

Document databases are an integral part of the application stack, but they often have scalability issues and they tend to end up off to the side of the Hadoop systems that are increasingly being used as a the repository of record for all kinds of data. Ideally, customers want am analytics system that can store data in various formats, all on the same Hadoop cluster and all with the same underlying scalability of Hadoop.
That, in a nutshell, is what MapR Technologies is doing with its eponymous Hadoop distribution. At the Strata + Hadoop World conference in New York this week, MapR previewed a new document database capability that it has embedded into its MapR-DB key-value data store, allowing for documents stored in the industry standard JSON format – which is used for data interchange between applications and for telemetry streaming out of all kinds of devices these days – to be housed in this data store and queries with the same functions as are part and parcel of MapR-DB.
By integrating JSON data into the existing MapR-DB key-value store, MapR accomplishes a few important things that will help applications scale and keep the cluster and node counts down to a minimum at enterprises.
“Now you have the full database functionality and you do not have to take your JSON files, flatten them, put them in a key-value store or do a subselect and so on,” Jack Norris, chief marketing officer at MapR, explains to The Next Platform. The integration of JSON into MapR-DB makes the documents updatable, which is a necessity for product catalogs or recommendation applications that might store product reviews or customer comments that are added to records, just to give a few examples. “Many applications revolve around what do you recommend or show, and how do you have the application respond in real-time to the customer and their interactions. The ability to incorporate the analytics and operational data together is a big plus because now, instead of doing it in separate technologies and deal with separate clusters, you can do that in a single environment. All of the real-time database manipulations are available through MapR-DB and then query and interactive analysis is possible with Drill.”
As for scale, the JSON add-on for the MapR-DB NoSQL data store allows for JSON databases to scale from hundreds to thousands of nodes, which is a scale Norris says that other popular document databases such as MongoDB or Couchbase cannot reach. Scale is something that the MapR Hadoop distribution is known for, and many of the largest commercial Hadoop clusters are using the MapR variant because of its ability to scale.
The underpinning of the MapR distribution has always been its MapR-FS file system, which is a true file system that speaks the Network File System lingua franca of Unix and Linux operating systems and that also supports the API stack for the Hadoop Distributed File System (HDFS). This NFS foundation made HDFS readable and writeable in a random fashion, like any other file system. MapR did a lot of work to improve the performance of the HBase data warehousing overlay for HDFS, originally created by Facebook, which was possible because of this NFS foundation, and to a certain extent, the MapR-DB NoSQL data store and now the JSON support also relies on that underlying MapR-FS file system. The important thing is that all of these data sets and data types can exist in the same cluster and have their information accessed in multiple ways, depending on the application.
“We have file, table, and now document database all collapsed down to and writing to the disks and existing in that layer, and this is where the performance and ease of administration is derived from.”
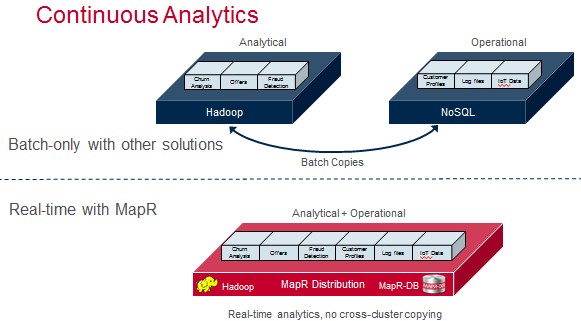
But perhaps more importantly, the ability to use MapR-DB as a JSON document database means that companies do not have to have unique clusters for their HDFS data lakes, key-value stores, and document databases and spend lots of time moving data back and forth as well as money maintaining separate clusters. Having all of these data types in one system also reduces the time from data ingest to business insight.
“There are two key areas that people are looking at in IT departments,” explains Norris. “The first is how do they decrease their costs and increase their efficiency. And a lot of times, this means removing IT from the initial involvement, steps like defining the schema and getting applications up and running. The second is how do they create a platform for innovation so they can operate swiftly and with agility so they can take advantage of opportunity and respond to threats to competition. That’s why this is important and why JSON is such a strategic move for MapR.”
Rather than just skin the MongoDB NoSQL database, and make MapR-DB look like MongoDB as far as applications are concerned, MapR has come up with its own interface into JSON documents, called the Open JSON Application Interface (OJAI), which Norris says was created in conjunction with the JSON community.
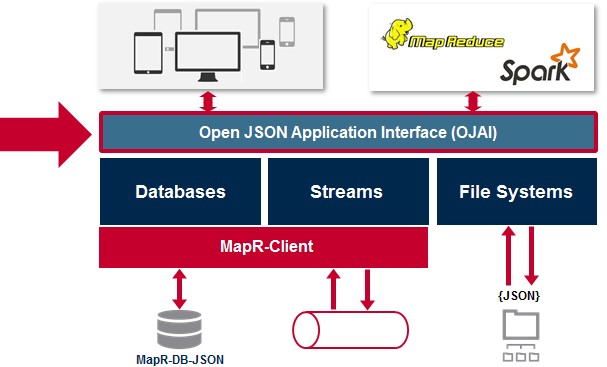
“We did do a lot of analysis on the MongoDB API and considering the changes along the way and the use in a broader JSON and Hadoop environment, we decided to create our own,” says Dale Kim, director of product marketing at MapR. “And interestingly, when we showed this to our customers, none of them said, ‘Why didn’t you use MongoDB’s API?’ I think that people who have experience with MongoDB recognize that maybe it is time a new standard emerges.”
Given the fact that MapR has some of the largest commercial Hadoop installations in the world, scale for a document database was perhaps more important than strict MongoDB compatibility.
“MongoDB is successful and pervasive out there and used in many applications, and some of those are small applications that we are not looking to replace with MapR-DB,” says Norris. “But when there are so many JSON data sources out there, being able to collect and leverage those with a single platform does make a lot of sense. From that standpoint, just running MongoDB on top of Hadoop will not provide the same scale and benefits that you will see from MapR-DB.”
The JSON document database support for MapR-DB is available as a developer preview now, so MapR customers can download code and experiment with the feature. It ships with bindings for Java, Python, and Node.js. Norris says the document database feature will be generally available later this year. MapR-DB JSON document support is in the MapR Community Edition, which is the freebie version of the Hadoop stack that provides the base scalability in a single cluster. If you want the advanced features MapR has, such as multi-cluster replication, then you have to buy a license for the Enterprise Edition. Both are based on the MapR Distribution 5.0 stack that was announced earlier this year. The Enterprise Edition costs $4,000 per node in a base setup with single-cluster functionality of MapR-FS and costs $10,000 per node with the MapR-DB data store added and all of the bells and whistles, including replication and high availability features.
It is hard to say how the uptake of the JSON feature for MapR-DB will go, but the uptake for the key-value store has been brisk, according to Norris, with approximately 40 percent of its Hadoop customers adopting it. And one of the drivers for the MapR distribution from the beginning has been its ability to run mixed workloads of HDFS, HBase, and NoSQL on the same set of machines rather than on separate clusters.
“It has been surprising how organic the growth has been within our customers, and I think a lot of that is because of the architecture we have put in place so they can leverage our multi-tenancy, logical volumes, and workload management tools to support diverse workloads on the same clusters,” says Norris, adding that HBase is so finicky on most Hadoop distros that customers want to run it on dedicated clusters but they don’t have to on MapR because of the way the HBase APIs are implemented on top of MapR-FS. “I think we skew higher than other distributions, and when we replace competitors, what we find is that they are more likely to have multiple physical clusters than MapR.”


A Database For All Locations, Models, And Scales
Enterprises are creating huge amounts of data and it is being generated, stored, accessed, and analyzed everywhere – in core datacenters, in the cloud distributed among various providers, at the edge, in databases from multiple vendors, in disparate formats, and for new workloads like artificial intelligence. In this fast-evolving space, …
The Tough Climb To Profitability For MongoDB
There is something weird about storage companies that were started around the same time as the Great Recession. The big ones that have gone public after being true innovators in their fields – MongoDB in NoSQL databases, Nutanix in hyperconverged storage, and Pure Storage in all-flash arrays – have grown …
Beefing Up A Cloudy NoSQL Database To Ride The AI Wave
To Andrew Davidson, senior vice president of products at MongoDB, the database business operates in an entirely different type of market than traditional software, where vendors might sell their products into one organization after another, eventually reaching a saturation point. They can grow fast, but it’s tough to keep that …
Be the first to comment