

Stanford University PhD candidate, Song Han, who works under advisor and networking pioneer, Dr. Bill Dally, responded in a most soft-spoken and thoughtful way to the question of whether the coupled software and hardware architecture he developed might change the world.
In fact, instead of answering the question directly, he pointed to the range of applications, both in the present and future, that will be driven by near real-time inference for complex deep neural networks—all a roundabout way of showing not just why what he is working toward is revolutionary, but why the missing pieces he is filling in have kept neural network-fed services at a relative constant.
There is one large barrier to that future Han considers imminent—one pushed by an existing range of neural network-driven applications powering all aspects of the consumer economy and, over time, the enterprise. And it’s less broadly technical than it is efficiency-driven. After all, considering the mode of service delivery of these applications, often lightweight, power-aware devices, how much computation can be effectively packed into the memory of such devices—and at what cost to battery life or overall power? Devices aside, these same concerns, at a grander level of scale, are even more pertinent at the datacenter where some bulk of the inference is handled.
The challenge for such applications is no longer so much one of developing neural networks capable of ever-exacting levels of accuracy, but rather, in fine tuning, pruning, and refining those trained neural nets so that they can very efficiently be processed and delivered to the end user. The capability to do so will have an immense impact on everything from the future of self-driving cars to a wider range of consumer-side applications that power “mobile first” companies like Baidu, for instance.
When Han was an intern at Google, and now as a researcher at Stanford, the challenge has been processing neural networks at scale despite the fact that the networks themselves bear far more complexity and parameterization than is actually needed for the final, accurate output. The task then, was to pare neural networks down to their most essential components to retain accuracy and push efficiency, compress these into very small datasets for inference, and run such nets against a new chip architecture that is purpose-built for the real-time inference processing of neural networks.
Han is already garnering interest from hardware makers. He left our meeting early to run to a meeting with a major chip manufacturer and has had similar interactions with Huawei Technology and others. What has piqued their interest is a small chip, called EIE, that maximizes the role of SRAM in processing the inference side of neural networks, while on the backend, a new technique (made up of old techniques) called deep compression, packs the nets down to manageable sizes for ultra-rapid and efficient processing.
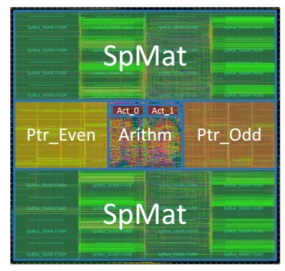
The problem with existing processing is in the access to DRAM. As Han explains, “fetching the weights from DRAM can be as much as two orders of magnitude more expensive than an ALU operation, and dominates power consumption.” Using the deep compression techniques (we will cover that in a moment), the neural network problem can be fit into on-chip SRAM. EIE then executes the inference across the compressed set with some rather stunning results.
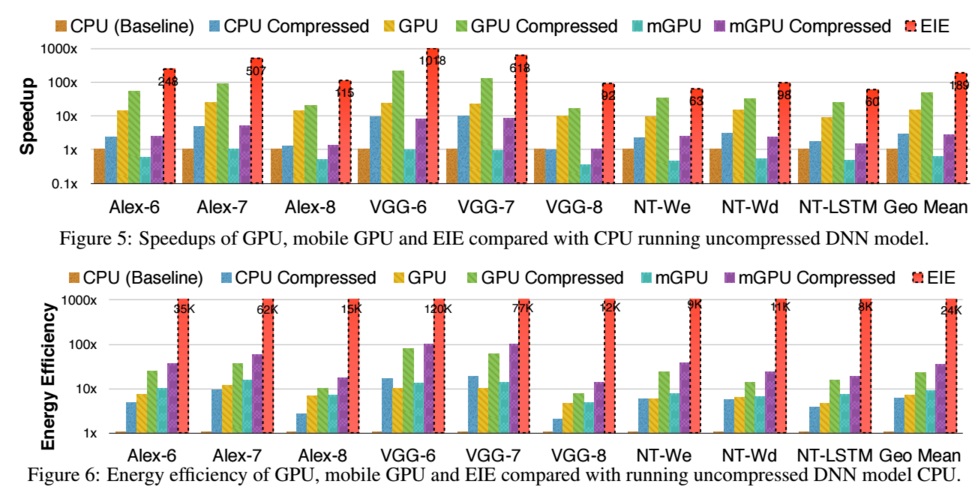
Using nine different deep neural network benchmarking suites, EIE performed inference operations anywhere (depending on the benchmark) between 13X and 189X faster over regular CPU and also GPU implementations, although this is without any compression. Still, however, consider the power envelope. As the benchmarks show, the energy efficiency is better by between 3,000X on a GPU and 24,000X on CPU.
As Han describes, this is the first accelerator for spare and weight-sharing neural networks. “Operating directly on compressed networks enables the first large neural network models to fit in SRAM, which results in far better energy savings compared to accessing from external DRAM. EIE saves 65.16 percent energy by avoiding weight reference and arithmetic as the 70 percent of activations that are zero in a typical deep learning application.”
One of the reasons EIE shows such good relative performance and energy over mobile GPU and CPU chips is also related to compression, but it’s a bit more complex than that the network is condensed. The problem is that the irregular pattern invoked by the compression hinders acceleration with standard means on CPUs and GPUs. This limitation, which may have workarounds on the part of CPU and GPU vendors, motivated “the building of an engine that can operate on a compressed network.”
The concept behind deep compression and the EIE processor is not complex on the surface. Consider, for instance, the suitable analogy of Hadoop and Spark. While Hadoop is still forced to hit the disk for data, Spark simply puts everything right into memory for rapid processing—leveraging the growing amount of memory on systems. “With deep compression and EIE, when we do the inference, we put the model directly into SRAM versus going to DRAM, which is on the order of 100X more energy-consuming.”
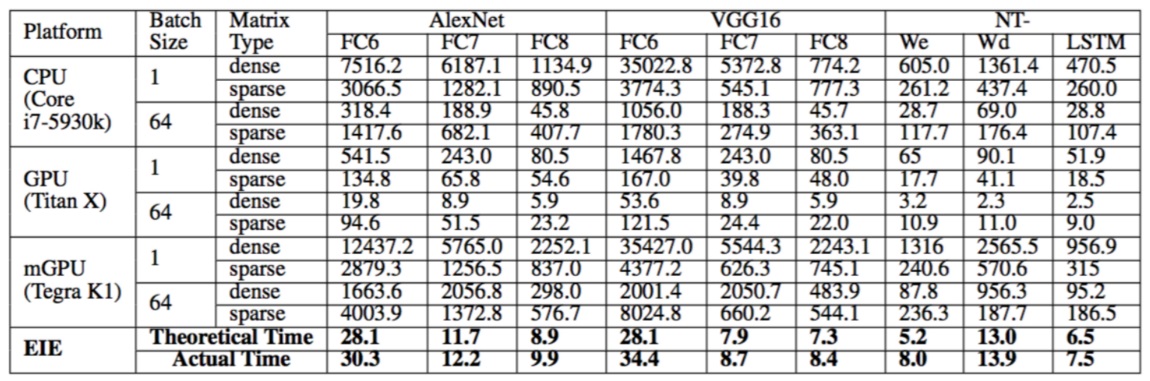
A more detailed analysis of the CPU and GPU comparison to EIE:
The first question that might come to mind is that while all of this is great, ultimately, the results must be accurate. With so much network pruning and compression, how is accuracy not lost? For one of the benchmarks, ImageNet, there was zero reduction in accuracy. Impossible, right?
Han explains this in the most “human” of terms, and thus one that relates back to neural networks quite perfectly. Synaptic pruning is a neuroscience term that refers to the process of synapse shedding that happens throughout our lifespans. Babies form a large number of neural connections, some of which are cast aside as new connections are made and learning occurs. This is not so simple as thinking that things are entirely lost in the sense of skin cells shedding to be refreshed, but there are master connections that are made that then form the basis of neural activity. That is the non-neuroscientist definition for effect and metaphor, but it is one that fits well in the context of Han’s work.
Pruning in neural networks is nothing new either. But this relentless snipping, much of which is automated in the training and retraining phases now, is a critical element in Han’s deep compression strategy. So too is the important paired aspect of trained quantization and Huffman coding. Wherein pruning simply reduces the number of connections (quite significantly in this case), quantization cuts down on the number of bits applied to each of the connections (in this work, from 32 bits to 5). On the ImageNet reference dataset, Han says this step cut down on required storage by 35X without any loss of accuracy. Huffman coding, then on the final step, further refined and reduced the number of bits needed to assign a string for inference. Again, none of these methods are new, but when coupled with the chip’s ability to assign this to cache efficiently, the potential “game changer” for on the fly neural network activity is clearer. The only potential loss point for accuracy comes at the pruning stage, Han explains, as the rest is compression after that fact. As pruning without accuracy loss (or at least at a slight reduction) has been a long-researched area in neuroscience and neural networks, this is less worrisome than the hardware efficiency.
The Larger Barrier for Efficient, Real-Time Neural Networks
As a point of future exploration, we can think about what the entirely new levels of cache to the hierarchy can mean for the future of deep neural networks. Considering the limited amount of SRAM available on most mobile devices and low-power servers, taking the same deep compression and inference approach on SRAM-laden systems with more powerful cores at the datacenter level seems the next logical step. It is not clear if this what Huawei and others are after in their meetings with Han, but it’s safe to say, if there is a more efficient route to real-time inference in a dramatically lower power envelope, the hardware community—both mobile and server manufacturers—will stand up and take notice.
Consider how much SRAM is available on-chip already. On most processors, there is at least 256KB of L2 cache with varying degrees of L3 that spans all cores (so on a Xeon E5 it’s 45 MB of L3 cache max on some variants). On a Power8, it’s 96 MB of L3 cache. The point is, the next generation with even more on-chip memory, means that if this is extended the sky is the limit for the server side of this work. Further, for a chip designed to do neural networks, it might be more suitable to have fewer cores and a lot more caches (the RAM is not as difficult as adding more cores). The memory will keep growing, neural networks will keep growing—we see the need here, yes? And it all connects back to the point we keep making here at The Next Platform–the era of general purpose systems is coming to a close. Especially with emerging workloads like this.
But the hardware, as always, is only part of the story. And in this case, not even half of it.
After all, if we’re talking about the ability for a vast, complex neural network being boiled down to its simplest components without loss of accuracy, what does that mean for neural networks themselves? If so many connections are unneeded for an accurate final result that can be more efficiently processed, why is it there to begin with?
Despite all the attention around deep neural networks and their future applications, some, Han included, are making the argument that there is a growing gap between how researchers in machine learning and practicing hardware and software engineers who implement deep neural networks think about their problems.
For the researchers, adding more parameters and more data to training models creates a more complex, richer model, but it comes at a hardware resource cost—both at the datacenter level and for an increasing number of use cases for neural networks, many of which now are focused on mobile delivery of service, at a memory and power consumption price at the end, too.
To put this into context, consider a large-scale neural network powering a service that is delivered in near real-time to a mobile device. The complexity of the neural network, both in training and executing, means that the application itself needs to grow. Many mobile applications on Baidu’s service, for example, must fit into a 100 MB envelope before the require a Wi-Fi connection or they will not make it past product managers. The goal then, is to pare down, or prune, networks to include the essential elements for the task at hand, then run the trained models on highly tuned, energy efficient hardware. This creates less battery and memory overhead for the end mobile user, and significantly cuts down on cost at the datacenter level as well.
In many ways, this seems like an obvious set of realizations and fixes. But going back to Han’s main point—that there is a disconnect in how networks are being devised versus how they now must efficiently be deployed and used—the conditions are more complex than they might seem. But with such approaches potentially hitting server and mobile devices on the horizon, we could very well see a Cambrian explosion of neural networks powering a host of new real-time applications, all without killing our batteries or putting datacenter operators in the poorhouse.
EIE has not gone into production yet but has undergone early validation of design. We will continue to update.

A New Era In High Performance Computing
Long gone are the days when high performance computing was limited solely to traditional simulation and modeling at academic and government research labs. HPC now encompasses other forms of distributed computing, including advanced data analytics and artificial intelligence. HPC systems have had to embrace new technologies, new software frameworks and …
Dell Sets Up For A Killer Spike In AI Server Sales
Back in February, Dell, the world’s largest server maker, told Wall Street that it was planning on selling and delivering $15 billion in AI servers in its fiscal 2026, when will end in early November. Sales were a little more tepid than we and many on Wall Street had expected …
What If Omni-Path Morphs Into The Best Ultra Ethernet?
UPDATED: Nvidia is a member of the Ultra Ethernet Consortium. The jury is still out on a lot of things about this exploding AI market and the re-convergence that it will have with traditional HPC systems for running simulations and models. But one of the ideas that a lot of …
The question I would have with which flavor of NN is this going to work with? From the sounds of it it seems to be like only very simple ones, ones that have no type of memory or state from previous inputs. So only CNNs.
It is supported beyond CNNs. The last 3 benchmarks are on RNN and LSTM.
Amazing