

When a top-ranked supercomputer falls from the number one spot, the world tends to stop taking notice, even if those machines remain some of the most remarkable due to architectural, power, application, or other features.
Although it made big waves when it entered the list, stealing the top slot, some of the attention around the machine has dwindled, especially in the wake of the massive Chinese Tianhe-2 system. Even still, the quieter, but not less important story, is that it continues to prove fertile ground for some valuable lessons in advance of the next wave of Department of Energy machines set to start entering the stage in 2017-2018.
When the Titan machine emerged at the peak of the Top 500 list of supercomputers it was one of the first to leverage so many GPUs for a single machine. In fact, there were so many GPUs on a single system that at the time, some expressed concern that hosting over 18,000 GPUs was a recipe for widespread failures and worse, that it was wasted money since there would be too few codes that could take advantage of so much acceleration.
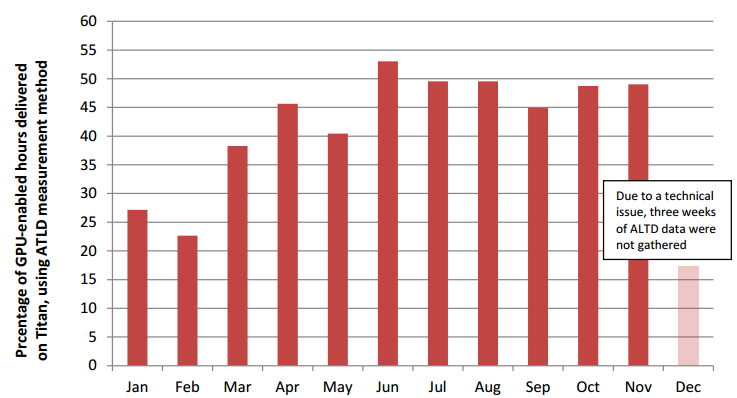
As Titan enters its third year of operation, these initial worries have proven to be unfounded, says Buddy Bland, project director at the Oak Ridge Leadership Computing Facility. While it is not realistic that all codes would be leveraging GPUs, around 50% of them do—a number that keeps increasing due to work done at their Center for Application Readiness and will feed into continued efforts to prepare a new generation of codes for the upcoming Summit supercomputer, set to arrive at Oak Ridge National Lab in 2018.
According to Bland, the stability of Titan, even with all of its GPUs, has proven to be better than it was with the CPU-only Jaguar system that was later upgraded to Titan. “The system is much more stable than we anticipated with the GPUs. When we were developing the machine, we heard all kinds of horror stories about the machine crashing and not running long hours. We worked hard with Cray and Nvidia to put in changes to the hardware, some at the last minute, to add stability.”
Although the team at Oak Ridge will need to wrap their brains around many of the new file system and operational differences in the jump from a Cray GPU machine to the upcoming Nvidia, IBM and Mellanox supercomputer that will serve as Titan’s successor, Bland says that this has been going smoothly and will leverage the work they have done at the Center for Accelerated Application Readiness (CAAR) to apply GPU lessons to the new architecture. These are new investments in a different architecture, but Bland says he expects the returns to be clear on a far more capable machine.
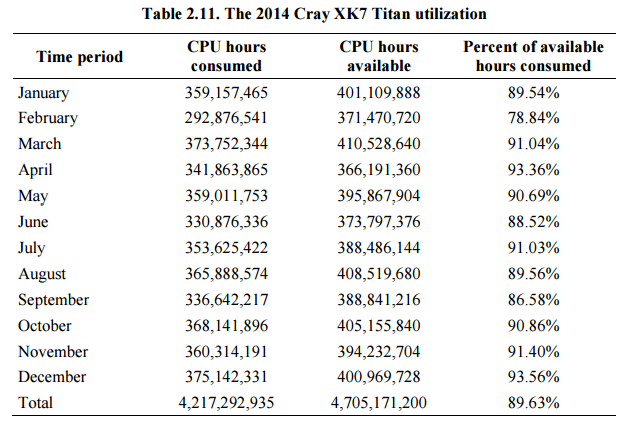
On that note, determining the return on investment for a machine like Titan (or any large-scale scientific computing resource) is difficult, Bland says, although he does say the team at ORNL’s Department of Energy sponsors are pleased with what the machine has been able to prove out over the years. Utilization is close to 100% and there is a constant backlog of jobs. Bland says that for their DoE reports they state 90% utilization due to the fact that there are often large jobs that take the most of the machine and block out smaller jobs. Further, the energy efficiency of Titan has been a positive surprise.
“We projected it would use more power than Jaguar, even with the same number of nodes and same cabinets, cooling system, and cabinets—all we did was replace the boards and the interconnect network inside,” Bland explains. “With Jaguar we were using around 8.3 megawatts for our Top 500 LINPACK run, but with Titan on a daily basis with the same number of nodes, more memory, and faster processors, we’re running at between 5-6 megawatts daily.”
To be fair, this is not an apples to apples comparison since the Jaguar number is for LINPACK and based on a full-system all-out run using around 10% more power, but nonetheless, Bland says this was one of the most pleasing surprises for the Titan team—and is largely due to the GPU acceleration. It is not just about an efficient performance boost for applications either, a benefit at scale has been the ability for the GPUs to spin down to an almost zero power state when they are not being used and can switch back on very quickly when needed again, something that CPUs don’t do well—and not without help from the OS.
Even though there are several GPU-boosted systems on the Top 500, they are certainly not the majority. “They are not deployed at a lot of computing facilities because people are scared of them; they’re not going to run, they’re going to crash all the time, they’re hard to program—that is all bunk.” Granted, he says they did not run well “out of the box” but after work between Nvidia and Cray, the system runs great, Bland says, and serves as a testament to the power of GPUs on the power consumption and performance sides and now, following work at CAAR on codes for both Titan and the upcoming Summit machine, he says it is safe to say they have been proven out at the application breadth and functionality level as well.

Be the first to comment