

Open source hardware and microprocessor projects are certainly nothing new, and while there has been great momentum on the CPU front, there have not been efforts to release an open source GPU into the wild. However, at the Hot Chips conference this week, a team of researchers revealed their plans for MIAOW, a unique take on open source hardware that leverages a subset of AMD’s Southern Islands ISA that is used for AMD’s own GPU and can run OpenCL codes at what appears to be an impressive performance point that is comparable to existing single-precision GPU results.
As an open source project, it is reasonable to think that once it is further refined, some clever startup might decide to take the chip into full production. However, as one might imagine, there are likely going to be some serious IP infringement issues to address. Since the entire scope of the project is based on a pared-down variant of the AMD ISA for its own GPUs, the team will either need to work within AMD’s confines to continue pushing such a project or the effort, no matter how well proven it is in FPGA prototyping or actual silicon, could be a series of lawsuits waiting to happen.
Dr. Karu Sankaralingam, who led the team’s effort at the University of Wisconsin, where the project is based, says that building an open source or any other hardware project is bound to incur legal wrangling, in part because the IP almost has to be reused in one form or another. Generally, he says that for open source hardware projects like this one, the best defense is to use anything existing as a base but focus innovation on building on top of that. He says that to date, AMD has not been involved in the project beyond a few individuals offering some insight on various architectural elements. In other words, if the team is able to roll this beyond research and into any kind of volume, AMD will likely have words.
Still, looking past commercialization of the base, as a research proof of concept, it is worthwhile to note that with a relatively small team of five people on the hardware design and single individuals on the compiler, layout, and FPGA prototyping front can achieve a functional open source GPU implementation in 36 months that can run full, unmodified OpenCL programs. Sankaralingam says while they are impressed with their own benchmarks, they are still surprised they were able to do this at all.
As seen below, the basic compute unit architecture leverages a slice of AMD’s own ISA (95 instructions out of the available 400+ in Southern Islands), which are broken down into sets of vector, scalar, and memory instructions. Keep in mind that this stripped down GPU proves its performance mettle in single-precision only at this point and the team is still working on adding graphics support.
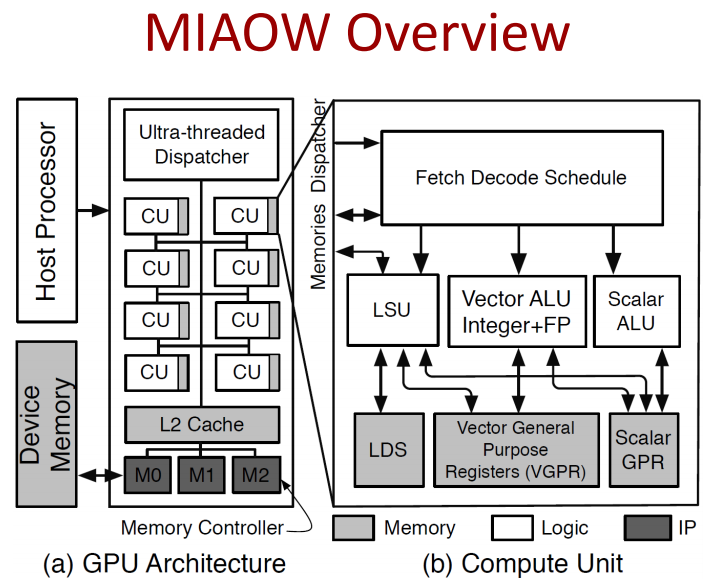
The MIAOW GPU coprocessor can support up to 32 compute units, each of which connects through a network to the L2 cache, which is then connected to the memory controllers, all of which feeds into the device memory. There is a host processor, which offloads to the GPU and a dispatcher to organize and send the work out. Nothing particularly out of the ordinary there, of course, but it is noteworthy that they’re showing this can be done and implemented and tested on an FPGA with decent performance showings. There are multiple variants of the MIAOW design; a full ASIC, one that has been mapped to the FPGA, and another hybrid design for prototyping and testing different ideas without rebuilding.
On the comparative performance note, and remembering that MIAOW is a stripped-down version of other commercial GPUs, take a look at the relative performance matches between MIAOW and the AMD Tahiti GCN design that AMD presented around this time last year. While there are certainly some gaps, given the number of architectural (note the GhZ differences in particular) and instruction pieces that were left on the table, this is a stellar effort in its early stages.
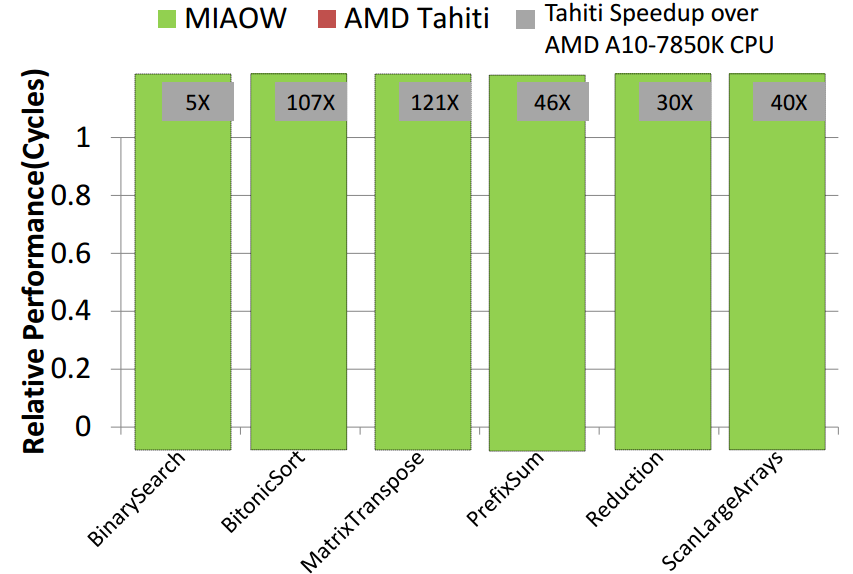
Sankaralingam says that the benchmarks above are important because they represent the diversity of GPU behavior. For instance, as seen, there are performance comparisons of not just the GPU, but its performance compared to execution on CPUs. As far as where they do not show the best performance, he notes that the 2X failure is because they don’t have good coalescing support compared to AMD’s design, so there is a lot more memory bandwidth that needs to be used compared to Tahiti. It also uses more power than Tahiti per compute unit (0.52 Watts of Tahiti versus MIAOW’s 1.1 Watts), but the team has not started to do many power optimizations, Balasubramanian says.
It should be noted that MIAOW is a GPU’s compute unit. As team notes, it still does not have the auxiliary logic needed to create actual graphical output and lacks the logic needed to connect it to a specific memory interface or system bus. The goal is to move over the innovations made to date for the wider world to keep developing, assuming of course, they are careful about any extensions they try to commercial due to IP issues.

Amazon Will Spend Nearly A Year Of AWS Revenue On AI Investments
There is a bit of AI spending one-upmanship going on among the hyperscalers and cloud builders – and now the foundation model builders who are partnering with their new sugar daddies to be able to afford to build vast AI accelerator estates to push the state of the art in …
Saudi Arabia Has The Wealth – And Desire – To Become An AI Player
The oil barons of the Middle East have been trying to diversify out of carbon fuels and into other parts of the global economy for decades, but artificial intelligence may be a game that only hyperscalers, cloud builders, and Middle East sovereign wealth funds can play at the highest levels …
A Deep Dive Into Datacenter And Server Spending Forecasts
Spending on AI systems in 2024 just utterly blew by the expectations of the major market researchers and those who dabble in metrics like we do. There has just been an unprecedented amount of spending, mostly for systems that are accelerated by Nvidia GPUs. It remains to be seen how …
MIAOW is probably not the first open source GPU. Nyuzi may have that honor:
http://nyuzi.org
http://www.cs.binghamton.edu/~millerti/nyami-ispass2015.pdf
You may want to look at that bar chart, it makes no sense at all. Otherwise an interesting read.
I agree that bar chart is horrendous.
Since this article was published I corresponded with Jeff from Nyuzi and learned that the software only approach would give around 25% performance/watt of modern embedded GPUs. So we could use Nyuzi, however it would need 4x the gates and 4x the power.
With MIAOW only being effectively an OpenCL style parallel engine, the only remaining course of action is to start an actual Libre CPU / GPU project. That’s what I did and more information can be found at http://libre-riscv.org/3d_gpu/