

While there are some sectors of the tech-driven economy that thrive on rapid adoption on new innovations, other areas become rooted in traditional approaches due to regulatory and other constraints. Despite great advances toward precision medicine goals, the healthcare industry, like other important segments of the economy, is tied by several specific bounds that make it slower to adapt to potentially higher performing tools and techniques.
Although deep learning is nothing new, its application set is expanding. There is promise for the more mature variants of traditional deep learning (convolutional and recurrent neural networks are the prime example) to morph into domain-specific tools to bolster healthcare capabilities in new ways. Of course, this is not without a set of challenges, which we will get to in a moment.
Over the last year deep learning moved from its anchors in video, image, and speech recognition and analysis for more commercial-geared applications into an increasing array of scientific fields. In healthcare, deep learning is expected to extend its roots into medical imaging, sensor-driven analysis, translational bioinformatics, public health policy development, and beyond.
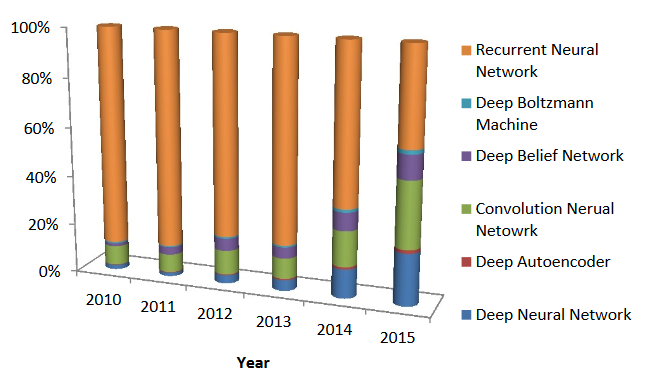
As a group of researchers analyzed the state of deep learning in health informatics, noting “rapid improvements in computational power, fast data storage, and parallelization have contributed to the rapid uptake of deep learning in addition to its predictive power and ability to generate automatically optimized high-level features and semantic interpretation from the input data.” In addition to tracking the significant jump in the number of peer reviewed publications about the use of deep learning in healthcare, they further tracked the evolution of deep learning approaches.
“In domains such as health informatics, the generation of this automatic feature set without human intervention has many advantages. For instance, in medical imaging, it can generate features that are more sophisticated and difficult to elaborate in descriptive means. Implicit features could determine fibroids and polyps, and characterize irregularities in tissue morphology such as tumors.”
Further, they note that “in transformational bioinformatics, such features may also determine nucleotide sequences that could bind DNA or RNA strands to a protein.” Other areas extending as far as public health monitoring can leverage deep learning to capture data for macro trends based on regions and populations, for example.
While there are promises of a bright future for deep learning in health informatics, there are certainly challenges and a health degree of skepticism about how fully and when deep learning will be a full fit in the wide-ranging area is necessary.
“Despite some recent work on visualizing high level features by using weight features in a convolutional neural network, the entire deep learning model is often not interpretable,” the researchers note. “Consequently, most researchers use these approaches as a black box without the possibility to explain why it provides good results, or without the ability to apply modifications in the case of misclassification issues.” This black box problem is compounded by the fact that neural networks can be tricked (although not necessarily on purpose).
“Patient and clinical data is costly to obtain and healthy control individuals represent a large fraction of a standard health dataset. Deep learning algorithms have mostly been employed in applications where the datasets were balanced, or, as a work-around, in which synthetic data was added to achieve equity. The latter solution entails a further issue as regards the reliance of the fabricated samples.”
As the team explains via an example, “it is possible to add small changes to the input sample (such as imperceptible noise in an image) to cause samples to be misclassified” but of course, any machine learning approach can suffer the same problems. On the flip side, it is also possible to “obtain meaningless synthetic samples that are strongly classified into classes even though they should not have been classified. This is also a genuine limitation of the deep learning paradigm, but it is also a drawback for other machine learning algorithms as well.”
“Deep learning predominantly requires large amounts of training data. Such a requirement makes the classical barriers to entry associated with machine learning (data availability, privacy) more critical.”
Training neural networks of any type requires a great deal of data, and that is just to allow them to recognize known features. “Not all applications, particularly rare diseases or events, are well-suited to deep learning,” the researchers note, explaining that the problem of “overfitting” (which leads to an inability for the neural net to make suitable generalizations) is still a problem.
The problems cited for deep learning in healthcare are similar in other areas, particularly in terms of the black box problem, overfitting, and reliability. However, this review does provide in-depth insight about what areas might benefit from implementing machine learning even if there is some maturation of the space required.

Be the first to comment