
These days when you talk to people in the tech industry, you will get the idea that in-memory computing solves everything. The story is that RAM has become so cheap that you can just stuff all your data in-memory and you won’t have to worry about speed any more. But it is just a myth. Companies that buy into this myth will almost certainly regret that choice in the near future.
Like most myths, there is a kernel of truth in this story. Keeping all data in-memory works brilliantly for some applications, but not all. RAM is cheaper than it used to be, and a lot of database access problems disappear when you put them in-memory.
But there’s a catch. Reading from RAM isn’t really that fast or that simple. A modern CPU has three levels of cache in front of its RAM, and the RAM on the machine is split between local and remote to each processor. Most applications today run in a distributed system where the memory might be across a network hop. This means that accessing “memory” could take anywhere between one processor cycle and hundreds of cycles. This difference is increasing over time as systems become more complex.
More importantly, even though RAM is cheap, disks are even cheaper and datasets keep getting larger. So sooner or later you’re going to come across the limits of in-memory infrastructures. As your blazingly fast in-memory application acquires more data and as you pile on more must-have features, you won’t be able to keep up just by buying more RAM.
You have got to have more than one technique for solving the technical challenges of low-latency access to fast-growing data stores. Good systems use whatever components are available to their best advantage.
Origins Of The Myth
This idea that an in-memory data infrastructure is some kind of magic bullet seems to have originated in stories about Facebook architectures. I feel a personal responsibility for correcting this idea because I was the director of engineering for the infrastructure team at Facebook that was responsible for Memcached, MySQL, Cassandra, Hive, Scribe, and so on.
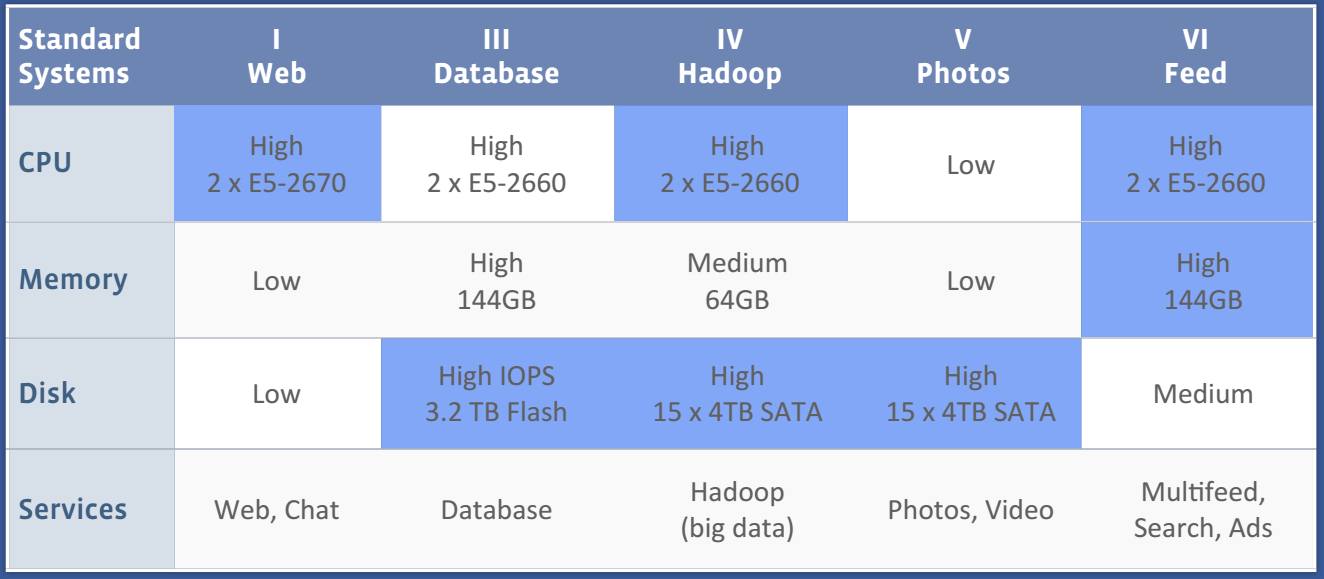
We did use a lot of in-memory infrastructure at Facebook, but we still couldn’t fit everything into RAM, so we prioritized. Every time you load your home page on Facebook there are many spinning disks seeking for you, and many reads from flash cards. This is where the vast majority of Facebook’s engineering work goes, and it is the reason the site works so well.
The glib way to say it is that in-memory does work if everything fits, and when it doesn’t fit, it really doesn’t fit and you have got a problem.
I am not at Facebook anymore, and I have had the opportunity to write some new software based on lessons learned there. Let the record show that I didn’t choose to write an “in-memory” system; I wrote one that uses RAM as effectively as possible to speed things up, but still takes advantage of everything else, from spinning disk to CPU cache. Every organization needs to know how to do this, because every application’s appetite for memory is bound to keep growing.
The glib way to say it is that in-memory does work if everything fits, and when it doesn’t fit, it really doesn’t fit and you have got a problem. So at Facebook, there were a handful of use cases that worked really well. The biggest use cases where it didn’t work is for those applications where the data just keeps getting larger over time. So if you have a little bit of information about each user, this can be put into memory and this works great. But if you have users posting more and more stuff over time, and people add comments to things, these data sets tend to grow without bound.
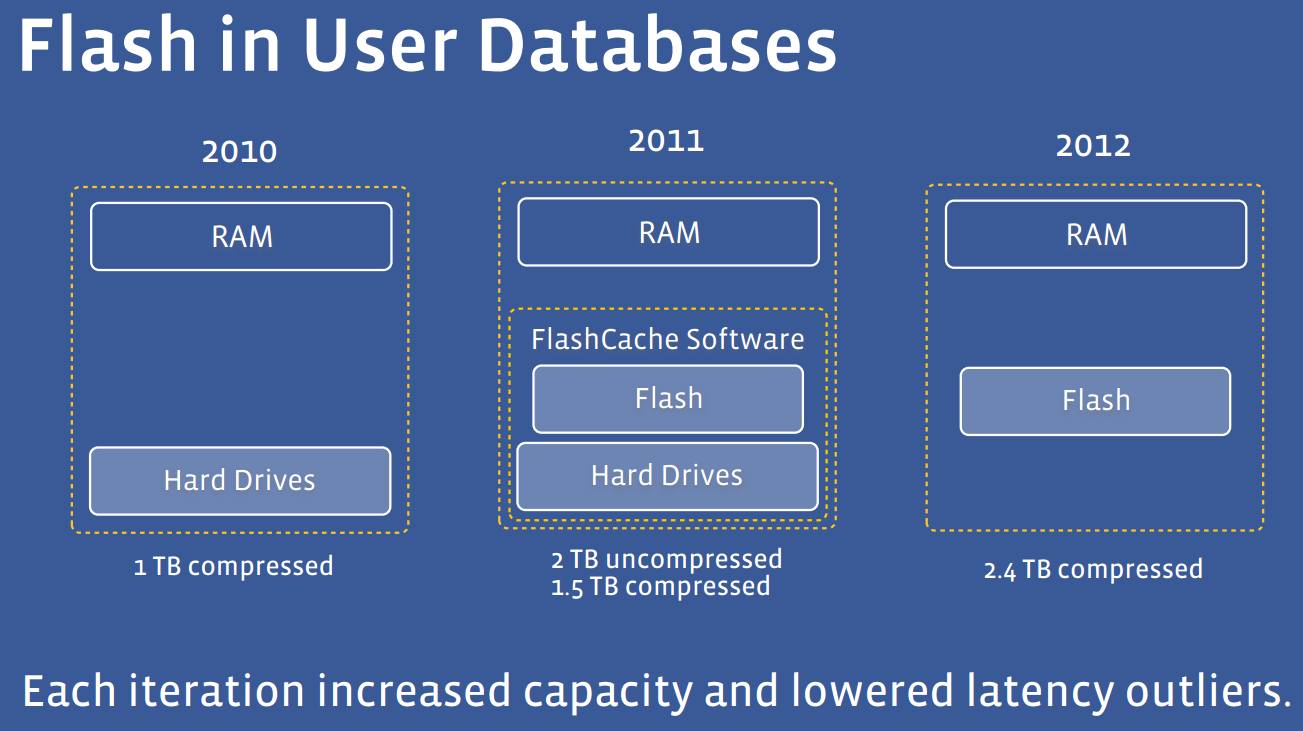
Right from the start at Facebook, everything was running on spinning disk and everything was stored in MySQL and we spent a lot of time optimizing the way we would store it in the database and how you would lay it down on disks so that the reads were not too painful when you did have to go to disk. Then, every time we added machines, we would get them with more main memory, and it was the greatest thing ever since everything goes faster. But eventually you run out of space. Later on, Facebook switched to solid state disks for MySQL, and that was again a huge improvement.

The original Facebook Newsfeed was actually done all in-memory because we only had to keep a short time window for each user, and that worked out of the gate for the first version. But then, over time, people wanted to see longer histories, or you would see long tail if they filtered to a specific kind of thing, we needed to show deeper back in to history, we had to go back and rework the Newsfeed to use disk. As soon as server flash was viable, then a lot of things went to flash. Photos are still on spinning disk because they are so huge and disks are so cheap. But the user data, which is what people think of as the Facebook data, is probably entirely on SSD now. When I left in 2012, it was mostly on flash.
There are three things that made datasets at Facebook bigger, which makes it hard to keep data all in memory. We are always adding new users, so there is always pressure on the data size. Existing users continue to generate content and that grows without bound. And the final thing, which is a little bit less obvious, is that applications always tend to get more complex. The growth that we would save per user was pretty much exponential, and so you did not want to be in a situation where you were stuck when you wanted to add a new feature but could not because you did not have enough memory for it.
The Right Kind Of Memory For Each Job
Two techniques are especially important for delivering high application performance and low latency with less reliance on RAM: compression and pipelining for improved scan speed.
Though transactional servers have been adding techniques such as block level compression, compression isn’t the first thing people think about when scaling a database. Instead, IT teams tend to spend a lot of time optimizing applications, streamlining options to try to reduce their memory requirements. For example, if there is a column description in the application that uses a lot of space for people to write their thoughts, IT might trim it down to a set number of common phrases and then refer to each one by a number. This can be an effective optimization, but it is basically a less efficient form of compression. Doing the optimization in the application takes much more time and effort than using a general compression tool.
Many IT experts are under the impression that compression and decompression burn too many CPU cycles, but as processors have become so much faster and compression algorithms have improved, there is barely any cost at all to compression. In fact, even just counting CPU cycles it can be faster to compress data before sending it on a network because the network stack uses more cycles per byte than the compression.
The other critical technique for leveraging spinning disks and SSDs is improving your ability to pipeline data out of disk. This aspect of performance is often overlooked. For example, when people talk about NoSQL databases they usually focus on how point lookups compare to traditional databases, not scans. Even worse, these comparisons are typically just for workloads that fit in memory. If you test workloads that touch disk you will find that many new databases you think of as “fast” don’t scan well at all – in fact, they usually perform worse than traditional databases. The true test is to evaluate performance when things fall out of memory because that is where it gets complicated. It is not so hard to deliver good performance on a single random read, but if you are looking at a million records, good design reveals itself.
You can more than compensate for the inherent slowness of disks or SSDs with improved pipelining. Disks are very fast at streaming data – even with spinning disks, the speed scales with Moore’s Law. The slowness is when you seek, so scattered data is what kills you. Database and filesystem software is getting better all the time at scans, and it is also something you can greatly improve with careful application design, to get data that is accessed together stored together. Scan speed can also be tricky to predict because it’s very easy for a layer of your software stack to break something up and force a seek. So testing is enormously important – when evaluating a filesystem or database there is no substitute for running lots of scan load against it and measuring how fast it really is.
RAM And Beyond
RAM is great for making things fast. But our appetite for RAM is always racing just a little ahead of our ability to pay for it or our ability to scale it up to our growing needs. As a result, choosing an exclusively in-memory solution isn’t a silver bullet – it is a limitation on growth and speed. Disks and flash and RAM each have a role to play in a well-designed system. Use compression and optimized scan speed to get faster access to the scalability of disk-based memory, and you should be able to scale your applications quickly enough to keep up with your success.
Bobby Johnson is co-founder and CTO of Interana. Previously, Johnson served as director of engineering at Facebook, where he was responsible for the infrastructure engineering team that scaled Facebook during its heaviest growth years from 2006 through 2012, taking the social media giant from a few million college users to over a billion users globally. During his tenure, his team solved difficult scaling and infrastructure challenges, adopted Hadoop, and built Hive and Cassandra; Johnson personally wrote Scribe and Haystack. He received a Bachelor’s of Science degree in Engineering and Applied Science from Caltech.

Apache Druid Takes Its Place In The Pantheon Of Databases
A decade ago, Fangjin “FJ” Yang was a software architect at startup Metamarkets, a company that was building a user-facing analytics engine that a lot of developers simultaneously could go to, click on a UI, and very quickly get answers to their questions. It was a good idea, but it …

Kubernetes Clusters Have Massive Overprovisioning Of Compute And Memory
In the ten years since Google released Kubernetes to the open source community, it has become the dominant platform for orchestrating and managing software containers and microservices, along the way muscling out competitors like Docker Swarm and Mesosphere. (Remember those? In a decade, you won’t.) Those building software stacked embraced …
Micron Gears Up For Its Potential Datacenter Memory Boom
If you don’t like gut-wrenching, hair-raising, white-knuckling boom bust cycles, then do not go into the memory business. There is a reason that Intel was driven out of it back in the 1980s, and once again in recent years as it exited the 3D XPoint ReRAM flash-ish memory business. The …
It will be interesting to see how 3DCrossPoint and Memristor memory change the calculus here. Having TBs of near DRAM read speed memory could be a game changer.