
There has been steady evolution in the high performance computing (HPC) industry over the past twenty years, as companies have sought to increase the performance of their data centers. The traditional paradigm for building a high-performance compute cluster has been to maximize the performance from a single-node CPU and to try to scale that performance across the entire cluster. This started with the advancement from symmetric multiprocessing (SMP) architecture to compute clusters and continued with the move from single-core to multi-core processors.
While this enabled the achievement of terascale performance, and later petascale, the “CPU-centric” architecture’s system performance has essentially reached its peak in multiple areas, leading the industry to look for new ways to keep pace with the constant demand for added performance, and to pave the way to exascale. The multi-core technology that broke the performance barrier a few years ago is now the main cause of today’s performance bottleneck.
As applications are increasingly aware of distributed calculations, companies must take a holistic view of their system instead of approaching data center design as a set of connected compute nodes. The compute paradigm has changed; whereas it was previously common to assemble the highest performing building blocks and to connect them, the current model is to design a data center scale system with the entire network in mind, and to optimize the network according to an application’s end-to-end needs. Communicating with processes and accessing resources on the other side of the network has become the very core of the process itself.

Collaboration between all system devices and software to produce a well-balanced architecture across the various compute elements, networking, and data storage infrastructures is known as the Co-Design architecture. Co-Design exploits system efficiency and optimizes performance by ensuring that all components serve as co-processors in the data center, basically creating synergies between the hardware and the software, and between the different hardware elements within the data center.
In other words, the CPU-centric approach has been replaced by a new paradigm in which an intelligent network serves as a new co-processor, sharing the responsibility for handling and accelerating HPC workloads.
Multi-Core is the Performance Bottleneck of Future HPC systems
Multi-core solutions emerged as the solution for the performance bottleneck created from the inability to continue increasing the speed or frequency of the CPU. Processes running on the CPU could not be executed any faster, and the solution was parallelism – adding more cores. This, in turn, enabled the execution of more processes at the same time. As a result, a new era of co-processors emerged – solutions that include hundreds of cores – Nvidia GPGPUs, Intel Xeon Phi, FPGAs, etc. Today there is virtually no limit to the number of cores one can use; of course, each core increases the system cost, but as long as there is no cost limitation, there can be virtually unlimited process parallelism. The multicore era, and the era of a CPU-centric architecture, is the cause of today’s performance bottlenecks. While more can be executed in parallel, it was impossible to accelerate any further. Furthermore, with the exponential increase in the amount of available data and the need to analyze data faster, even in real time, it is important to find ways to work on the data as it moves, instead of waiting for the data to reach the CPU. This is the crux of the emerging era of co-design.
At the very heart of the co-design revolution is the idea that the CPU has reached its maximum performance, such that the rest of the network must be better utilized to enable additional performance gains. Implicit in this shift is the recognition that the overhead on the CPU that has been building over time as the CPU handled ever more operations, must be reduced to allow the CPU to do what it was designed for, that is, compute. As such, co-design architecture depends heavily on offloading technologies that enable the data to be worked on as it moves, and that move algorithms away from the CPU. The era of co-design will bring about a new generation of co-processors – the intelligent network.
The ability to use network devices – the adapter and the switch – as co-processors and to migrate data algorithms such that they are performed on the network devices is the key for next-generation high performance computing infrastructures. There have been overtures toward consolidating the CPU with the NIC, but this does not fall under the co-design architecture. Such consolidation maintains the old concept of a CPU-centric approach that has reached its limits.
The first set of algorithms being migrated to the network are data aggregation protocols, which enable sharing and collecting information from parallel processes, finding data in a parallel distribution, and so forth. When these algorithms are performed on the CPU today, they consume tens, or even hundreds of microseconds. By offloading these algorithms from the CPU to the intelligent network, a data center can see at least 10X performance improvement. This results in a dramatic acceleration of various HPC applications, data analytics, and searches.
A primary example of the offloading of aggregation protocols is Scalable Hierarchical Aggregation Protocol (SHArP), which was designed in collaborations between government agencies and HPC vendors. SHArP enables MPI operations (the de-facto communication framework for high-performance applications) to be executed and managed by the data center interconnect. The benefit is dramatic – it enables companies to overcome the performance bottlenecks of the old CPU-centric architecture and to achieve an order of magnitude performance increase. SHArP is an example of offloading technologies that will enable the industry to achieve the desired exascale mark within a few years.
Intelligent Network in Action
The most basic element of SHArP is the creation of aggregation trees within the data center fabric. This falls under the responsibility of the switch. Once these trees have been set, the switch can offload the aggregation protocol to the network and have it performed in a fraction of the time. Actually, in the time that it take for two processes to communicate between themselves, the switch network can complete the entire system aggregation protocol. It is important to note that the ability to program the switch network is important, and therefore SHArP was initially implemented over InfiniBand – the first and most comprehensive SDN network. But it is expected that the same technology will be introduced on SDN Ethernet switches as well in the near future.
SHArP is based on a reliable and scalable general purpose primitive, which is applicable to multiple use cases. It can perform scalable high performance MPI and SHMEM/PGAS collective offloads, such as barrier, reduce, and broadcast, and it supports multiple operations such as sum, min, max, min-loc, max-loc, OR, XOR, AND for both integer and floating-point, 32- and 64-bit. It can also be used for accelerating MapReduce applications and preventing the Incast Traffic Pattern.
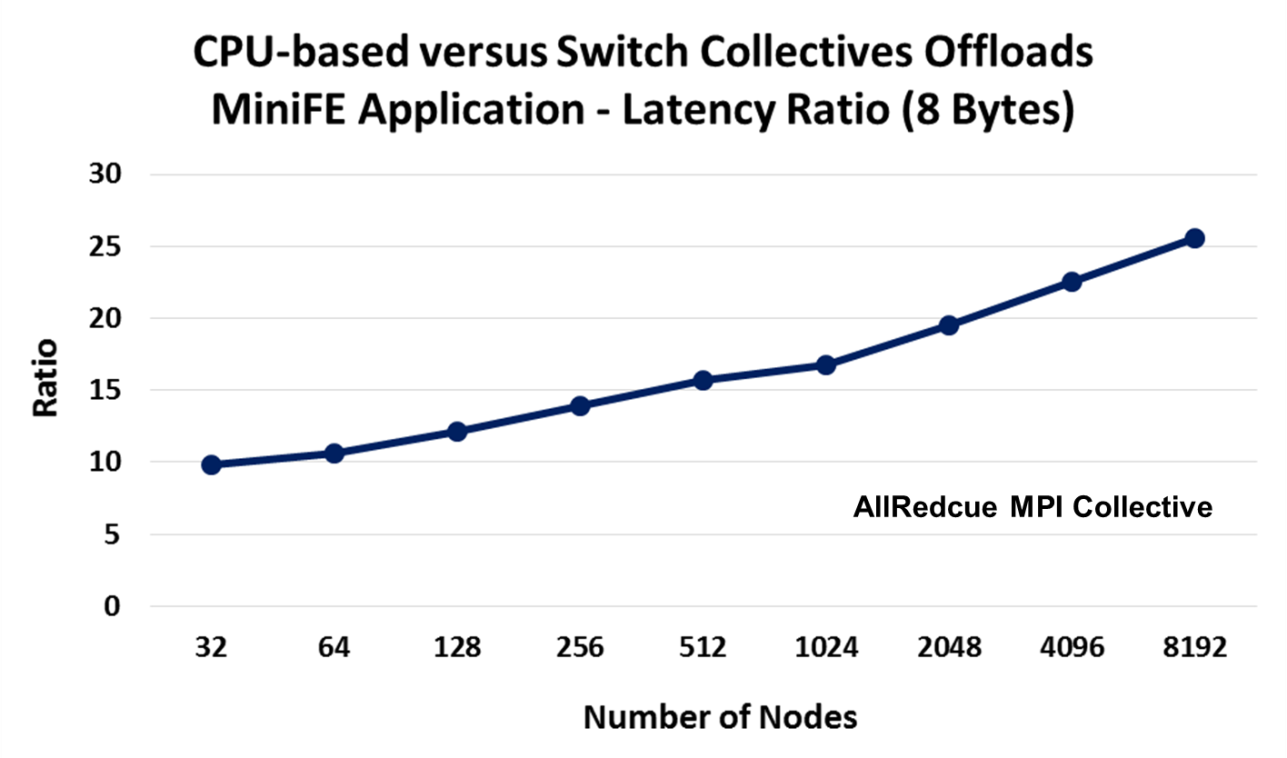
To demonstrate the benefit of SHArP collective MPI offloads, MiniFE collective communication was compared across a CPU-based cluster and across a SHArP-enabled cluster. MiniFE is a Finite Element mini-application which implements kernels that are representative of implicit finite-element applications. The results were dramatic: the latency of the mini-application collective communication dropped by ten times at 32 nodes, and even more impressively, improved even more as the cluster scaled. By the time the cluster reached 8192 nodes, the latency had improved by over 25 times.
Today’s HPC applications serve much more than just the classic high performance computing users. Whereas once HPC workloads were primarily used in the domain of government agencies and university research labs, today all applications that use data analytics rely on an HPC framework. The sheer magnitude of data that exists and must be associated into such computation can seem overwhelming, to the point that the demands on the HPC infrastructure have now surpassed the ability of CPU-centric architectures to keep up.
As such, the latest paradigm shift in the industry has led to a Co-Design approach to HPC architecture. By taking a holistic view of the system and creating synergies between the hardware and the software, as well as between the active hardware components of a data center (compute, interconnect, and storage), the performance bottlenecks of today’s compute infrastructures can be overcome. In this new approach, the interconnect becomes an intelligent part of the data center, offloading more communications and application algorithms to the network. By allowing data algorithms to be executed on the data as it moves within the data center, the interconnect has become the new co-processor. While the CPU cores are designed to support broad range of computations, the intelligent network focuses on the data movement. The network has become the computer.

Greasing The Skids To Move AI From InfiniBand To Ethernet
Just about everybody, including Nvidia, thinks that in the long run, most people running most AI training and inference workloads at any appreciable scale – hundreds to millions of datacenter devices – will want a cheaper alternative for networking AI accelerators than InfiniBand. While Nvidia has argued that InfiniBand only …
Cisco Guns For InfiniBand With Silicon One G200
It was a fortuitous coincidence that Nvidia was already working on massively parallel GPU compute engines for doing calculations in HPC simulations and models when the machine learning tipping point happened, and similarly, it was fortunate for InfiniBand that it had the advantage of high bandwidth, low latency, and remote …

Hot On The Heels Of Mellanox, Nvidia Snaps Up Cumulus Networks
Last week, when we talked to Nvidia co-founder and chief executive officer, Jensen Huang, about how the datacenter was becoming the unit of compute and in such a world networking was critical, it was obvious that acquiring Mellanox Technologies for $6.9 billion was just the beginning of the strategy that …
A CPU with an integrated fabric and 2 “assistant cores”(out of 34 total) to handle MPI overhead and run the OS already exists and has been up and running in petascale systems for a while. The graphs showing the improvement in overhead reduction are dramatic.
I’m not sure that adding another co-processor to a system is a better option than adding such functionality directly to the CPU die itself, especially in an exascale system. The necessity to minimize latency and power consumption would imply making it part of the CPU.
Of course, the CPU I am referencing is a custom SPARC only for HPC systems, and is not a typical CPU that’s also used in supercomputers.
I also wonder, don’t things like Omnipath200 take these things into account, even at a massive scale?