

FPGAs might be the next big thing for a growing host of workloads in high performance and enterprise computing, but for smaller companies, not to mention research institutions, the process of onboarding is not simple—or inexpensive.
From the systems themselves to the programming and compiler tools, even experimenting with FPGAs is an undertaking resource-wise. While there are efforts to lessen this load, including the addition of a richer OpenCL toolset and cloud-based FPGA offerings, the ecosystem for FPGAs is still developing, which means getting to “point A” is where some foundational work needs to be done. We have already seen a great deal of momentum for machine learning codes that can take advantage of FPGA-based systems, but despite the increased interest in FPGAs at the annual Supercomputing Conference in Austin this year, there is still relatively little information about which scientific codes might be a good fit for FPGA acceleration.
The dominant accelerator in high performance computing is the GPU, with a swell of scientific codes across a wide range of disciplines available and CUDA-ready. This type of ecosystem development for HPC has not happened to any great degree among the FPGA vendors, in part because the compute market has been a secondary focus (with storage and networking being a prime business in the past, according to Xilinx). There are other technical requirements (we’ll get to that in a moment) that have not made HPC codes well-suited to FPGAs, but a lot of that is set to change. The goal now is to offer researchers a rare chance to actually experiment with their codes using a real system—something that is hard to do “in the wild” without some serious up-front cost and expertise.
For Derek Chiou, former professor at the University of Texas at Austin and now full-timer at Microsoft on the Catapult project, this lack of research access to FPGAs is a problem—but there are efforts to bring FPGAs to the academic masses.
For instance, the Texas Advanced Computing Center (TACC), a supercomputer site that we profiled in depth here last week, has set its sights on the future of FPGAs by making the Altera Stratix V FPGA-outfitted Catapult servers available for free for researchers, assuming of course, they are willing to share the code they develop on the platform. Chiou, who started his work with FPGAs as a post doc at MIT, toiled away on router architectures at Avici Systems before becoming a professor at UT Austin, now is a liaison between TACC and Microsoft. The effort now counts several hardware partners, including both major FPGA makers, Xilinix and Altera, and has commitments for tooling from Intel, compilers from Bluespec, and a C-to-gates compiler from Impulse Accelerated Technologies. The TACC work is supported by an National Science Foundation grant and builds on work Chiou and teams did on other projects, including a program called Research Accelerator for Multiple Processors (RAMP) that examined the problems of building ultra-dense, multicore systems from FPGAs and other processors.
TACC will have an impressive array once the systems are up and running. Currently, the project is in the install phase, but Chiou says there will be 400, or perhaps slightly more, machines. They are in the process of evaluating codes for the systems now, but since this is the largest open installation of FPGA-based systems, he expects there to be great demand.
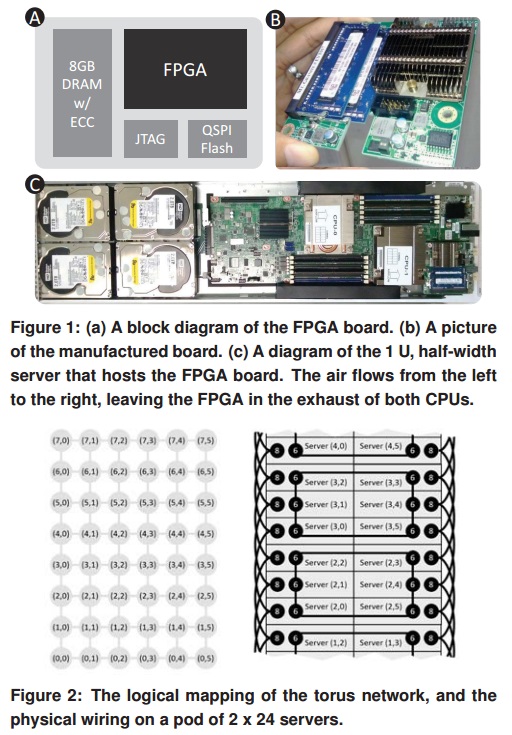 The real takeaway from the work at TACC with FPGAs will be seeing the ultimate scalability of the system across a new range of codes. The configuration chosen for TACC is a miniature version of what Microsoft implemented for its Bing search engine, which was able to significantly accelerate Bing across a cluster of 1,632 servers featuring the same Stratix V in a half-rack of 48 nodes with one single FPGA board connected via PCIe and connected to the other FPGAs via SAS cables.
The real takeaway from the work at TACC with FPGAs will be seeing the ultimate scalability of the system across a new range of codes. The configuration chosen for TACC is a miniature version of what Microsoft implemented for its Bing search engine, which was able to significantly accelerate Bing across a cluster of 1,632 servers featuring the same Stratix V in a half-rack of 48 nodes with one single FPGA board connected via PCIe and connected to the other FPGAs via SAS cables.
It will be interesting to see how many scientific codes find a fit with the FPGA systems since the Altera Stratix V does not offer native support for floating point. That is not a deal-killer since soft logic can be used as a workaround, but that is not very efficient. Once Altera rolls out its Arria 10 FPGAs, however, a new world could open for high performance computing codes since those will include hardened 32-bit floating point units. The Arria 10 has on the order of 1.5 teraflops of floating point performance, which is quite good considering the low amount of power they burn. The next generation Stratix 10 is expected to have 10 teraflops of 32-bit floating point performance. While 64-bit is the preference for many scientific and technical codes, but there Chiou says there are several codes that will hold nice nicely to 32-bit and given the performance per watt, which is better than GPUs and definitely CPUs, that tradeoff might be a consideration.
Following Chiou’s work on the Catapult project to accelerate Bing, the team noted that the big challenge ahead still lies in programmability. While he says that RTL and Verilog are common tools for his work, efforts being made in Scala and OpenCL represent a path forward for wider adoption. “Longer term, more integrated development tools will be necessary to increase the programmability of these fabrics beyond teams of specialists working with large-scale service developers.” Within the next decade to fifteen years, bringing us to the end of Moore’s Law, however, “compilation to a combination of hardware and software will be commonplace.”
Researchers can request access to the system by sending an email to catapult-request@tacc.utexas.edu including a brief description of their software or algorithm, a summary of the problem they are trying to solve, and their institutional affiliation. TACC and Microsoft will review proposals for time allocations on the system. The most compelling applications and system research will be given an allocation and consulting services to port their applications to Catapult to make effective use of FPGA-based acceleration, all at no cost.

The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …
Once Again, Meta Buys Rather Than Builds A Supercomputer
For a company that has been so enthusiastic about designing and building its own infrastructure and datacenters, Meta Platforms, the parent company to Facebook as well as WhatsApp and Instagram and one of the champions of the metaverse virtual reality a lot of us first read about in Burning Chrome, …
Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …
Be the first to comment