

Although the performance and efficiency gain of using accelerators, including GPUs, can be quite staggering, programming for boosted systems still presents some challenges, despite the large amount of work over the years to streamline the process. This is especially the case of programmers who are pairing GPUs with Java, an undertaking that is in demand but still fertile ground for continued development.
The offload model for accelerators like GPUs, however, brings along inherent inefficiencies. Not only does the code need to move work from a host processor over to the accelerator, the execution model needs to work in both contexts. This is where the problem lies, according James Clarkson and his team from the University of Manchester. Such programming approaches “require developers to be aware of the contexts when writing code and to ensure that execution and data are synchronized across them.” The goal then was to trim at the edges of that problem by automating a lot of that movement and redundancy.
Consider for example CUDA or OpenCL, both of which are extensively used in GPU computing (and OpenCL now for FPGAs, which are finding new inroads lately). While a great deal of work has gone into paring down both frameworks ultimately, it is up to the developer to segment their codes in the pieces that run on the host versus the other chunks that run on the kernel. This means there is overhead when it comes to coordinating the execution between the two.
Accordingly, Clarkson’s team developed an experimental framework for a lightweight approach to programming GPUs directly from Java while adding very little in the way of code work. Their effort, called JACC (short for Java Acceleration system) whittles down some of the complexity of GPU programming by hiding a lot of the hardware and data movement details while offering what appears to be a reasonable speedup on a number of benchmarks while cutting down code size by 4.4X.
The goal, as the Manchester researchers state it, is to produce high performance GPU code without having to alter applications to suit the device. Therefore, instead of developing yet another offshoot of the Java language, existing features can provide it with extra information about the application via metadata gathered through task abstraction and annotations.
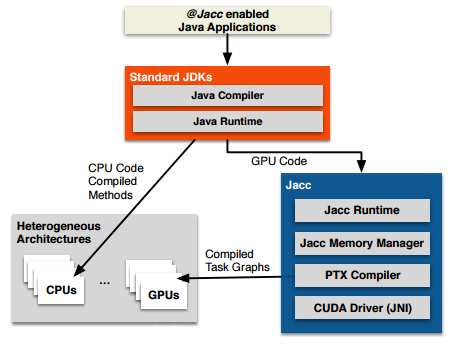 The cleverness of JACC is that it can provide the right abstractions to allow highly parallel kernels without making the developer change the programming approach. As Clarkson’s team describes, this is done by basing the concept on two building blocks; the task and the task graph. “A task encapsulates all the vital information for executing code in a parallel environment…tasks are not restricted to execute on specific hardware. They are mapped onto hardware when they are inserted into a task graph; a mapping that can be changed dynamically and can be created from any method in the application but with an @JACC annotation create data-parallel kernels using either implicit or explicit parallelism.”
The cleverness of JACC is that it can provide the right abstractions to allow highly parallel kernels without making the developer change the programming approach. As Clarkson’s team describes, this is done by basing the concept on two building blocks; the task and the task graph. “A task encapsulates all the vital information for executing code in a parallel environment…tasks are not restricted to execute on specific hardware. They are mapped onto hardware when they are inserted into a task graph; a mapping that can be changed dynamically and can be created from any method in the application but with an @JACC annotation create data-parallel kernels using either implicit or explicit parallelism.”
The concept behind this is not new, but the JACC approach is different. The APAR-API, Habanero Java and other frameworks, including RootBeer are similar in purpose but they generate their code via CUDA or OpenCL whereas JACC is targeting the virtual ISA of the GPU. Further, there are already existing directive-based approaches designed to let developers do similar work via OpenMP and OpenACC but there are some key differences that might make JACC an interesting alternative. Unlike both of the above, JACC optimizes executions automatically by chucking all the redundant data transfers and allowing for out of order executions. Eventually too, JACC can allow for future extensions that permit dynamic selection of both the number and type of devices for execution (so not just GPUs, but also FPGAs or ASICs). When that point comes, all that will be required on the developer’s end is, as the researchers describe, “a model of the heterogeneous portion of the application, captured as a Direct Acyclic Graph (DAG) and the decoration of kernels with metadata that will transparently guide the compilation.”
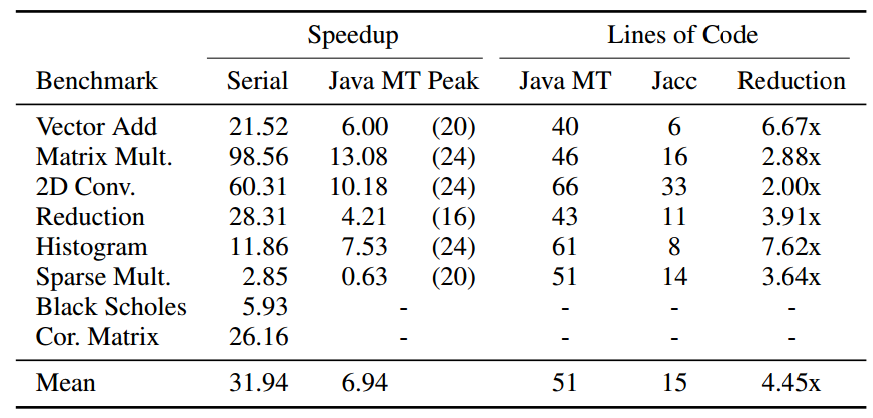
JACC was benchmarked using two Xeon E5-2620 (12 core/24 threads) and an NVIDIA Tesla K20 card. In the results below you see JACC compared to serial Java implementations (the bracketed numbers are thread counts).
The next stage of JACC development will broaden the scope of the Java language to target more areas as well as, more specifically, integrating the offload portion of the tasks with the JVM—including the garbage collector, which would allow objects to be created on heterogeneous devices. Look for more to be released soon to open this to the wider community of users. In advance of code releases, the concept is detailed at length here.


JVM Boost Shows Warm Java is Better than Cold
The Java Virtual Machine (JVM) is a vital part of modern distributed computing. It is the platform of big data applications like Spark, HDFS, Cassandra,and Hive. While the JVM provides “write once, run anywhere” platform independence, this comes at a cost. The JVM takes time to “warm up”, that is …
Be the first to comment