

Over the years there have been numerous efforts to use unconventional, low-power, graphics-heavy processors for traditional supercomputing applications—with varying degrees of success. While this takes some extra footwork on the code side and delivers less performance overall than standard servers, the power is far lower and the cost isn’t even in the same ballpark.
Glenn Volkema and his colleagues at the University of Massachusetts Dartmouth are among some of the most recent researchers putting modern gaming graphics cards to the performance per watt and application benchmark test. In looking at various desktop gaming cards (Nvidia GeForce, AMD Fury X, among others) against their high end computing counterparts (including the Nvidia Tesla K40—the same found in many top tier suprecomputers) the team found that these cards offer similar application boosts when compared to their more expensive corollaries in HPC, even with the differences in floating point precision capabilities.
Just as a refresher, Nvidia has three distinct lines of GPUs. The GeForce segment is aimed at desktop gaming; the OpenGL series (which uses the same chips but has better drivers) is in the middle, and at the extreme end (the one we tend to cover here) is the Tesla generation, which is the top-end chip, emphasizes double-precision, has ECC memory, and is targeted at ultra-scale workloads in HPC and now, with the arrival of Pascal, at deep learning. To put this in price perspective, the cost scales with the capability with the upper end of Tesla cards running close to $4000. And it is in this cost benefit where the core of Volkema’s research stems. AMD’s Radeon R9 Fury X cards are the desktop gaming option versus the A10-7850K APU, which is roughly on par with Nvidia’s Tesla K40—and designed for the same types of workload (although it is more than a coprocessor).
“Even though the lower end cards were artificially restricted in double-precision, we found there were enough FLOPS, even with those restrictions. That capability wasn’t a limitation for the scientific codes we ran. All of the cards have full-throttle single precision performance, and recently, Nvidia released FP16 for machine learning [half precision]. There is actually quite a bit of code that can do single or half precision, but a lot of the scientific codes we run is double precision, or even quad-or octa-precision,” Volkema tells The Next Platform.
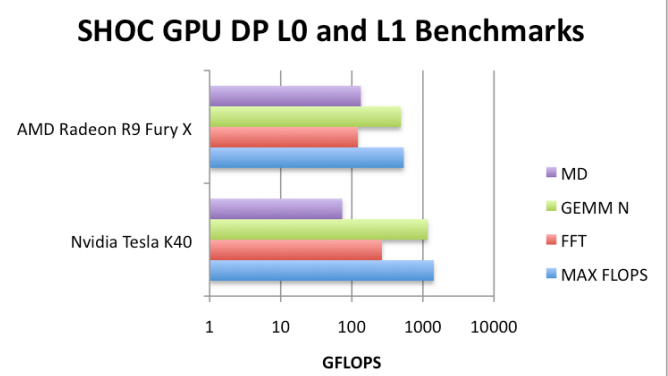
The interesting thing here is that they found that there was enough double precision FLOPs capability but the real bottleneck is memory bandwidth. This will not come as any surprise to anyone in HPC, but as they found, even though there are more FLOPS on a Tesla card versus a low-end gaming GeForce GPU, the code saturates the memory bandwidth on both well before it exhausts on the FLOPs available on either.
Volkema and team were also behind what eventually became Project Condor, the U.S. Air Force Research Laboratory’s supercomputer built from 1.760 PlayStation 3 consoles, which made news at the time (2010) because of the cost and energy efficiency figures. Each unit (based on the Cell multicore processor) was close to $400 (comparable servers would have been several thousand dollars) and consumed roughly 10% the power of traditional supercomputers.
Since that time, Volkema and colleagues have received the leftover PS3s and although they’re almost eight years old, are still using those for experiments. “The PS3 in particular seemed ideally designed for high performance computing because it was an early version of a heterogeneous architecture with a central processing unit surrounded specialized units,” he says. The team also is experimenting with a 32-card Nvidia Tegra system, which was purchased from the Bitcoin concept gone bad.
A good deal of the work on the Nvidia Tegra benchmarking was done on the “Elroy” cluster, which boasts 50 gflops per watt for the 32 cards linked with Gigabit Ethernet.

As one might imagine, on the software side, there is some real effort required to get many scientific codes up and running on gaming hardware, although the problem is not so different from the programming hurdles to get code accelerated using GPUs on codes that haven’t had parallel sections of code optimized. For developers, using gaming graphics cards is similar to using server-class GPUs; CUDA and OpenCL are standard.
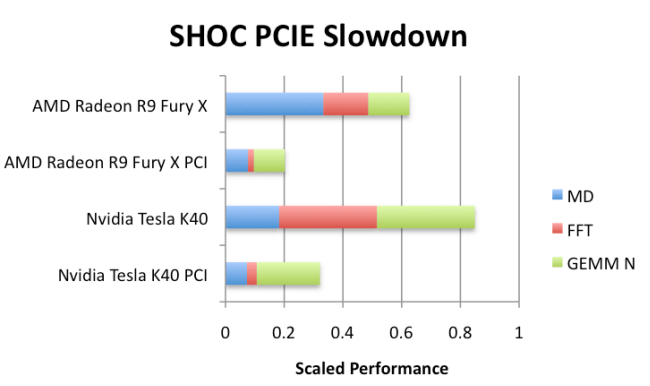
“A lot of scientific code might be 20% serial and 80% potentially parallel,” Volkema says. Interestingly, they did the expected thing with one of their scientific codes and moved the serial sections to the CPU while offloading the parallel sections to the GPU. In doing so, they found that it was actually beneficial to take the 20% serial portion and offload that to the GPU (which usually doesn’t do well on serial tasks) but since the data movement between the CPU and GPU was curtailed, this was actually faster. This seems counterintuitive but resulted in faster execution times because of PCI bus limitations, something that will be eliminated when NVlink comes around, although not for gaming graphics cards.
The team concludes that the primary advantage of using gaming cards for scientific applications is “low cost and high power efficiency. Rapid advances and significant innovation is being enabled through major investments made by the gaming industry. This is driven by strong consumer demand for immersive gaming experiences that require computational power. High volume and intense competition keep costs low, while improvements to power efficiency are forced by the engineering challenges and costs associated with dissipating increasing amounts of waste heat from a discrete device and the limited battery life of a mobile device.”

Performance aside I would never ever Trust gaming drivers for usage in any engineering, or medical workloads, where accuracy is of primary importance. The gaming/graphics gaming compute drivers are not vetted for accuracy and error free usage like the professional graphics drivers which have undergone a rigorous certification process to work with the professional software packages.
I would never trust that any engineering calculations done for say a balcony’s structural engineering analysis ever be done using the non certified gaming GPU drivers or gaming GPU hardware that lacks GPU memory ECC abilities. Gaming drivers are designed to provide as many gaming frames per second at the cost of accuracy and of error free results. The very reason that the professional GPU HPC/Workstation/server SKUs cost so much more than the gaming GPUs is that costly driver certification process to make sure error rates are as low a possible and computational accuracy is high. Professional graphics drivers cost a lot to certify and maintain, and the Pro GPU SKUs have the longer term driver support, and this is why the end user is paying the higher costs.
It’s nice that this research is being carried out but many gaming GPU’s memory do not include full error correction to save money, and It’s the professional drivers that add much to the cost of the Pro versions of the GPUs that come with the certified drivers and better error correction hardware. The Pro GPU SKUs are also clocked lower than the gaming SKUs for the same reasons that the server CPU variants are clocked lower than the enthusiasts CPUs, power usage and lower error rates.
As for memory bandwidth constraints HBM/HBM2 memory should relieve a lot of that stress while operating at much lower clock rates than GDDR5. HBM2 will also have better error correction abilities. HBM2 is going to be very hard to come by for consumer SKUs, as the HPC/Workstation and server markets will want all the HBM2 for the power savings, and the much higher effective bandwidth that HBM/HBM2 provides at clock rates 1/16th to 1/8th the clock rates of the fastest GDDR5/5X. Also the JEDEC standard only defines what is necessary for the functioning of a single HBM/HBM2 stack, so expect that the server/HPC/workstation GPU SKUs may be getting 6 or 8 HBM2 stacks per GPU. As the total number of HBM/HBM2 stacks a GPU can have is only limited by the total size of the interposer needed to host the GPU die and HBM2 stacks.
As it stands I have hard time trusting anything done on the basis of IEEE754. Check out “End of Error” by John Gustafson. I strongly believe this is where the future is in areas where precision matters.
Machine learning today shows there are a lot of areas where precision does not matter at all, since you have amounts of data so large that you can extract required precision by statistical means. This is why FP16 hardware became available and google designed their own hardware especially for machine learning.
So yes, current crop of gaming gpus are plenty good for majority of intended use cases and even for some unintended ones, but you can’t cram every mission critical task on them.
Well I would be extremely careful with your statements. As in reality they are the same chips you really think nVidia builds different chips for Quadro, Geforce and Tesla. Not they don’t they just bin it in a different matter. The high reliable parts go into pro section. The reason why they are really more expansive isn’t the driver development either. They spend 100x more man hours on the Geforce driver than on Quadro. Reason? There are 1000x more applications (games) which can run far more complex codepath with 10000x more potential negative voices (gamers) out there than there are professionals. Gamers is stll the bred and butter for nVidia that keeps the machine going as you need that volume. Even if they pretend it to be otherwise.
The real reason why pro cards are more expansive is they have to give 3-5 years warranty. While on consumer its 1 year. But if you push a GPU 24/7 under high strain it is very likely to break inside that 1 year. So they have to cover a potential replacement (or even two) into the price.
A small crew of Russian scientists from Lomonosov Moscow State University (established in 1755) has reporting that using a single GeForce GTX 670 on a PC class machine with CUDA and the PGI CUDA Fortran Compiler was able to outperform the same calculus done by a team in Germany on an expensive supercomputer by a speed ratio of 1:200
Small correction to your article it is the nVidia Geforce, Quadro (not OpenGL) and Tesla line