
When it comes to trading stocks, bonds, and other financial instruments, Bloomberg is usually in the middle with its eponymous terminals, which have more than 325,000 subscribers worldwide. Those terminals are backed up by three datacenters in the New York area – one in downtown Manhattan, one in the metro area, and another brand new one on the outskirts of the city that was built in the wake of Hurricane Sandy – that have an undisclosed but no doubt very large number of servers and that are linked to each other and to myriad remote datacenters with over 20,000 routers.
In fact, says Skand Gupta, technical lead and engineering manager at Bloomberg, the system that provides market data, news, and other information to traders is the biggest communication platform in the financial services industry, backed by over 3,000 software developers and engineers who create the applications that display market information to traders, and is also one of the largest private networks in the world.
Communication is the heart of trading, and in the current regulatory climate, making sure that people are making fair trades is something that all financial services firms have to ensure. Interestingly, the instant messaging service on the Bloomberg terminals is a primary means that traders talk and execute trades, and Bloomberg provides an auxiliary service, called BVault, to its terminals that archives communication of all kinds and does analytics on the data streams to make sure that traders are compliant with the law not buying and selling securities in an illegal manner.
The BVault compliance service, Gupta explained in a recent tech meetup in New York, is back-ended by thousands of servers. Over 800 companies are using it today, and it is processing more than 2200 million messages and has an archive of over 90 billion objects, which include a variety of human and machine-generated content spanning instant message, chat, email, voice data, social media feeds, and market and trading data. The complex event processing system that lies at the heart of the BVault compliance platform works in real time to try to detect any funny business and also to block certain kinds of communication that are not allowed. Such a system needs extreme low latency and is also CPU bound. The BVault service also archives two years’ worth of data so that compliance officers can do custom searches on data after the communication and trading is done if they want to ensure compliance. This part of the workload is highly distributed, with data scattered all over the nodes, and is memory bound, as search workloads tend to be, said Gupta. The BVault service also has ad-hoc analytics and reporting capabilities, and the analytics gobble up a lot of CPU and the reporting eats up a lot of I/O because the reports can pull gigabytes to terabytes of data out of the archive.
Suffice it to say, this BVault workload running on the Bloomberg clusters has a lot of choke points, and the company wants to be able to manage the workload better.
Up until a few months ago, the way Bloomberg ensured the elements of the BVault service ran on static partitions on the cluster, a practice that many companies use for precisely the same reasons that Bloomberg did. The Bloomberg techies did their best to make sure there was enough compute capacity in each of the three workloads – complex event processing, text search, and reporting and analytics – for decent performance during their peak workloads.
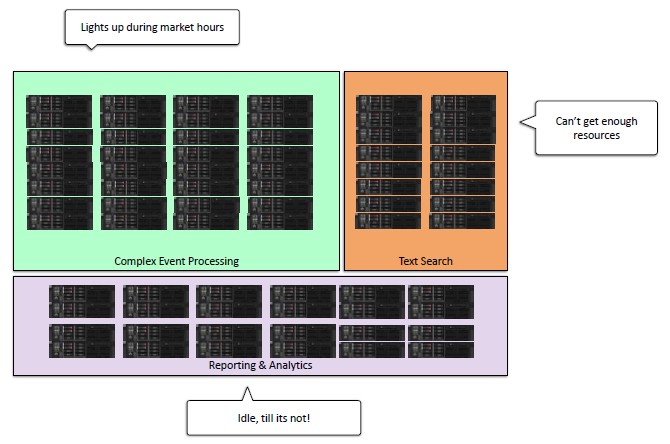
But here is the problem, and it will probably sound familiar to many of you. When the US stock markets are open, the complex event processing part of BVault “lights up like it is Christmas,” as Gupta put it, and Bloomberg is constantly adding machines to make sure it has enough capacity so the compliance algorithms do not slow down communication. On the other hand, the reporting and analytics system is just sitting there, doing nothing most of the time, until someone kicks off a complex query, and then it needs a lot of iron. Text searches are always hungry for more memory and hence more nodes, too. Resizing the static cluster by hand, which Bloomberg was doing, is an operational headache, and having unused compute resources sitting there is unacceptable.
So, in the middle of 2014, Bloomberg decided to implement the open source Mesos cluster management and hardware abstraction software on top of the BVault cluster, allowing it to dynamically allocate resources on the fly to the three parts of the BVault application stack.
As is the case with many enterprises, the new architecture for the BVault service was implemented on a new set of systems, in this case an unspecified blade server maker. Most of these blade servers were allocated to run Mesos, but a portion of them were allocated to run HDFS separately from Mesos because, as Gupta put it, “it was kind of hard to run HDFS on top of Mesos.” But he added that he was hopeful that in the future it would be possible to run HDFS just like any other kind of workload atop Mesos.

Bloomberg deploys Mesos and its applications on the cluster using Chef, and applications run in Mesos containers as opposed to bare metal or Docker containers, which are options. The company cooked up its own service discovery layer – an important part of the new BVault platform that is not part of the open source Apache Mesos but which is available in the commercial-grade Mesosphere Datacenter Operating System (DCOS) distribution – and then the Marathon application framework, the Chronos job scheduler, and the Storm real-time distributed computing fabric run on top of that. Kafka is used to aggregate and parse out streams of instant message, email, and other data to the HDFS storage and Accumulo (inspired by Google’s Bigtable) is used as a distributed key/value store. Bloomberg will be adding Spark in-memory processing to this BVault stack soon.
“Service discovery is important because with Mesos, you have no guarantee at any time where your applications are running,” Gupta explained, which makes it problematic for services – bits of applications, really – want to talk to each other as they are flitting around the system, being created and destroyed as workloads change, they have to be able to find each other. Bloomberg did not license the commercial Mesosphere DCOS – and has no plans to because it doesn’t want to pay for software licenses and support, according to Gupta – and it wanted to implement the service discovery differently from the way it has been done in DCOS. (Bloomberg’s way of handling service discovery could end up being open sourced, but Gupta made no commitments to such an action.) This service discovery layer only works for the Marathon framework at the moment, not for other frameworks running atop Mesos.
Another issue that Bloomberg had to solve for itself was managing log aggregation for all of the services that underpin BVault. Again, with applications moving around the cluster as Mesos balances workloads, how do you find the right logs to do troubleshooting when something goes wrong? Similarly, application performance statistics are important, and similarly, alerts from the applications have to be aggregated for when things do go wrong. To this end, Bloomberg created its own log shipper software, which passes all of the data from applications running on Mesos slaves up to Mesos masters. The data is all piped into Kafka, which feeds it into the combination of Elasticsearch, Log Stash, and Kibana (commonly referred to as ELK), which together allow for logs to be aggregated and searched. Application data and machine data such as compute and storage resources used are pumped into an InfluxDB database, and this is feed into the Riemann monitoring and alerting tool.
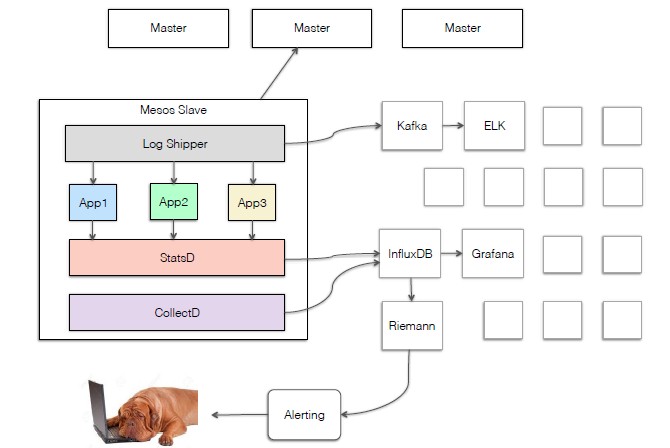
As for cobbling all of these log monitoring pieces together, Gupta said “this is not something I wanted to do, but it is something that we needed to do to make it a useful stack.” Others are working on this logging problem, he said, and added that Bloomberg might open source it.
Bloomberg has high praise for Mesos, with the caveats concerning the features it had to build itself as outlined above. “Mesos has been super stable with us, and we have not discovered any big issues with Mesos after running it for a few months now in production. All of the problems that we discovered were from the stupid things that we did. If you thinking about how mature the product is, I think it is very, very stable.”
The use of Mesos underneath the BVault service is still fairly new, being only a few months old, but Bloomberg is already seeing that allowing for the complex event processing, text search, and analytics and reporting workloads to share the cluster is cutting back on the amount of servers it needs to buy to support the expanding customer base for BVault; over time, Gupta hopes the number of machines needed to run BVault “will be significantly reduced.” How much, he cannot yet say. The static BVault cluster, on average, ran at 65 percent to 70 percent utilization, and Bloomberg thinks it will easily beat this on the Mesos setup.
This better use of capacity is one of the reasons for investing in Mesos, but not the only one. Gupta said the old static clusters were simply not a good, flexible application development and deployment environment.
Gupta shared some lessons that Bloomberg learned in building its Mesos cluster. First, the Mesos cluster is dependent on the master Zookeeper configuration management nodes in the cluster, and if you lose those, you lose the cluster. To be more specific, Gupta says that companies should set up redundant Zookeeper servers and have it so only Mesos can talk to them. Second, for your first Mesos cluster, run HDFS statically alongside Mesos, not on top of it. In Bloomberg’s experience, the two did not play well together – although Gupta again is hopeful that this will change. Third, Gupta recommends that companies run multiple Mesos clusters, not just one. This allows developers to test new updates to Mesos and the applications they create while the other cluster is running the production workloads.

Where Financial Models Meet Large Language Models
If you are a Global 20,000 company and you want to build a large language model that is specifically tuned to your business, the first thing you need is a corpus of your own textual data on which to train that LLM. And the second thing you need to do …

Mesos Borgs Google’s Kubernetes Right Back
The rivalry between Mesos, Kubernetes, and OpenStack just keeps getting more interesting, and instead of a winner take all situation, it has become more of a take what you need approach. That said, it is looking like Kubernetes is emerging as the de facto standard for container control, even though …
Building The Stack Above And Below OpenStack
It has been six years now since the “Austin” release of the OpenStack cloud controller was released by the partnership of Rackspace Hosting, which contributed its Swift object storage, and NASA, which contributed its Nova compute controller. NASA was frustrated by the open source Eucalyptus cloud controller, which was not …
This is quiet an insight! Testimony to how Apache projects find themselves in various Enterprises.