Mellanox’s vice president of marketing since March 2013. Previously, he was Mellanox’s vice president of marketing development from March 2012 to March 2013. Shainer joined Mellanox in 2001 as a design engineer and later served in senior marketing management roles between July 2005 and February 2012. He holds several patents in the field of high-speed networking and contributed to the PCI-SIG PCI-X and PCIe specifications. Shainer holds a MSc degree (2001, Cum Laude) and a BSc degree (1998, Cum Laude) in Electrical Engineering from the Technion Institute of Technology in Israel.

Blackwell Is The Fastest Ramping Compute Engine In Nvidia’s History
With the months-long blip in manufacturing that delayed the “Blackwell” B100 and B200 generations of GPUs in the rear view mirror and nerves more calm about the potential threat that the techniques used in the AI models of Chinese startup DeepSeek better understood, Nvidia’s final quarter of its fiscal 2025 …
Everyone Is Chasing What Nvidia Already Has
Transitions in the datacenter take time. It took Unix servers a decade, from 1985 through 1995, to supplant proprietary minicomputers and a lot of mainframe capacity that would have otherwise been bought. And from 1996 through 2001 or so, Sun Microsystems servers set the pace and reaped the profits, although …
Nvidia Weaves Silicon Photonics Into InfiniBand And Ethernet
When it comes to networking, the rules around here at The Next Platform are simple. When it comes to hyperscale networking for massively distributed, largely not coherent applications, the rule is: Route when you can, and switch if you must. For HPC and AI workloads, which are both latency and …
I can smell the fear of the Mellanox marketing department from here! Sounds like you’re trying to fit your technology into a synthetic benchmark…
Both vendors are spreading the FUD, but Mellanox definitely threw the first stone and is now back tracking.
True, every vendor will tell you they’re the best. But Quantum Espresso is not a synthetic benchmark. It’s a real-world application that is widely used.
Some interesting results, based on top500 data and linear regression: https://rpubs.com/alex-lev/216789.