

Intel has been perfectly honest about the fact that certain technologies it is putting forward are being driven by hyperscalers and cloud builders. The company’s $16.7 billion acquisition is being driven by these customers, who expect to deploy these hardware-software hybrids to accelerate their workloads. Ditto for the Xeon D processor, which Intel launched last March after substantial input from social network juggernaut Facebook.
The Xeon D is Intel’s first stab at a server-class system on chip design that was created by the chip giant explicitly to keep server-class 64-bit ARM chips out of the datacenter. So far, this strategy seems to be working. Intel expanded the Xeon D product line last November, and in February this year it quietly added more SKUs to the Xeon D line aimed at storage and networking jobs. It is one of these variants of the Xeon D that Facebook is tweaking further and deploying in its “Yosemite” quad-node microserver, a design that it revealed at the Open Compute Summit last year, that it has rolled out into production, and that it talked a lot more about at this year’s summit.
Every argument that Facebook made for choosing the Xeon D single-socket server node over the standard two-socket Xeon E5 system is an argument for how an ARM server chip might also supplant a pair of Xeon E5 chips. Whether or not the ARM chips from Applied Micro, Cavium, AMD, Broadcom, and Qualcomm can match up against the Xeon D remains to be seen, but the Xeon D is actually blazing the trail while at the same time defending against the ARM insurgency.
Software Drives Hardware
The lesson from Facebook is that the choice of the processor and the system design that wraps around it is really driven by the software, not the other way around. The good news is that so many companies are pushing and pulling Intel in so many directions that it has never had such a diverse set of processors in its history, so the odds that most enterprises can find the right chip are much higher than they were a decade ago. There are Atom, Xeon D, Xeon E3, Xeon E5, and Xeon E7 processors that span a wide range of core counts, memory sizes and bandwidths, clock speeds, and price points, and then a slew of “off roadmap” processors that are customized with different thermals, clock speeds, and sometimes actual features that companies pay for explicitly.
In a blog post concurrent with the announcement of the use of a custom Xeon D chip by Facebook in its Yosemite server, Facebook engineers Vijay Rao and Edwin Smith said that the company had been using two-socket servers from Intel for more than five generations of its servers, but starting a few years back it noticed that the performance was not scaling across two socket machines with ever more cores and ever more heat generated. (The blog also said that the current “Haswell” Xeon E5 chips used in Facebook’s “Leopard” two socket servers were based on a 14 nanometer process, but this is not true. The Haswells are based on 22 nanometer processes, and the “Broadwell” chips, of which the Xeon D from last year is an example and which will be coming out in Xeon E5 and Xeon E7 variants soon, are using the 14 nanometer process.) The point is, Facebook had to keep walking up the power envelope to hit its increasing performance targets, starting at 95 watt parts and then 115 watt parts and finally 120 watt and 135 watt parts. This is a big deal when Facebook has the total power draw in an Open Rack capped at 11 kilowatts. To stay within the power envelope, it has to give up performance.
So, in true hyperscale fashion, Facebook worked with Intel to strip down a Xeon E5 to create a much better single-socket server processor than the Xeon E3, which has too few cores and too little memory bandwidth to meet the performance goals of the Facebook PHP and Hack applications and the HipHop Virtual Machine (HHVM) that runs that code. By going to single-socket servers – which Intel itself is doing for the massive electronic design automation clusters it uses to create and validate processor designs – Facebook and Intel could strip out the QuickPath Interconnect that links multiple processors together and get rid of some latency as well as a piece of circuitry that generates heat, too. The core count on the Xeon D had to be doubled up to 16 because the Facebook stack is more sensitive to compute and memory bandwidth than memory capacity. This is why the Leopard Xeon E5 machines previously used to run the web application layer at Facebook had only 32 GB of main memory spanning across two sockets with a total of 24 cores. By shifting to single sockets based on the custom Xeon D-1581, Facebook can put 32 GB on each socket, which is a 50 percent increase in memory per core, which is good, but more importantly, that memory is all very close to the Xeon D cores.
The Facebook engineers explained the problem thus: “HHVM uses a just-in-time compilation approach to achieve superior performance while maintaining the development flexibility that PHP provides. At a high level, this workload is simultaneously latency-sensitive and throughput-bound. Each web server needs to respond to a given user request quickly as well as serve requests from multiple users in parallel. In CPU terms, we require good single-thread performance and excellent throughput with a large number of concurrent threads. We have architected this workload so that we can parallelize the requests using PHP’s stateless execution model. There isn’t much interaction between requests on a given web server, allowing us to efficiently scale out across a large number of machines. However, because we have a large code base and because each request accesses a large amount of data, the workload tends to be memory-bandwidth-bound and not memory-capacity-bound. The code footprint is large enough that we see pressure on the front end of the CPU (fetching and decoding instructions). This necessitates careful attention to the design of the caches in the processor. Frequent instruction misses in the l-cache result in front-end stalls, which affect latency and instructions executed per second.”
Using the Leopard two-socket servers, Facebook could pick Xeon E5 processors with 120 watt thermal design points, and it could put 30 servers in a rack for a total of 60 processors and still stay in that 11 kilowatt rack envelope. (You can see the various Facebook racks and their configurations in this story we posted from the Open Compute Summit.) Facebook used 12-core Xeon E5 processors.
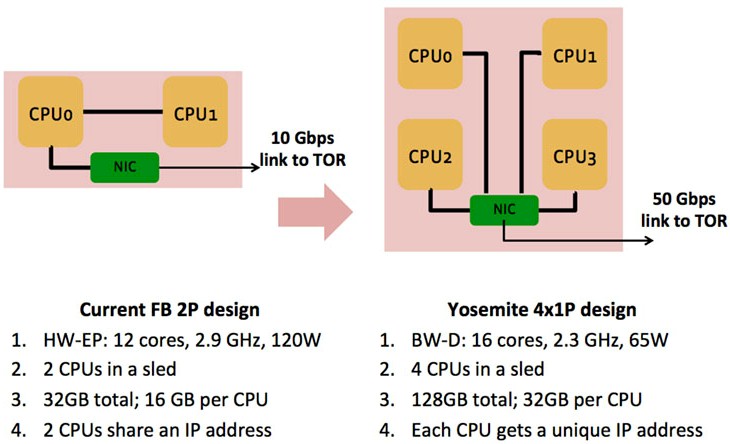
So, if you do the math, Facebook could get 720 cores in a rack to run the web tier using the Leopard machines. The two processors had to share a single IP address on the Facebook network, and data had to be transported across that QPI bus because half the time it was on one socket and half the time on the other. With the Yosemite design, Facebook is putting four single socket nodes, each with four memory slots, into an Open Compute sled that is the same size as the Leopard sled. So the core count per sled rises to 64 cores across four nodes, which works out to 1,920 cores per rack that still fit into that 11 kilowatt envelope. (Obviously, with the eight-core Xeon D processors from last year, the math is not all that attractive, with only 920 cores per rack.)
The elegant part of this Yosemite design is that rather than having processors talk locally over the QPI bus and its shared memory, the network interface on the Yosemite card (which is made by Mellanox Technologies) has a baby switch in it that can allow the four nodes within the Yosemite enclosure to share data without going out to the top of rack switch. It is like a poor man’s QPI that is not necessary for the full addressability of each socket to its own main memory. Basically, Facebook has replaced NUMA on a pair of processors with a four-processor baby cluster that is then further clustered by the top of rack switches.
To get the performance of the Xeon D up, Facebook and Intel not only had to double the cores to 16 per socket, but also had to crank the clocks and thermals up, from 1.3 GHz base with the Xeon Ds to 2.3 GHz sustained overclocking and from 45 watts with the regular parts to 65 watts for the Facebook Xeon D-1581 part. Dropping the clock speed down on the Xeon D means the performance is not high enough to compete well against the Xeon E5. Still, the performance of the Xeon D chip running HHVM and its PHP and Hack code ends up being a little lower than for a single Xeon E5 processor, but the fact that you can cram twice as many of them into an Open Rack (120 nodes versus 60 nodes) makes up for that shortfall.
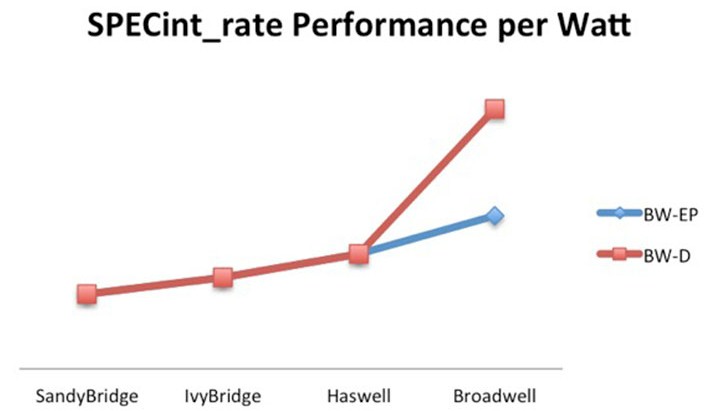
Jay Parikh, vice president of engineering at Facebook, said in his keynote that the Yosemite servers using the custom Xeon D processors delivered 40 percent better performance per watt than the Leopards using the Xeon E5 v3 processors. The chart above was plotted by Facebook and shows the SPECint_rate performance of the chips used by Facebook. (The chart should be labeled Xeon E5, not BW-EP, and Xeon D, and the Sandy Bridge to Ivy Bridge to Haswell segments should be in blue, not red.) It is important to note that this is comparing the performance per watt of a single Xeon D node against a two-socket Xeon E5 node.
“This resulted in a significant performance improvement and got us off the flattening generation-over-generation performance improvement trajectory that we have been on for the past five server generations,” wrote the Facebook engineers.
They went on to say that they would want more than two memory channels per socket on future Xeon D processors, even though two channels and four memory sticks is fine for now. Facebook is also working with Intel to create partitioning for L3 cache on the Xeon D processor so they can cache hot instructions and data in L3 and feed it directly into the L2 caches and the L1 instruction and data caches on the cores.
What Facebook did not talk about was the difference in price for the Leopard and Yosemite servers, and therefore the bang for the buck they offer. So you can make your own decisions, here is an updated Xeon D table, including the Facebook SKU and our estimation of what they cost:
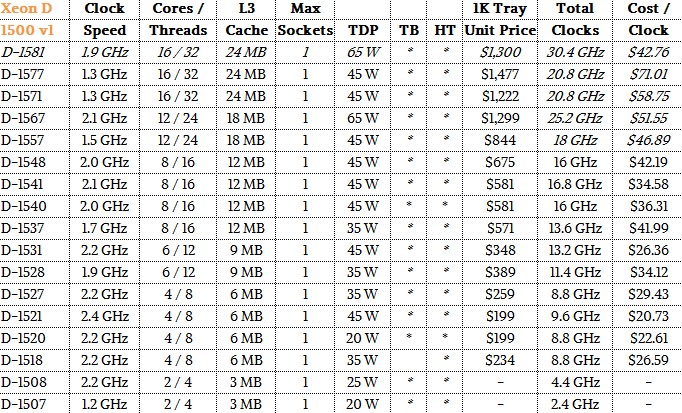
And here is a sampling of the low-voltage, low power Broadwell Xeon E3 v4 and Haswell Xeon E5 v3 processors that most closely resemble them:
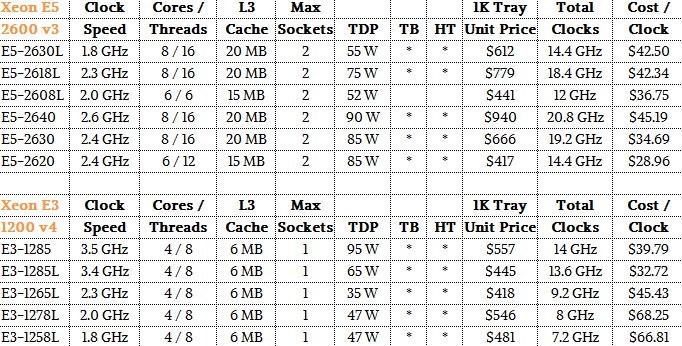
We realize that all clocks are not created equally and that the above price/performance is an oversimplification. But we have to start somewhere. But let’s take a stab at trying to figure out the bang for the buck of the compute for actual Facebook web workload as supported by the Leopard and Yosemite servers.
For the Leopard machine, based on what Facebook said about its core count and thermals, it looks like it used the Xeon E5-2670 v3, which runs at 2.3 GHz and has 30 MB of L3 cache. It costs $1,589 each when bought in 1,000-unit trays from Intel. So call it $3,178 for the processing. Assume that the server had four 8 GB memory sticks, which comes to maybe $250. The server node also has a 500 GB disk, which might cost around $100. Toss in a multiport network card for maybe $250, plus the cost of the bent metal (very little of that) and maybe the Leopard server has a unit cost of $3,900 at list price.
The Xeon D-1581 probably costs around $1,300 in 1,000-unit trays, based on the other prices for Xeon D chips. The 32 GB of memory would cost about the same $250, and the portion of the two-port shared 50 Gb/sec networking card on the Yosemite node would probably cost $125 or so, and the 500 GB SATA disk drive would be the same $100 as with the Leopard. Add that up, and you are talking something like $2,000 per node. (The Yosemite backplane has to be added in.)
If you do the math on that, working backwards, with a 40 percent performance per watt boost, that means the Yosemite node has about 65 percent the performance of the Leopard node running the Facebook web workload. At the prices estimated above, the Yosemite node is about 22 percent less expensive than the Leopard node, which is not all that great. But, oh but, you can put four of the Yosemite nodes into the same space as a single Leopard server, and that increases the core count per rack by 167 percent and the aggregate performance by 164 percent, based on our estimates.
This is precisely the kind of math that ARM server chip makers need to demonstrate to take on web workloads. And we suspect that ARM chip makers are getting ready to start making such comparisons. If they don’t, they won’t be able to compete against Intel with the Xeon E5 or the Xeon D. The math has to work if you expect companies to jump instruction sets, and we would argue that there has to an even larger price incentive for ARM chips until they become more established in servers and storage.


Intel Let The Chips Fall Where They Might
This day always comes. It is the nature of monopoly and hubris. It came for IBM. It came for Microsoft, and it is coming for Facebook. It will come for Google and, even though it is hard to believe, it will come for Amazon. And it is most assuredly coming …

Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …
HPC In 2020: Compute Engine Diversity Gets Real
The choice of processors available for high performance computing has been on growing for a number of years. There are no less than three major types of CPUs available for HPC duty, including X86, Arm, and Power architectures with more than a half dozen credible suppliers in total, along with …
Engaged in competition assessment at the intersection of Intel Universe and ARM cluster in excess of two decades, with five year’s following to understand the server category, primarily the competitive and channel aspects of product commercialization my comments.
I’m not sure it’s fair to say that Xeon D shows how ARM can beat Intel, unless of course that is an observation concerning Intel the fast follower that may also be grabbing for some prototype technology catch up. Who is to say that an Intel FPGA implemented solution today, won’t be an Intel foundry ASIC solution tomorrow?
Platform incorporation of accelerators is well established, as is massive multi core primarily to lower bridge power, and as the author states to increase system or rack density. I learned here FB OCP has rack power capped at 11 kW however have been informed by FC architects, including at OCP this last week, that average is 4.5 so an even tighter power envelope in which to work.
On FPGA’s in platform everyone will have them and everyone is experimenting with NFV configurability in the SDN managed world. Known uses including demonstrated at OCP and Open Server Summit prior and again this year are from Microsoft, demonstrating encryption and CODEC where security algorithms and decompression / compression are mainstays of ASIC blocks including in SOCs from ARM providers now and for some time. I’m not sure what an FPGA can add in the area of standard’s processing other than a system cost, power and performance deficit?
The other demonstration by Microsoft is ordering a search string after the call has delivered a somewhat less structured meta-table. One question concerns the configurability of that FPGA to perform that final sort, and what kind of sorts, and whether the FPGA has sufficient gates to address multiple variations.
Another known use is in Storage Servers, where FPGAs perform a task they’ve always performed that is managing the index of a look up table. So now we have three uses; standard acceleration that may not be as standard in an evolving NFV world, final ordering and look up.
There are two other uses that are not as currently visible. Both are related but can be put to different uses. Both are meant to deliver a processing solution through a time of evolving Open X standards thus meaning to prototype which FPGAs have always found use, there after incorporated into a more cost efficient ASIC implementation.
With FPGA gate counts exponentially increasing and their market cycles accelerating and compressing some, on the other hand, have declared the ASICs demise. Moving to the highly parallel world of mesh processing over fabric why not?
In one FB related example an intelligent NIC parses desired data from a packet and sends that off to the FPGA for co-processing or preprocessing or some parallel operation? In the more mature example FPGA configures around tasks that are many examples of data analytics managing virtual instances of virtual program operation amidst the memory partitions of large flash arrays.
On those Intel Xeon D 1K prices, I suspect minimally a 50% discount can be applied to the prototype 8 core + FPGA version. And a 35% discount can be applied to the 16 core versions on FB and other cloud player total procurements reducing the author’s cost / clock proportionately.
Relying on Intel price models assessing the only known shipping Xeon D 1520 4C, 1541 8C and here including the lower frequency 1571 16C for this calculation. On the average $1K weighed split of all three; $2002 $1K / 1.65 or a 35% discount gets the purchaser one 1571 server sled, one 1540 storage server and or dev platform, and one 1520 development where that specific 4C component was going for $55 on eBay that is 72% off Intel 1K for XD 4 core + FPGA.
So its likely buy one 1571 and get one eight core, and one four core, thrown into the bundle deal at $1213.33.
Mike Bruzzone, Camp Marketing
This is interesting:
“… more than two memory channels per socket on future Xeon D processors”
Anecdotally — memory channels are power hungry. LRDIMMs could provide enormous capacity over RDIMMs so it must be about performance and not just capacity.