

Amid the din around the mainstream market chip and developer news at the Intel Developer Forum yesterday, a couple of quieter, but no less pressing topics were at the top of our minds here at The Next Platform. And while these matters might not compete with the broader world of PC and consumer market news that is capturing the public attention now, what we are watching is set to govern the future architectural direction for the entire server space in the next couple of years.
Two of the hottest topics at IDF this year from a datacenter view include new insights on the Optane 3D XPoint memory, which is detailed extensively here. Additionally, there was further information to be gleaned on the burgeoning technology and market front of the Intel and Altera FPGA relationship. Specifically, we were able to get a slightly deeper sense from Intel Fellow, Al Gara, and Altera’s director of strategy, Mike Strickland, about what new enabling forces are going to move this story forward—from its prologue as a financial curiosity, to its current status as an extensively-backed research endeavor, to actual products to fit a potential range of future datacenter requirements.
Conversations with both leads behind the public-facing tale of the FPGA and Xeon marriage are, in a word, confident. There is an unwavering sense that they both know something a large cross-section of readers and analysts don’t. After all, if Intel forks over $16.7 billion for a company that has always reported modest possibilities for its own reach, there must be more to the story than anyone sees, right?
To answer our own question, the initial speculation was that there was massive growth potential for a new range of applications that might take advantage of FPGAs, or that the FPGA-boosted switching market would explode, or even that there would be big, unmet demand for this particular type of acceleration (over GPUs or even high-test CPUs) that the mega-cloud providers could tap into. And if Stickland and Gara’s hints are taken correctly, all of these things are true—and at a volume that none of us might expect, even in a server market that won’t be tapped anytime in the near future.
The thing to focus on here, is less about the more practical, technical marriage between FPGAs and Intel processors, and more about the grander challenges. There are clear performance constraints ahead as Moore’s Law trails on, and coupled with that, there are increasing power limitations. Here is where the key to the deal lies. As Gara described to The Next Platform from IDF this week, “When you’re power limited, you find that specializing certain functions in a way that brings both performance and performance per watt is highly beneficial and can offer differentiated performance.”
“By recognizing we have enormous capability to integrate things onto our silicon, the opportunity is there for us to add more specialized functions—FPGAs offer the opportunity to do this in a way that’s more general than a unique specified function that might only be used for one customer, it gives us more generality.”
While this is more of an aspirational statement than a future roadmap projection, Gara says he can see the capabilities of FPGAs going multiple directions. “This means from the discrete, external devices as they are now, to bringing it in the package, and then also onto the processor, and potentially even onto the processor core. There is a wide scope of opportunity here, and I’m not saying we’ve explored them all and we know exactly where we are going but it’s a wide opportunity.”
To these points, as seen in the chart below, there is a QPI link that offers high bandwidth and speed over a PCIe card. With this in place, and given the programming model that is outlined there, one can make the educated guess that what Intel and Altera are looking at here will follow a coherency model. One might expect this to extend into the coming age when this is all done on a unified chip where the shared memory architecture, similar to what we see with CPUs and GPUs, will bring everything together. It also appears that the FPGA will have its own PCI-Express adapter slot, which means it will be possible to link to it directly, as well as through the Xeon E5 chip.
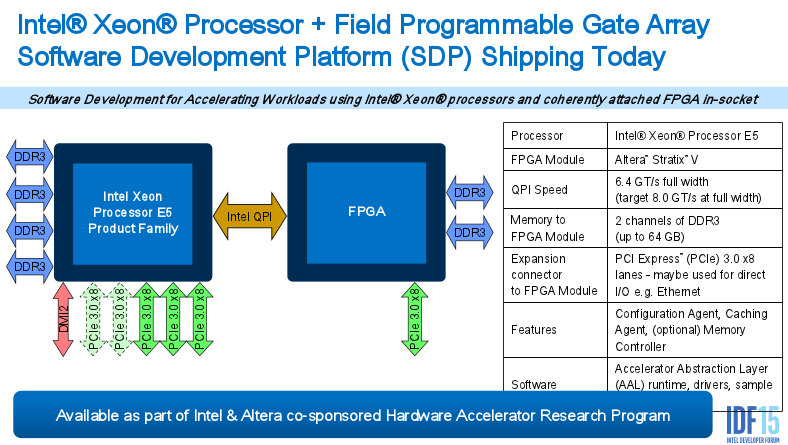
The key takeaway from Gara, as he discussed in his talk at IDF, is around the concept of workload acceleration. This is certainly not a new concept; in fact, it has been a part of processor evolution since the beginning (recall that things like floating point units were once thought of as accelerators before being integrated and ubiquitous). For Intel, this has evolved over time, up to current examples like the Xeon Phi, which integrates high-throughput components that make it optimized for key workloads in HPC. The point is, the FPGA element is a next step toward workload acceleration—one that has a diverse array of possibilities market-wise. Among these areas are the hyperscale and cloud segments, which might be poised to become the great proving grounds for Intel and Altera’s FPGA experiment in acceleration at both the application and node levels.
Fast Packets for Big Clouds
It is not easy at this point to discern how the large cloud providers are looking at the potential for FPGAs, although it is safe to say they are likely well aware of the acceleration it can play in diverse workloads in machine learning and other applications, but also on the node. For instance, we have long been aware of Microsoft’s attention to FPGAs, particularly with the use of the acceleration on their Bing search engine. However, not long ago, the Microsoft’s CTO for the Azure group, Mark Russinovich discussed how Azure could leverage smart NICs with FPGAs to boost packet processing.
As Russinovich said in June at the Open Networking Summit, perhaps tellingly in terms of directions for other large cloud providers, “scaling up to 40 Gbs and beyond requires significant computation for packet processing. To help us scale up without consuming CPU cycles that can otherwise be made available for customer VMs, Microsoft is building network interface controller (NIC) offloads on Azure SmartNICs.” The cloud CTO says that although FPGAs have not yet been widely used as compute accelerators in servers, his team is actively using them to “enable rapid scale with the programmability of SDN and the performance of dedicated hardware is unique in the industry.”
The key for large cloud providers, and of course, for general purpose users elsewhere is going to be programmability, portability, and flexibility. These aren’t terms that one would naturally choose to pull to describe FPGAs, but this is where Intel (through its own chip business and HDL experiences) has worked for years while Altera spent its own toiling away at many of the same problems.
Of course, cloud providers alone are not the sole recipients of developments on the FPGA and accelerator fronts. Both Gara and Stickland referenced a number of application areas in high frequency trading, scientific computing, network compression, storage cryptography, media transcoding and other areas of future focal points for development, fed in part by a range of existing tools—from Intel’s Data Plane Development Kit to its QuickAssist tools for hardware-based acceleration of the encryption and compression sides.
Central to the talk today was Altera’s Mike Strickland’s overview of something new and interesting around beefing up the programming approaches for FPGAs via an OpenCL to HDL converter. On that note, and if you pop up to the slide above, it is apparent that the programming environment is evolving. As we have already described in the past, there is an OpenCL compiler that handles a great deal of the heavy lifting on the backend, which Strickland says will let FPGAs open to a broader base beyond OpenCL, including OpenMP. “Some of our users are comfortable writing the HDL blocks and they can still do that now, but mix and match that with OpenCL (and eventually OpenMP) kernels. There is a new flexibility here.”

Intel Rounds Out “Granite Rapids” Xeon 6 With A Slew Of Chips
It is no secret that chip maker Intel is having a tough time these days on a number of fronts, but it is important to remember that nearly two out of every three processors sold into the datacenter are Intel Inside. This is a good business that can be moderately …
HPE Upgrades Supercomputer Lineup Top To Bottom In 2025
If you want to buy an exascale-class supercomputer, or a portion of one so you can scale up, there are not a lot of places to go shopping because there are not a lot of companies who have a balance sheet that is big enough to get all of the …

It’s Back To The Future For Omni-Path InfiniBand
People in the modern era sometimes forget that networking predates the rise of Cisco Systems and the commercialization of the Internet. Long before there even were routers and switches as we know them, there were intelligent subsystems and controllers that linked computers to each other, to end users, and to …
Will be interesting to see how they will get OpenMP on FPGA. Unlike OpenCL, OpenMP is just preprocessor syntax on top of a host language like C,C++ or Fortran not a full language or API by itself so I wonder how that’s going to work.
I started coding on FPGAs 6 months ago, I too think that there is a massive growth potential for a new range of applications. A SoC with an Intel core + a FPGA sounds amazing for big data applications! I don’t like HDL tough, it’s too complex. OpenCL/OpenMP kernels are a solution… but close source and Altera only. I hope that Intel will also features solutions like Synflow or myHDL.
I’ve been designing with FPGAs for near 30 years. All the new people discovering this technology make me laugh. It’s not easy to “program” FPGAs if you don’t have a background in digital logic design. Sorry is a fact. No matter the spin the marketing people put on it with OpenCL, blah blah blah. Anyone hiring a software engineer to “program” FPGAs will learn the hard way.