
After three years of research into how it might accelerate its Bing search engine using field programmable gate arrays (FPGAs), Microsoft came up with a scheme that would let it lash Stratix V devices from Altera to the two-socket server nodes in the minimalist Open Cloud Servers that it has designed expressly for its hyperscale datacenters. These CPU-FPGA hybrids were rolled out into production earlier this year to accelerate Bing page rank functions, and Microsoft started hunting around for other workloads with which to juice with FPGAs.
Deep learning was the next big job that Microsoft is pretty sure can benefit from FPGAs and, importantly, do so within the constraints of its hyperscale infrastructure. Microsoft’s systems have unique demands given that Microsoft is building systems, storage, and networks that have to support many different kinds of workloads – all within specific power, thermal, and budget envelopes.
Microsoft’s efforts to accelerate the training of various kinds of deep learning approaches – including convolutional neural networks, deep belief neural networks, and recurrent neural networks – was a hot topic at this week’s Hot Chips 27 conference in Silicon Valley. Such networks are at the heart of systems that perform computer vision and video and photo recognition, speech recognition and natural language processing; they are also used in recommendation systems that help push products to us in advertisements and on retail sites and behind all kinds of intelligent agent software. These deep learning systems are what gives the modern Internet whatever brains it has, to put it bluntly.
Unlike researchers or commercial enterprises that build deep learning systems that only have to do that one job, Microsoft has to operate its infrastructure at scale, and this makes its choice of accelerator a bit different from operating in the abstract, explained Eric Chung, a researcher in the Microsoft Research Technologies lab that adapted Microsoft’s Open Cloud Server so they could be equipped with FPGA accelerators, a system that was called Catapult.
“The datacenter is interesting because we get to scale,” explained Chung. “The key here is that we have a large set of fungible resources that we can set up, that we can allocate on demand for a particular task, and when that resource is no longer needed, we can use those resources for other applications. The datacenter has a very diverse set of applications, and this is a very different question than asking what would you do if you just wanted a platform for deep learning. Machine learning practitioners just want the largest GPU cluster than can get, and we are asking a slightly different question here.”
“What I am really excited about are the Stratix 10 FPGAs will be using Intel’s 14 nanometer process and will have up to 10 teraflops per device. And that is when I think this space gets really interesting.”
The choice of system design involves balancing the desire to have specialized functions for specific applications against the economics and simplicity of having a homogeneous set of infrastructure. Having a relatively homogeneous set of infrastructure allows for components to be purchased at the highest volumes and therefore the lowest prices and also increases the maintainability of the infrastructure because the support matrix on components is smaller. (This is one of the reasons why the X86 server has come to dominate the datacenter.)
The problem arises, however, when you have an application where the work just can’t get done fast enough on CPUs, or you have to allocate a tremendous amount of resources to an application to get an answer in a timely fashion. We would say that you end up paying with either time or money, and sometimes both if the job is difficult enough. So it is with deep learning, which only achieved the breakthroughs we have seen when convolutional neural networks with very large training datasets were married with GPUs with lots of relatively inexpensive parallel computing capacity.
“The deep learning community is very happy with this because you have given them machines based on GPUs or ASICs that can speed up the convolutional neural networks by several orders of magnitude,” Chung said. “But there are some problems with this. If the demand is low at any given time, you have a stranded capacity issue. Another problem is that you have broken this fungability in the datacenter. If your demand exceeds what you have in your limited pools, you cannot scale beyond that. In fact, within Microsoft we do have a lot of GPUs and the big complaint is that we do not have enough of them. And heterogeneity is incredibly challenging for maintainability. You want to have the minimum number of set of hardware SKUs to test and maintain. So having a very different SKU to fit GPUs is very challenging.”
Microsoft could put a GPU accelerators in every single server, which is great for homogeneity and maintainability, but this would substantially increase the power and cost of servers, said Chung. And not all workloads will necessarily make use of those GPUs, even if they could be put into the Open Cloud Servers, which they cannot. (Microsoft could use a 40-watt GPU aimed at laptops and plug it into a mezzanine card much as it does its FPGA, but the GPU is not necessarily as malleable as an FPGA when it comes to the diversity of functions it can perform.) Microsoft could also just create special-purpose ASICs specifically to run neural nets.
“At Microsoft, we have a very diverse range of workloads – enterprise, Bing, Azure workloads, we have latency critical workloads and batch workloads, email – I would be willing to say that the number of servers we needed for running deep learning is at most in the single digits percentage of all workloads. This is a problem for ASICs because there is a long turnaround time to implement them.”
As we know from the network appliance business, which uses the bulk of FPGAs sold today, an FPGA is basically a way to simulate the operations of an ASIC. It is arguably harder to program than a GPU accelerator, but it has its own kind of flexibility in that it can be programmed to do just about anything a chip can do as well as implement the algorithms embodied in software. The downside of an FPGA, at least with the current generations of devices available from Altera and Xilinx, the peak performance of an FPGA is considerably less than for a GPU accelerator. The FPGA therefore represents a balance between something that is general purpose and specialized hardware, said Chung.
What seems clear is that Microsoft wants to have some kind of relative accelerator with a low power envelope inside of its Open Cloud Server nodes. The Stratix V FPGAs from Altera weighed in at around 25 watts, adding about 10 percent to the heat dissipation of the server, while adding only around 30 percent to the cost of the server. Chung was not at liberty to discuss what an Open Cloud Server mode cost and what it was paying for the FPGA accelerator daughter cards in the system. Our guess is the node costs a couple thousand dollars and the FPGA accelerator costs several hundred dollars.
Using Scale To Overcome The GPU Performance Gap
For various kinds of recognition systems, Microsoft uses deep convolutional neural networks, and it wants to use its infrastructure for both training the nets and for running the algorithms that are derived from the training that actually do photo, video, and voice recognition in production applications. (To give you a sense of the scale of these applications, Facebook uses massive banks of GPUs to train neural nets how to analyze photos for their content, and uses CPUs to use the output of these nets to categorize a whopping 600 million photos uploaded by users every day on the social network. How much CPU capacity it takes to do this is a secret, but it is probably not a small amount.)

Microsoft’s goal, said Chung, is to get an order of magnitude performance increase on neural nets using the Catapult FPGA add-on for its Open Cloud Servers and fitting in that 30 percent incremental cost and 10 percent incremental power budget. Microsoft wants to expose the FPGA functionality as it relates to deep learning as a composable software library. Incidentally, Microsoft can change the personality of an FPGA in around a second, and has created a different software stack it calls the Azure SmartNIC, which is a network interface card married to an FPGA that can do line rate encryption/decryption and compression/decompression on network traffic as well as other software-defined network functions using the same Catapult mezzanine card.
The Catapult FPGA card has a Stratix V D5 that has 172,600 Adaptive Logic Modules (ALMs) which implement the “code” in the FPGA plus 1,590 hard coded digital signal processors (DSPs) and 2,014 M20K memory blocks (for a capacity of 39 Mbits). The Catapult FPGA mezzanine card has 32 MB of NAND flash memory and 8 GB of DDR3 DRAM memory (two sticks running at 1.33 GHz) for storage and has a single PCI-Express 3.0 x8 link to hook the FPGA to the Open Cloud Server node.
Here’s what the accelerator building block for neural nets running on FPGAs looks like:
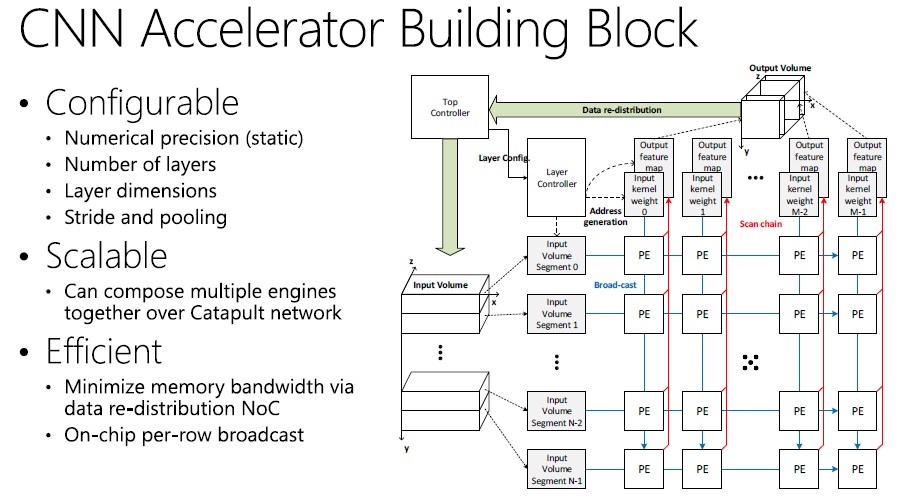
This is very heady stuff, but the cut and dry is that this FPGA block implementing the neural net is statically and dynamically reconfigurable, so you can dial up and down the number of layers and dimensions in the net as well as change the precision of the numbers used in the algorithms without having to rejigger the FPGA’s underlying hardware description language.
The Catapult network also allows for neural nets to extend across multiple FPGAs. Chung’s colleague at Microsoft Research Technologies, Andrew Putnam, described at last year’s Hot Chips shindig. Each FPGA has two Mini-SAS SFF-8088 ports coming off it, which is used to make a private network fabric that is just for the FPGAs and that is separate from the 10 Gb/sec Ethernet switched fabric that links the Xeon server nodes to each other so they can share work and data. The SAS links run at 20 Gb/sec and there is about a 400 nanosecond latency hop across the SAS fabric. Each Open Cloud Server has 48 nodes – 24 half-width servers with two Xeon sockets each – and the torus interconnect works like this: six adjacent FPGA cards are linked in East-West fashion to each other, and then these multiple groups of FPGAs are linked to each other in a North-South fashion to cover all 48 FPGAs in a single rack of Open Cloud Servers. (Microsoft had to create its own six port and eight SAS cables to do this FPGA fabric.)
The point is, this FPGA fabric allows for up to 48 of the devices to be ganged up to work together without involving the CPUs or their network whatsoever. This is one of the critical aspects of what Microsoft has done that makes its use of FPGAs scalable and competitive with GPU or other kinds of accelerators of special ASICs for running neural nets. The FPGA setup has two different modes of operation when running neural net training code, says Chung: one that processes a single image to do a classification as fast as possible and another that works in batch mode that throws a bunch of images at the net and classifies them in parallel.
So how does the FPGA stack up against CPUs and GPUs when it comes to neural net training? Microsoft ran some tests on its Catapult setup and compared it to some raw CPU and CPU-GPU hybrid tests using the ImageNet benchmark to figure that out. Here is how the machines stack up on the test:
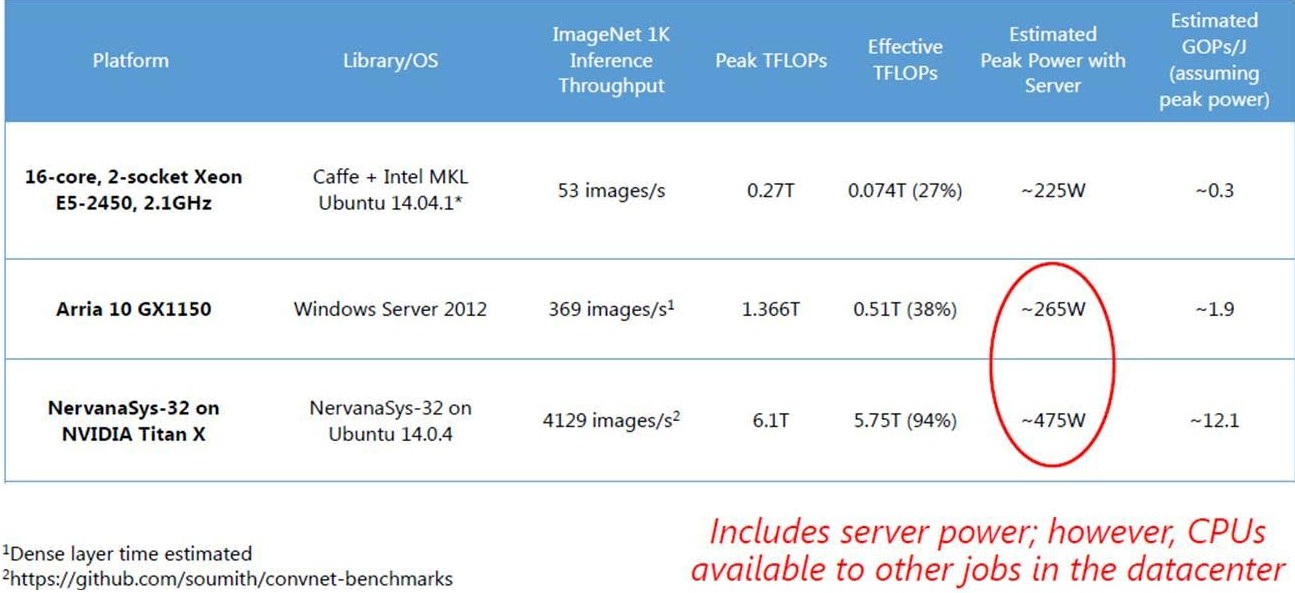
And here is how the machines stack up with the device power draw isolated from the underlying server power draw in the hybrid configurations:
The CPU-only test is for an Open Cloud Server node using to eight-core Xeon E5 processors, and it is running Linux and the Caffe neural net framework. That server node has 270 gigaflops of performance with processors running at 2.1 GHz, and it is able to process 53 images per second on the ImageNet-1K test. (This has 1,000 different image classifications.) Chung says this yields an efficiency of about 27 percent on the CPUs, which is not all that great. The machine had a peak power draw of 225 watts and if you do the math that works out to around 300 million operations per second per joule. Chung did not talk about how the Open Cloud Server equipped with the Stratix V FPGA did, but as The Next Platform previously reported, it can do 134 images per second.
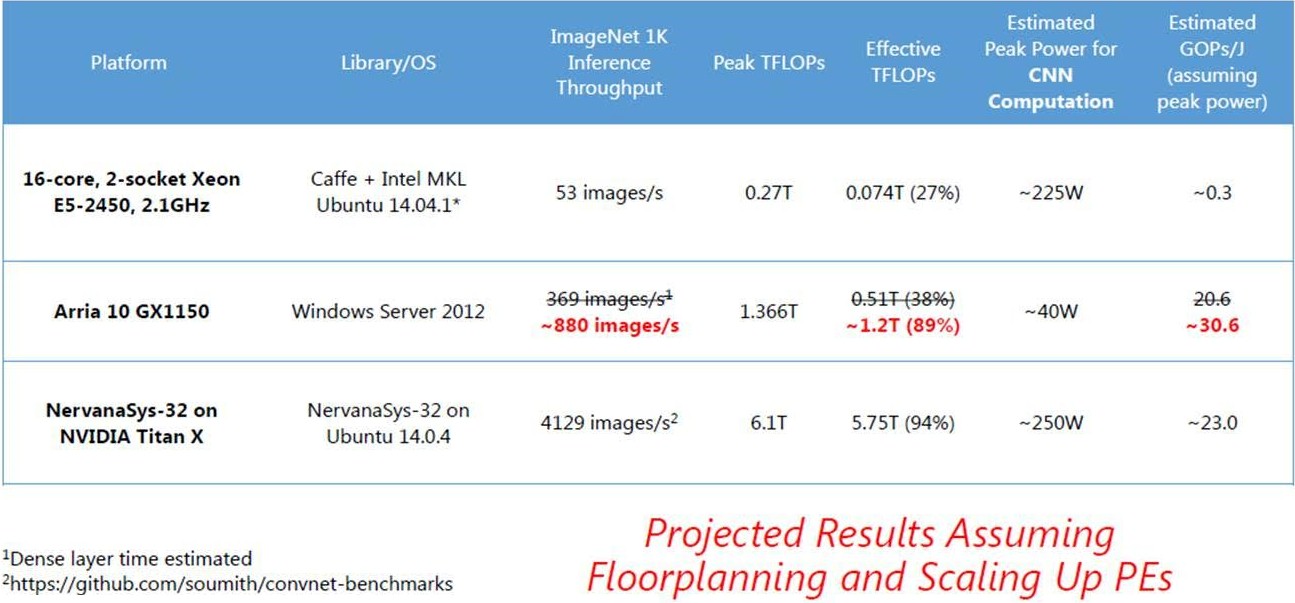
For its most recent deep learning tests, Microsoft upgraded the Stratix V FPGA card in the Catapult system to an Arria 10 GX1150 from Altera, which has a lot more oomph. Microsoft had been projecting it could get about 233 images per second processed on ImageNet-1K using the Arria 10 FPGA, but it has done a bit better than that in its actual tests, hitting 369 images per second. With 265 watts of power draw, that works out to 1.9 gigaoperations per second per joule, which is a lot better than the power efficiency of the plain CPU setup.
That Arria 10 FPGA is rated at 1.36 teraflops of raw performance, and Chung said the FPGA was running at 270 MHz but Microsoft hoped with floorplanning and other tweaks it could boost that to around 400 MHz. With those tweaks, Chung hopes to boost the utilization of the FPGA from about 35 percent of its capacity to 89 percent, and could drive the ImageNet-1K benchmark as high as 880 images per second.
For a GPU comparison, Microsoft is citing the combination of a Titan X GPU graphics card, which has 6.1 teraflops of single-precision floating point math, paired with a Core i7-5930K processor from Intel. With the Titan X doing the heavy lifting, the ImageNet-1K test can burn through 4,129 images per second and that setup burns 475 watts for 11.4 gigaoperations per second per joule.
This brings up an important point. In a deep learning cluster, the CPUs are mostly doing bulk transfers of data to the FPGAs for processing and are mostly idle, says Chung. So if you have a dedicated deep learning cluster, these idle chips consume power but they can’t do any real work. In the Azure cloud, Microsoft can put those idle Xeons to work doing something else.
“In this calculation, we are factoring in total server power, but that is not exactly quite right because in the datacenter we often have many tasks, and the CPUs are mostly idle and you can use them to do other kinds of work. So it is not clear if you really want to include the server,” says Chung.
We say this: put the application that uses the neural nets on the CPU part of the Open Cloud Server and have it constantly classifying new photos, then use the FPGA or GPU accelerators that are constantly training the neural nets. This way, you get a frontal lobe, complete.
The point is, the FPGA is not looking too shabby in terms of gigaops per joule, but Chung did point out that Microsoft is still working with underutilized FPGAs.
“We have a small team of developers who have worked on this for a very short time compared to a community that has worked really hard to make this run very fast on a GPU,” Chung explained. “We know that we actually have quite a bit of headroom. In fact, these are just projections, and please don’t hold me to them, and if we did some floorplanning and scaled out the designs and maximized all of the FPGA, we could push that to around 880 images per second and there we will start to see some very interesting energy efficiency numbers.”
Because the Arria 10 FPGAs pack so much more of a wallop compared to the Stratix V FPGAs, Microsoft thinks it can make up the difference between GPU and FPGA training performance with server node scale – particularly with the Catapult FPGA fabric at its disposal. But Chung and his colleagues are already looking ahead. “What I am really excited about are the Stratix 10 FPGAs will be using Intel’s 14 nanometer process and will have up to 10 teraflops per device. And that is when I think this space gets really interesting,” says Chung.


AI Accelerates Cloud Revenues As Well As Cloud Investments
Three years ago, thanks in part to competitive pressures as Microsoft Azure, Google Cloud, and others started giving Amazon Web Services a run for the cloud money, the growth rate in quarterly spending on cloud services was slowing. In the last few quarters, the rate of spending has begun accelerating …
What Will AMD Do With Programmable Logic And Other Xilinx IP?
AMD has finished its acquisition of Xilinx, which ended up costing close to $49 billion instead of the original $35 billion projected when the deal was announced in October 2020 thanks to the rise of AMD’s shares over the past year and a half. And now, with AMD getting the …

Inside The Infrastructure That Microsoft Builds To Run AI
Like the rest of the world, we have been watching Microsoft’s increasing use of foundation models as it transforms its services and software. It is hard to say for sure, but with hundreds of thousands of GPUs deployed across the dozens of regions, Microsoft has probably amassed the largest pool …
For all those doubters on why Intel spend so much money on Altera it becomes clearer and clearer to me now that this was a very well thought out strategic master move from Intel which will put them on the front runner for a long while. If they marry the MiC architecture with FPGAs on the same die they will be unstoppable.
I’m not sold on Intel being unstoppable, as they are not the only ones working with FPGAs, and The OpenPower Licensees have Nvidia for their GPU accelerators, and there is more to the FPGA market than simply Altera’s products, and I seriously doubt that Intel would turn down any of Altera’s sales to any OpenPower licensee. I still do not see Intel’s Xeon Phi’s rivaling AMDs or Nvidia’s GPUs for total FP performance. Nvidia will be in a position to supply many of the OpenPower licensees, possibly Google and Facebook, and AMD would not be restricted entry into OpenPower’s growing ranks of companies. Intel will need to counter AMD’s HPC Systems/APUs on an interposer and the interposer will allow for more that just wide data buses between GPU/CPU cores and and HBM memory stacks, with the interposer’s ability to be etched with not only thousands of memory traces but also plenty of off chip bus snooping/other control traces and buses for cache coherency and other functionality.
Whole complete interconnect fabrics will be done up on the interposer substrate for AMD’s exascale/HPC SKUs, including FPGA’s added between the bottom logic chip, and the die stacks above for some FPGA ability added to the HBM stacks if AMDs latest patent filings are any indicator.
The main thing that will help the competition is the price point, and as soon as AMD gets its Zen based HPC Opteron APUs going, expect there to be more low cost competition in the x86 market in addition to those third party OpenPower Power8 licensees that will be competing for a slice of the server/HPC market! AMD’s SeaMicro division may be shuttered but that Freedom Fabric IP is still in AMD’s hands, and most likely a good portion of that new HPC fabric that AMD has mentioned comes from that acquired IP, mixed with AMD’s purposed exascale research R&D. Intel grabbed up Altera up for more than just FPGA reasons and HPC! AMD’s, and other’s, HSA usability is lends itself very appropriately towards the supercomputing market a supercomputing market that provided the vector processors that would evolve to become the modern GPUs of today! It’s only natural that the GPUs via HSA aware systems are returning to their vector processing roots for HPC and consumer computing. The server market will not be only about x86, just throw ARM, and the licensed Power8’s into the mix and everybody can utilize FPGA, I even expect to see some MIPS based servers running PowerVR GPUs for accelerators in the near future!
Thanks for your counter opinion but I am not sold on what you say either. OpenPower is all good and well but I am not sure if Power architecture will play such a big importance in the long run. IBM has been gambling big here giving away the control on the process. The margins need to be high to keep their even (now) reduced R&D going. Intel has the benefit of being both in consumer as in professional space that helps to share out the R&D over volume. AMD is pretty much out everywhere. Unless Zen really is a miraculous comeback they will be out of the game completely. So far the executions on AMD sides in the last seven years have been lacklustre at best disastrous at worst. I can’t see any coherent strategy at that company besides their APU/HSA efforts which so far hasn’t gained them any traction anywhere. Can they pull the ship around? Do they have enough resources to pull the ship around? At the moment there is nothing that convinces me that they can.
You also underestimating the significance of having FPGA on DIE with a Xeon CPU via a stacked memory architecture. Not a single other company has got their hands on that. That would introduce a new paradigm in the CPU world. We had CPU, APU but this is something on a complete different level in terms of flexibility and workload adjustments.
Sure someone can license a stock ARM core and botch things together but ARM has still a lot to prove in terms of performance scaling.
MIPS? Sounds like a long shot still think that was the second worst investment Imagination Ltd. ever did.
I agree with you OranjeeGeneral, and I look forward to playing with an Intel core + FPGA on the same die! Hopefully Intel will also provide good software to program their SoCs, offering sg like Synflow and myHDL would be awesome.