

Moore’s Law might be winding down in observable ways, but that realization will not keep Intel from putting its maintenance on the front burner. It has been throwing a lot of core hours behind the engineering effort for the forthcoming 10 nanometer process, and is burning a lot of compute on solving the challenges that lie ahead on the path to 5 nanometers.
Although the company’s CEO, Brian Krzanich, has publicly stated that Moore’s Law is slowing in the wake of the company’s decision to push back availability on their ten nanometer chips by six months this summer, some at the company are fighting the idea that the continued, decades-long upticks in regular performance will end anytime soon. The key to keeping pace with Moore’s Law is working with the upcoming extreme ultraviolet technology (EUV), which will reduce the wavelength range necessary to move circuit designs onto silicon via masks, as well as a shift to 450-millimeter wafers within the next few years. As it stands now, too many hurdles with EUV stand in the way for it to push the 10 nanometer chips, but Intel is expecting this to change for future generations—including five nanometer (since they are skipping their former plans to move into full production with seven nanometer on EUV, according to TSMC’s CEO in an investor call over the summer).
It is no secret that the company is aggressively pursuing the five nanometer course, but according to Mark Bohr, Intel senior fellow in the Intel processor technology team, Moore’s Law is alive and well—and the momentum with five nanometer is a testament to that fact. “We continue to scale transistors, and each generation provides transistors that are higher performance, consume less active power, and cost less per transistor.” Bohr still strongly believes, despite the fact that Krzanich said the trajectory of production, which used to be on the order of two years, is closer to two and a half.
Bohr has seen the struggle play before. Recall that similar lithographic challenges stood in the way of Intel rolling out the 14 nanometer chips. In fact, he has seen a good part of the course of Moore’s Law from inside Intel longer than almost anyone inside the company. Bohr has been with Intel for a striking 37 years, and still sees the way forward despite the admitted host of roadblocks.
Just as Intel has done with its work on Knights Landing and from what we understand about the future Knights Hill processors, there will need to be some “tricks” to keep the Moore’s Law pony hopping—or at least looking lively. “One of several key challenges is trying to pattern ten or seven nanometer dimensions using lithography tools that have a wavelength of light of 193 nanometers. We need special tricks there. Another is that when we manufacture these scaled transistors and interconnects, some of the thin films we use are only a few atoms thick, which presents other challenges.”
At some point, the number of tricks at ever-smaller scale will come to an end, spurring a new, unseen shift toward other processor technologies, but for now, Intel is hard at work simulating the materials and lithography problems of continued shrinks. All of this comes at a significant cost across the board within Bohr’s five nanometer group, including on the computational side. As Bohr shared during this year’s annual Supercomputing Conference (SC15) in Austin last week, they are lighting up the cores on their own #99 ranked on the Top 500 November 2015 list) 833 teraflop Haswell-based HP supercomputer to continue the fight against the Moore’s Law decline.
Bohr says it takes a million CPU hours to design the photomasks to pattern the integrated circuits at scale currently. “That is the price we have to pay to pattern ten nanometer dimensions using 193 nanometer light.
Intel, who is now the prime contractor on one of the largest upcoming supercomputers known (the 2018 “Aurora” system) is coming to first-hand terms with the value of having large-scale simulation and modeling resources at hand. During the Supercomputing Conference, he shared a chart showing how his division has had to scale its infrastructure to support the design and implementation of new process techniques, noting that having a supercomputer on hand allows Intel to keep exploring a wider range of future device options using different materials and structures that would be impossible with just lab experiments—the dominant method before 2005 as seen below.
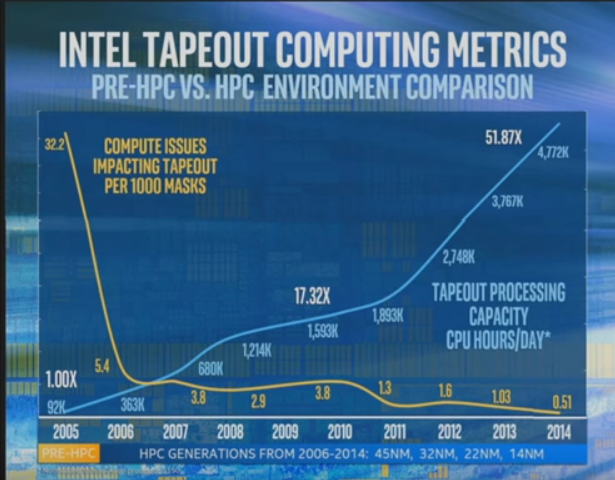
The blue line shows how Intel has increased compute power for future process design research since 2005. From that starting point until now, there has been a 50X increase. A slightly more nebulous line shows the corresponding increase in reliability, with failure rates dropping significantly, presumably as Intel has beefed up its own stack for HPC applications on partner iron.
Back in summer, 2015, the company’s Bill Holt, VP and GM of the Technology and Manufacturing group told investors that although the 14-nanometer process was behind schedule and projections at first, it has caught up with expectations, but Intel is keenly aware that the 22-nanometer process struck a sweet spot. “Our 22-nanometer technology is the highest yielding technology we’ve ever had. The bar that we’re trying to catch up to there is very high. That’s essential, because if you’re to get cost reduction, you have to match those other parameters of your previous generation.”
“We’ll always strive to get Moore’s Law back in two years,” said Brian Krzanich during Intel’s Q2 investor call in 2015. “And we’ll take a look at the maturity of EUV and the maturity of the material science changes that are occurring, the complexity of the product roadmap that we’re adding, ad make that adjustment out in the future.”

Why TSMC Did A $100 Billion Deal With Trump On US Chip Manufacturing
All presidents of these United States have the bully pulpit from which to lecture the American people and, for the past century, the rest of the world about how the global economy and culture should work. Donald Trump has certainly used this pulpit in his first and now second terms …
Intel: I Was Lostry, But Now I Am Foundry
Pat Gelsinger, current chief executive officer at Intel and formerly the head of its Data Center Group as well as its chief technology officer, famously invented the tick-tock method of chip launches to bring some order and reason to the way the world’s largest chip maker – as it was …
More CPU Cores Isn’t Always Better, Especially In HPC
If a few cores are good, then a lot of cores ought to be better. But when it comes to HPC this isn’t always the case, despite what the Top500 ranking – which is stacked with 64-core Epycs – would lead you to believe. Speaking with executives at Atos and …
The economic wall of continued process shrinks will be hit long before the wall dictated by physics. Moore’s Law/observation has an economic component to the process as well as that of the physical laws. Even with Intel’s spending there will be a continued shrinking of, if not outright reversal, of the economies of scale in going smaller. 22nm was the sweet spot, and the marginal returns of going beyond will begin to become marginal losses and other methods will have to be employed to enable more processing to be done.
AMD did a nice bit of engineering with Carrizo at 28nm in getting extra space savings in the CPU core’s area required without a process node shrink. AMD instead of using the nominal low density CPU high performance design libraries that are normally used for CPU core layouts had chosen to take its high density lower performance GPU style design layout libraries and apply them to a CPU’s layout.
Carrizo was by design a low power part and was by design not meant to be clocked as high as a desktop part. So why not design the CPU core using the GPU style layout densities, because even Intel clocks its CPU cores for its mobile SKUs lower to meet power/thermal envelops. So AMD in deciding that its Carrizo based CPU SKUs were never going to be used in higher performing desktop systems decided to take advantage of its GPU design layout IP for GPUs that are designed to have massive parallel processing resources running at lower clocks to provide better effective processing through massive parallelism. AMD shaved of about a third of the die space required to accommodate a Carrizo core leaving more space for GPU/Other features on its Carrizo APU die.
The nice return from an engineering standpoint for AMD, is that from now on for low power mobile SKU’s CPU cores, AMD can at 14nm/16nm still apply the high density GPU style design layout libraries to get that extra third on top of the die shrink savings for low power x86, and custom ARM core based APUs. AMD will be able to intentionally engineer CPU cores to take up less area without a die shrink and put the space saved to better use with more GPU resources, and AMD’s GPUs/cores are being designed to take on more general purpose compute tasks from the CPU as its version of HSA begins to produce tangible returns for all types of processing workloads accelerated on the GPU’s ACE units.
Intel is going to have to look into doing the same style CPU core layouts on its low power mobile x86 variants in addition to doing more HSA style compute on its GPU cores. If the CPU core war starts again between AMD and Intel, AMD will have an advantage in using its GPU design layout IP for mobile CPU core layout and will be able to put more CPU cores per unit of die area relative to Intel once the process nodes used by Intel and AMD become relatively equal at 14nm. AMD will also have the advantage of having its own custom RISC ARMv8A running micro-architecture with a fat wider order superscalar Apple A7 style custom ARM core design, which AMD can apply the high density design libraries to! So AMD has the potential of being able to get even more custom ARM cores into an even smaller space! Custom AMD ARMV8A ISA running cores that, like Apple’s A7 Cyclone cores, have more in common with Intel’s “i” series of Haswell SKUs in execution resources that any of ARM Holding’s reference design ARM cores.
Intel will have to layout its future x86 mobile SKUs with that in mind. The x86 CISC designs will need more die area to implement for both Intel and AMD, but AMD will also have its own custom RISC ARM cores in the future, and RISC ISAs can be implemented with less transistors than CISC ISAs. Intel has always had troubles competing with the ARM cores in the power usage metric, even with the ARM cores produced on the 28nm process node. Intel is now having to compete with the more robust versions of the custom ARM cores fabricated at 16nm, and 14nm, while AMD will be fielding custom ARMv8A ISA cores of its own. It’s more about getting more processing power in less area, in addition to doubling transistor counts on a die, and that includes RISC ISAs in addition to CISC ISAs and using the best ISA for the intended workloads.