

The future of hyperscale datacenter workloads is becoming clearer and as that picture emerges, if one thing is clear, it is that the content is heavily driven by a wealth of non-text content—much of it streamed in for processing and analysis from an ever-growing number of users of gaming, social network, and other web-based services.
At the center of making that content and the additional services that are piled on top to value (either to the user or for ad or other purposes) are deep neural networks. And while accelerating the pace of training the models to power image, speech, and video recognition and analysis at scale has been at the heart of GPU maker. Nvidia’s, approach outside of its HPC-oriented Tesla business, the model execution and other elements of video and image processing at scale has ridden the CPU workhorse almost exclusively.
Over the last eighteen months, GPU maker Nvidia has stepped up its presence in deep learning and machine learning by touting graphics-based acceleration as the ticket to executing ultra-fast neural networks and machine learning workloads. However, as we have noted in several pieces of the course of the year across multiple interviews to understand the hardware requirements for the deep learning workflow, GPUs can be of significant value, but only for the compute-intensive process of training models. When it comes to running those trained sets, it’s back to standard CPU clusters in most cases. Or, perhaps most worrisome for Nvidia, those are also an emerging fit for FPGAs—which have been at the center of a great number of conversations this year in terms of their reach for future applications, especially after the $64 billion Intel acquisition of FPGA maker, Altera.
To counter these paradigms and find more stable footing along the entire lifecycle of the hyperscale application timeline, Nvidia rolled out via a pair of new Maxwell-based GPUs that can accelerate both the training and the execution of machine learning workloads, particularly in areas like facial recognition, video analysis, and image classification. These are the places where neural networks and deep learning techniques are finding, after so many years, a much wider fit at webscale companies like Google, Facebook, and others. The most powerful of the two, the new Tesla M40, is aimed at more powerful deep learning inference (the actual execution of the trained models) and its smaller companion, the Tesla M4, which is an ultra low-power high-throughput acceleration engine are the keys to Nvidia’s next step at scaling beyond their limitations in the hyperscale datacenter, particularly in terms of next-generation deep learning and machine learning algorithms. We have a deep-dive into the hardware specs and some handy comparisons of other GPU platforms here.
But all the newest, fastest GPU acceleration cards on the planet are useless without a vibrant market that is interested in (and ready for) a change to how deep learning workloads are handled—and whether there are enough of them to warrant the investment in a new line of processors. As Nvidia’s VP of Accelerated Computing, Ian Buck, tells The Next Platform, the market opportunities are clear—and there is no end in sight to the needs for accelerated processing of some of the fastest-growing data types on the planet. We are still at the beginning of the next boom in hyperscale applications, which are driven in large part by video, speech, and image processing—in real time and aided by existing and still-emerging deep neural networks and other machine learning approaches.
“There are, literally, exabytes of content being produced daily. Think about services like company Twitter bought, Periscope, which lets users share fifteen second video clips. With ten million users each day, there are more than forty years of video uploaded daily. Or Twitch, which has over a million broadcasters and a user base that watches on average 1.5 hours per day. Or Baidu with its six billion queries per day, ten percent of which are speech—a number that the company’s Andrew Ng says will grow up to 50% for both speech and image-based searches.”
According to Buck, these new content channels need an entirely new platform for processing, refining, targeting, and analyzing so much non-text content. And while these and other companies whose sole business is, at the end of the day, data, have refined their approaches to the many stages of processing and handling vast streams of data-rich content, there is a growing need for far more efficient, high performance approaches to doing so.
The next platform Nvidia is one that can combine the requirements of video transcoding, media processing, data analytics, and deep learning inference (taking the GPU beyond mere model training and into production) is captured by both the Tesla M40 and Tesla M4 processors, Buck says. As noted in the previous article detailing the M40 and M4 hardware, these are single-precision engines, which while not a fit for its existing Tesla customer base in HPC, is ripe for a range of deep leaning algorithms. The company demonstrated the M40 against the AlexNext training algorithms for the Caffee framework for 20 interactions on an M40 server with an “Ivy Bridge” host processor and was able to show training times reduced from eight days to a single day.
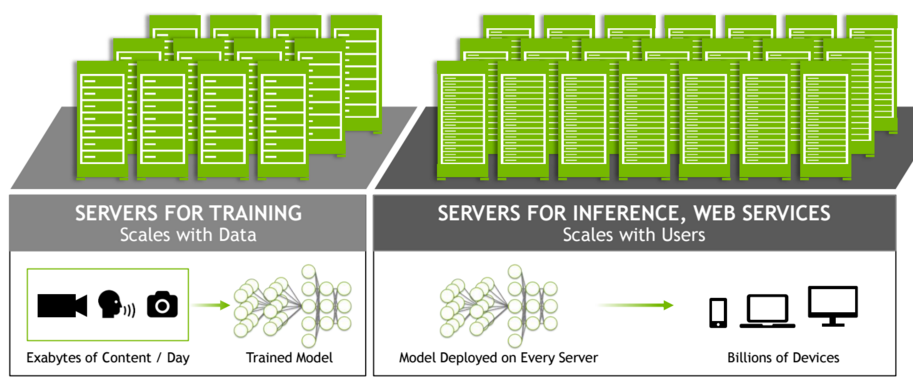
Nvidia’s vision of how these will be deployed will be with standup purpose-built servers designed for model training and stocked with between 4-8 of Tesla M40 GPUs per box with hundreds of thousands such machines powering model training. These models are then handed over to the hyperscale side with racks outfitted with the low-power M4 cards where those trained networks are deployed to understand content in real time. Ideally, Buck says, they will fit equally well for the deep learning inference side as well as handling the video and image processing. “This is the direction hyperscale datacenters are going,” he notes.
But the question is, haven’t said datacenters been swiftly heading in this direction for some time now? And if they weren’t using GPUs outside of the training process, why would they consider an overhaul now to snap the M4s into their pared-down systems that are CPU based? Buck says that Nvidia “owns the training market” already but for processing on the other end, current CPU-only boxes are stretched to the max—both in terms of capability and power consumption. “There is a big misconception that GPUs are high powered devices, which is the reason we are rolling out the M4—to show that the GPU can offer great performance but in a low power envelope and in a way that can fit into the typical server configurations in hyperscale datacenters.”
Of course, to make it a true platform, the picture isn’t complete without a software stack that can support the dual hyperscale needs of model training for neural networks and video or image processing, but also to handle the other devops requirements. In addition to pulling in the deep learning libraries that were announced this year, Nvidia is also expanding into a range of more supported tools for video and image processing, including the addition of FFmpeg and a new image compute engine to speed real-time delivery of image content.
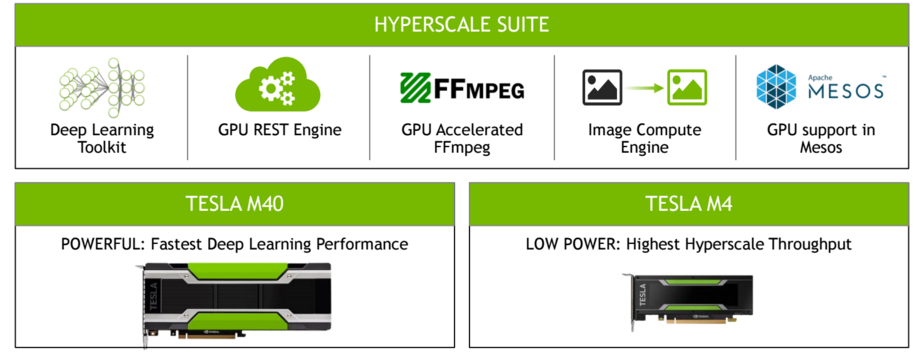
The image compute engine is built on top of another new feature, which is the GPU Rest Engine to accelerate REST_based services in hyperscale datacenters. Nvidia has also announced that it has worked with Mesosphere to provide GPU support for Mesos—an important addition since this is becoming the most common framework for scheduling and resource management in many of the datacenter markets they are trying to capture.
The company that was first to pluck graphics processors from gaming to render them programmatically and hardware-wise to power top-tier supercomputers (a deeper look at that history here), already has created a stable ecosystem based on those high performance computing roots. They have since branched out to create new links to other non-HPC areas, including database acceleration and more enterprise-focused workloads, but the question is how will the addition of a new potential class of deep learning capabilities in hardware really add to their existing ecosystem?


AMD Feels The Server Recession, Too, But Growth Is Looming Large
With a server recession underway and its latest Epyc CPUs and Instinct GPU accelerators still ramping, this was a predictably soft, but still not terrible in the scheme of things, quarter for AMD. But the company is projecting that its datacenter business will still have somewhere around 50 percent growth …

AMD Roadmaps Lead To Mountains Of Money
IT organizations, especially the key hyperscalers and cloud builders, don’t buy point products, they buy roadmaps. And they pay for them, too. And the precise focus that AMD has brought to bear in its eight year turnaround has made it have the most credible and expansive CPU product line for …
Interview: Post-Earnings Insight With Nvidia CFO Colette Kress
After Wall Street closed the markets for the day and Nvidia reported its financial results for the second quarter of fiscal 2025, we had the opportunity to chat with Colette Kress, chief financial officer of the accelerated computing giant. We wanted to get a better handle on how the delays …
I am missing DSP in the list here, what about Ceva CDNN sounds far more compelling than nVidia’s usually over powered tech.
The only time we get any word on that is through word of mouth. Show us where those are being deployed at scale for production deep neural networks and we’re all over the story. BUt so far, no one is talking.