

Since the 1990s, MPI (Message Passing Interface) has been the dominant communications protocol for high-performance scientific and commercial distributed computing. Designed in an era when processors with two or four cores were considered high-end parallel devices, the recent move to processors containing tens to a few hundred cores (as exemplified by the current Intel Xeon and Intel Xeon Phi processor families) has exacerbated scaling issues inside MPI itself. Increased network traffic, amplified by high performance communications fabrics such as InfiniBand and Intel Omni-Path Architecture (Intel OPA) manifest an MPI performance and scaling issue.
In recognition of their outstanding research and solution to the MPI message matching problem, the ISC 2016 (International Supercomputer Conference) research papers committee has announced they will award the Hans Meuer Award to the Intel authors Mario Flajslik, James Dinan, and Keith D. Underwood for their paper Mitigating MPI Message Matching Misery. Their results show that it is possible to speed MPI application performance by as much as 3.5x without having to make any changes to the application itself*.
The MPI Message Matching Misery problem occurs in distributed systems of all sizes from small compute clusters and cloud configurations to leadership class supercomputers. Increased network traffic is the culprit as it increases the depth of the MPI message queues in participating MPI processes. These message queues preserve the order that messages arrive (e.g. in a FIFO or First-In, First-Out basis). During the message matching process, the queue is searched starting with the oldest entry first. Most MPI queues are implemented as linked lists, which mean that the runtime of this search increases linearly with the number of elements in the queue. The authors note, “MPI message ordering has historically presented a significant hurdle to the development of alternative MPI message matching structures.”
Most MPI implementations maintain a posted receive queue and unexpected message queue. A posted receive operation is one where a process has posted some form of MPI_RECV. In contrast, unexpected messages occur when an MPI process receives a message without first posting a receive, which can happen quite often as MPI implementations typically send short messages “eagerly” without first coordinating with the receiver. Fast processors – especially multi-core processors running in hybrid MPI environments and/or systems containing large numbers of processing cores – can overwhelm slower receivers and greatly increase their queue depths.
The runtime on the linear search time can be even larger as MPI implementations must handle wildcard messages, such as those that occur when the source is set to MPI_ANY_SOURCE or the MPI_ANY_TAG is used. Flajslik et al. discuss various strategies for handling wild cards in their paper. While beyond the scope of this article, it is important to note that managing wildcards can greatly increase the cost of MPI message matching. Some implementations, for example, utilize multiple queues. In this case a linear search must be performed on each queue to handle wildcard messages.
In the old days when MPI was first created, the runtime of this message matching algorithm was not a problem as the queues tended to be short – especially as compute clusters were smaller. Even today, some applications post a small number of receive operations at a time, which results in shorter queues. In these cases, the MPI message matching problem is not an issue.
In their paper, the Intel authors identified three common classes of MPI application communication patterns that do result in deeper queues and can exhibit the performance degradation and scaling issues associated with the MPI message matching problem. These are:
- Global communication Custom all-to-all communications are particularly at risk due to the deep message queues they create. Applications that use MPI_Alltoall() are at risk, but the risk depends somewhat on if the MPI library limits queue depths by restricting the number of posted receive operations.
- Incast communication In particular, applications that utilize an all-to-one communication pattern have been characterized by the authors as being particularly at risk.
- Multithreaded communication. Hybrid applications that utilize thread based parallelism (utilizing OpenMP, IntelThreading Building Blocks (Intel TBB), Cilk+, or other parallel computing techniques) can increase the MPI queue depths by the number of threads per process. Hybrid MPI + thread models are becoming increasingly popular – especially as the number of cores per processor increases.
The authors proposed a “binned matching algorithm” in their paper that satisfies MPI ordering semantics in the presence of wildcards while also mitigating the performance and scaling issues associated with MPI message search. Their solution replaces the existing linked list approach with a hash map that significantly reduces time spent searching for a message match and that scales well according to number of messages. They note in the paper that, “a simple hash map is not sufficient for ensuring the MPI ordering requirements in the presence of wildcard receive operations. Our algorithm efficiently stores additional metadata to maintain ordering, and is able to provide faster MPI message matching times, while at the same time maintaining correctness and performance in the presence of wildcards.”
The algorithm was also designed to support efficient hardware offload acceleration as well as fast software implementations. In particular, the authors note the binned hashmap approach breaks message queues into multiple bins that lend itself to fine-grained locking which in turn supports more concurrency in multithreaded MPI implementations. For hardware acceleration, the authors note, “As system-level and node-level scales increase, and implementers attempt to drive down MPI messaging latency, there is renewed interest in offloading MPI message matching.”
Performance Evaluations
Several representative MPI benchmarks were used to evaluate the performance improvements of the proposed algorithm: the Fire Dynamics Simulator (FDS), LAMMPS, and Integer Sort.
The evaluation was conducted on a 64 node cluster equipped with Intel Xeon E5-2697 v3 processors where the nodes were connected through Mellanox ConnectX-3** FDR InfiniBand host channel adapters.
Fire Dynamics Simulator
FDS is a computational fluid dynamics application that is representative of a significant class of MPI workloads. For this reason it has been included in the SPEC MPI benchmark suite.
The figure below shows the speedups observed for various numbers of bins compared to the baseline linked list MPI implementation. The authors attribute the 3.5x speedup* to the deeper queue depths incurred through the use of the MPI_Allgather() operation for communication.
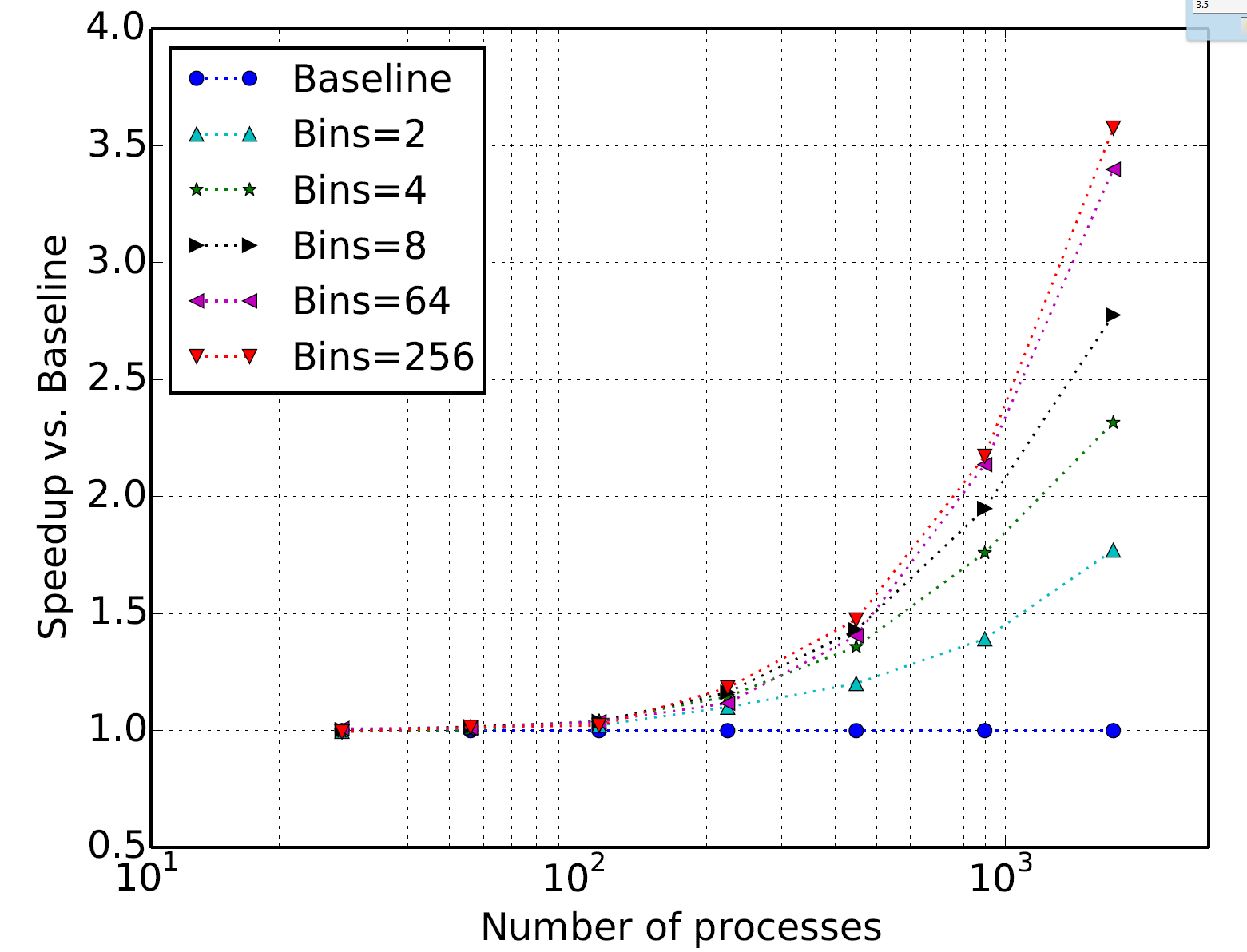
LAMMPS
LAMMPS is a molecular dynamics simulator. The authors evaluated the rhodopsin protein benchmark, which uses particle-mesh method to calculate long range forces. Part of that calculation makes multiple calls to distributed 3-D FFT that relies on an MPI all-to-all communication exchange.
The following figure shows a 50x improvement in match attempts.
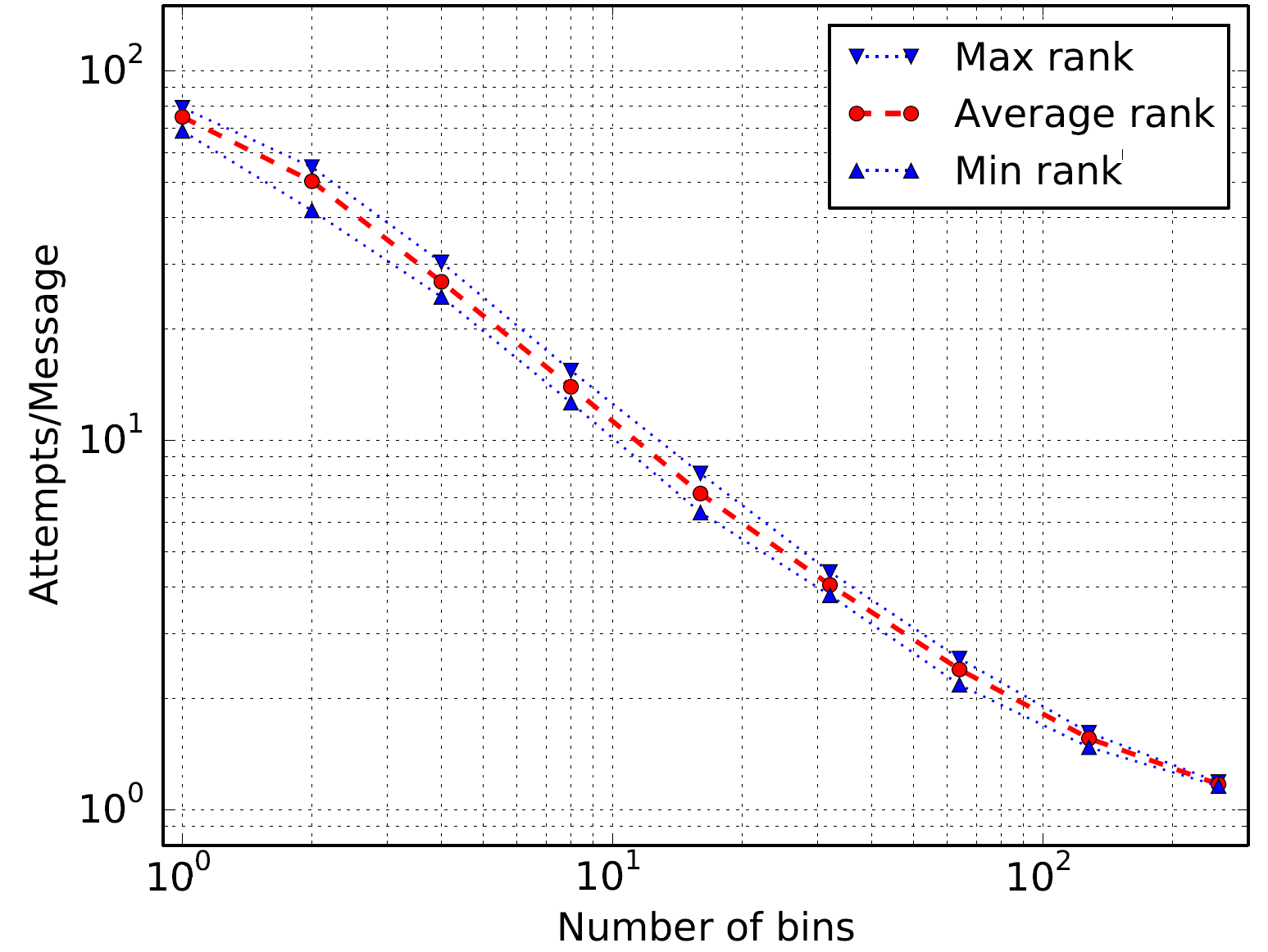
Integer sort
Integer Sort is taken from the NAS Parallel Benchmarks suite. The Integer Sort benchmark makes use of MPI_Alltoall() collective, with large message sizes. Results show a 10x reduction in the number of match attempts per message.
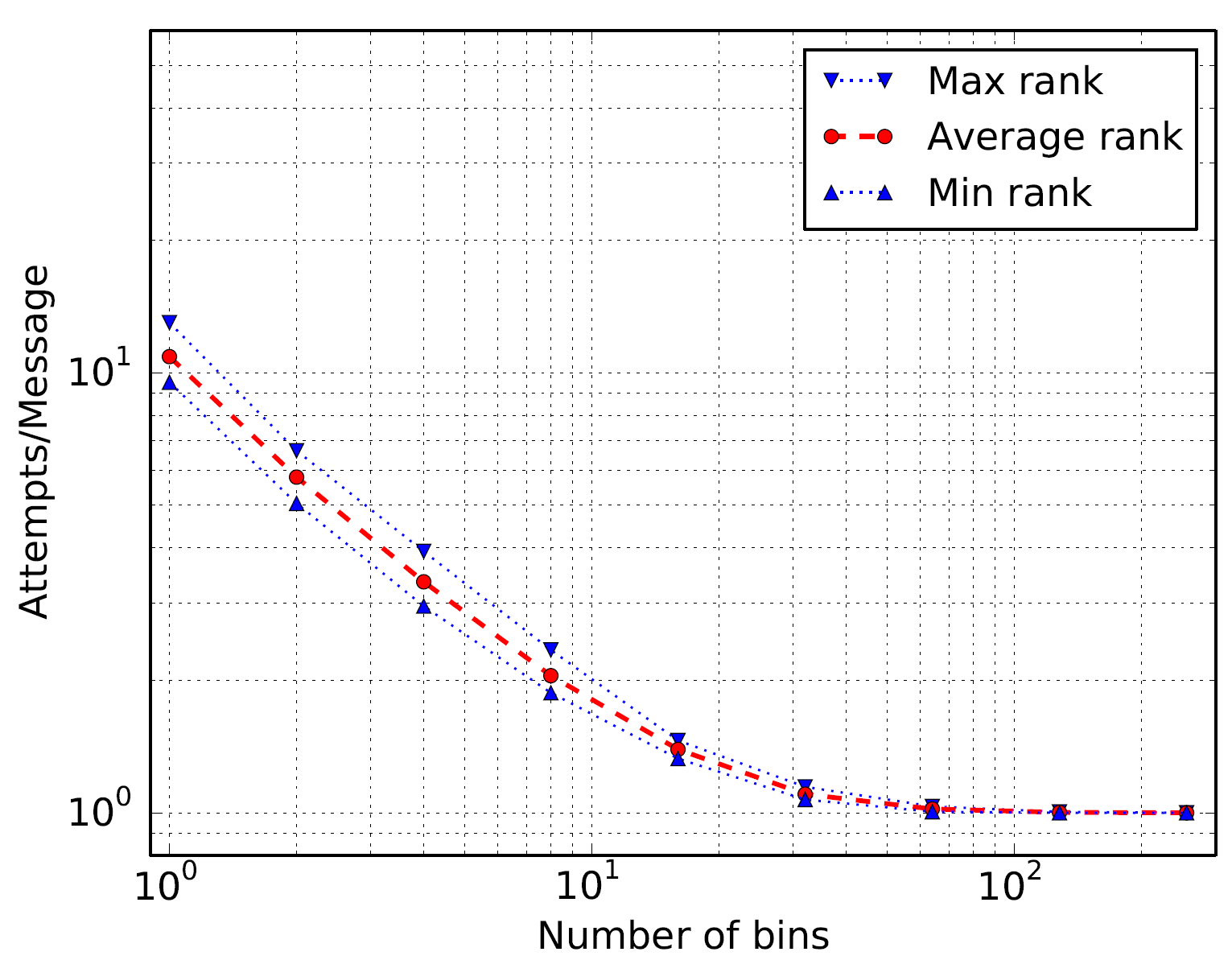
Given its ubiquity, MPI performance is of critical importance to the worldwide scientific and commercial HPC communities. With their approach, the authors have significantly improved the performance of a wide-class of MPI applications. One example is FDS, which achieved an overall speedup of 3.5x*. Such improvements – especially those that do not require application modifications – are significant and according to the ISC 2016 research papers committee, worthy of the Hans Meuer Award.
Rob Farber is a global technology consultant and author with an extensive background in scientific and commercial HPC plus a long history of working with national labs and corporations. He can be reached at info@techenablement.com.
* http://www.intel.com/performance.


MPI on Neuromorphic Hardware Shows Greater Promise
While there are not many neuromorphic hardware makers, those on the market (or in the research device sphere) are still looking for ways to run more mainstream workloads. The architecture is aligned with low power consumption and high computational efficiency, but mapping generalizable, high-value graph-driven problems to these devices is …

Rethinking MPI for GPU Accelerated Supercomputers
In the accelerated era of exascale supercomputing, MPI is being pushed to its logical limits. No matter how entrenched it has become over the last two decades, it might be time to rethink programming for increasingly large, heterogenous systems. Every field has its burdens newcomers must bear and for HPC …

The State of MPI for Future Exascale Systems
A working group formed on behalf of the Exascale Computing Project (ECP) in the U.S. has taken an in-depth look at how the message passing interface (MPI) is being used in existing HPC systems with an eye on how these use cases might evolve with ever-larger systems. The team, comprised …
wow sounds interesting – what do one has to do to make use of it?
e.g. as a typical ansys user with a small cluster?
=>
do one only has to change the MPI platform used? If so will there be an updated intel one soon?
or do one need new driver for connectx-cards to be installed?
or do one need new firmware for connectx-cards and switches used?