
In-memory databases are all the rage for very fast query processing, but you have to have the right balance of compute and memory for queries against in-memory databases to really scream. Sometimes, a large number of relatively small cores and a reasonably beefy chunk of RAM can radically outperform clusters with hundreds or thousands of server nodes running parallel analytics platforms based on Hadoop or in-memory architectures. This is apparently the case with a forthcoming product called MapD, which is a massively parallel database and visualization system with an interesting history.
MapD was founded by Todd Mostak in September 2013 after he had seen some impressive performance results with a GPU-accelerated database he created as much out of frustration as curiosity to help him do research for his master’s thesis. As part of his thesis, Mostak was trying to correlate some 40 million Tweets relating to the Arab Spring revolution in Egypt to voting districts in the country. The idea was to map the tweets and test the idea that people were more radicalized in poorer areas in Egypt; sentiment analysis for ranking the Tweets came from comparing them to forums and message boards.
The system Mostak originally created used a Postgres database and the PostGIS module for geo-spatial processing; he wrote algorithms in Python and some scripts in C to hack it all together. Running queries against this data took hours and Mostak needed it to run faster. He happened to be taking a course on OpenGPL GPU programming at Harvard University, where he was getting his degree, at the same time that he was taking a course on databases at MIT, taught by none other than Sam Madden, one of the co-creators of the Vertica parallel database now owned by Hewlett-Packard. The database course inspired him to think about the importance of analytics, and to he got to work coding the parallel database to run on GPUs.
The blazing performance of this prototype database so impressed Madden that Mostak was asked to join MIT’s Computer Science and Artificial Intelligence Laboratory, where he spent a year refining what would become MapD. Since then, Mostak has secured $2 million in seed funding, including money from Google Ventures and Nvidia, and has been working with his team to get the database closer to compliance with ANSI SQL 92 standards. “There are a lot of little things in SQL that we have not had requests for as yet,” says Mostak, so strict compliance out of the chute is not a necessity.
Interestingly, the MapD parallel database doesn’t have to run on GPUs; it can run on CPUs as well. But the architecture of the database is tuned for massively parallel compute elements and the performance on GPUs is far better than on CPUs with multiple cores and threads per core.
“We do some cool stuff,” Mostak tells The Next Platform. “We compile our queries on the fly with LLVM, generating intermediate codes, and we can target Nvidia GPUs and Intel and AMD CPUs. AMD GPUs are on the roadmap with future support for AMD’s Spear backend, and Intel’s Xeon Phi is on the roadmap, too.” So are 64-bit ARM-based CPUs, by the way.
In its current incarnation, the MapD database can be deployed on a single server node with up to eight of Nvidia’s top-of-the-line Tesla K80 coprocessors, which are rated at 5.6 teraflops at single precision per card with a GPU Boost turbo pushing up the clocks and the performance to 8.74 teraflops. Each Tesla K80 has two of Nvidia’s GK210 GPUs plus 24 GB of GDDR5 memory (12 GB per GPU, with 240 GB/sec of memory bandwidth each). Add up that memory across eight Tesla K80s, and the MapD database has 192 GB of total memory to play with for a partitioned database.
“We hold the hot data in GPU memory, and for the data that doesn’t fit in there, the server should have anywhere from 512 GB to 1 TB of main memory as a cache for the GPU memory,” explains Mostak.
One of the barriers to adoption for GPU-accelerated databases is relatively limited size of the memory capacity on the GPU, and it is natural to think ahead to how Nvidia’s NVLink technology, which will couple GPUs more tightly together and to CPUs equipped with NVLink ports. And as Mostak points out, InfiniBand network cards almost have the same bandwidth and low latency as the PCI-Express bus when using Remote Direct Memory Access (RDMA) protocols, and the day is not too distant when inter-node communication will be very fast.
“It depends on the algorithms,” says Mostak. “Certain queries have a low cardinality, such as GROUP BY US state or something like that. The interconnect is never really going to be the bottleneck there because you are shipping around 50 states. It is really with distributed joins that you want to maximize the bandwidth between the coprocessors. But there is plenty you can do without being multi-node or even multi-GPU. With all of the talk about big data, it doesn’t have to be petabytes of data to solve an interesting problem. We have a beta test going on at a large social media company with many petabytes of data, but at any given time, it needs to be half a terabyte running MapD, at most.”
The MapD database is a columnar data store, so it has data compression techniques to make that GDDR5 memory on the GPUs go further. With a columnar store, you don’t have to cache all of the columns in the database in the GPU memory. If you have a table with 50 or 100 columns of data in total, you might only use a tenth of these in a query and only these get moved in from CPU RAM. On top of that, using simple Hoffman encoding, Mostak says you can get another 2X to 3X compression on the data, which moves the effective working set on a group of eight K80 accelerators to somewhere around a half terabyte – the magic spot that social media company mentioned above needs. The data has to be partitioned across those eight GPUs, to be sure, and that is also a limitation for certain kinds of workloads.
The MapD database is written in C++ and hooks into CUDA or OpenCL environments to talk to the GPUs and SQL queries are compiled down with LLVM. It is much more sophisticated than the original effort by Mostak.
MapD is not just a parallel database that runs on GPUs, it is also a visualization system that runs on those same GPUs, and this is one of the secrets of the program. Because it is rendering data on the same devices that is doing the calculations on that data, there is no data movement at all. That means visualization also happens very fast. This visualization system in MapD is based on the D3.js JavaScript library, and OpenGL is used to visualize the data that D3.js displays in a Web browser.
The company is just putting out some initial performance specs on the MapD database, and in early tests against an in-memory database doing the same SQL queries, MapD has been as much as 1,000X faster. “We are approaching the maximum database scanning rate on the Tesla K80 GPUs, which is something on the order of 3 TB/sec to 4 TB/sec,” says Mostak. “A lot of in-memory databases are lucky to hit 1 GB/sec to 2 GB/sec. Those databases may not be optimized for scans – they do a lot of other things well. But we are very, very optimized for scans because we feel that indexes can only take you so far and ultimately with visual analytics you are going to have to touch a lot of data.”
On a 1 billion row dataset, Mostak says that MapD can process SQL queries in around 10 milliseconds to 20 milliseconds. The data ingest for the system is very fast, too, which is important.
Ahead of the launch later this fall for MapD, Alex Suhan, an engineer at the company, and Mostak just released some initial benchmark test results comparing MapD to an unnamed in-memory database.
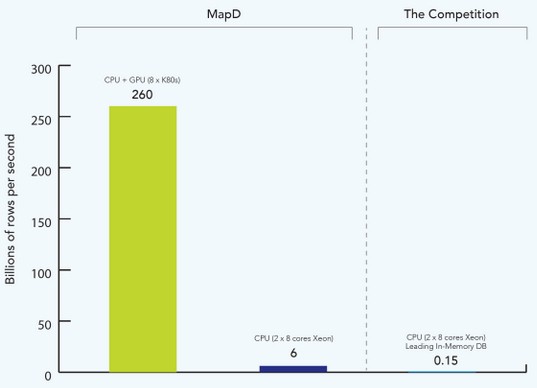
The particular test shown above is using GROUP BY and WHERE filters on the SQL query, and the chart shows the scan rate in billions of rows per second. Unfortunately, MapD is not naming the in-memory database it is running on a two-socket server with that can only scan 150 million rows per second. This particular machine was a two-socket Xeon system of unknown vintage using eight-core processors. Just for fun, MapD ran the same test on the same node using its parallel database software and was able to process 6 billion rows per second, a factor of 40X improvement. Partitioning the data to run across sixteen GPUs on eight Tesla K80 cards boosts the scanning throughput to 260 billion rows per second, which is a factor of 6.5X times higher than the MapD code running only on Xeon cores and a factor of 1,733X higher than the unnamed in-memory database running the test in the same CPU-only system.
Without getting into the details, Mostak said that an earlier prototype of the MapD parallel database for GPUs has been completely rewritten and this is the new code base – somewhere around 70,000 lines of code –has gone into beta testing. Mostak hopes to have MapD ready for production use and sales in the late fall. The company is working on a desktop version that will make use of GPUs inside of PCs and laptops and be suitable for databases with maybe 100 million rows instead of billions of rows of data.
Pricing has not yet been formalized, but MapD expects to sell under an appliance model with preferred configurations and suggested pricing. Given the speedup, expect a reasonably high price tag. And those GPUs are not cheap, either. So the price/performance gap will probably not be anywhere near as large as the performance gap–maybe something on the order of 100X. Two orders of magnitude better price/performance is going to not only raise a few eyebrows, but get a few companies to give MapD a whirl.

Nvidia Gooses Grace-Hopper GPU Memory, Gangs Them Up For LLM
If large language models are the foundation of a new programming model, as Nvidia and many others believe it is, then the hybrid CPU-GPU compute engine is the new general purpose computing platform. After years and years of having others build these hybrid machines based on its high-end SXM streaming …
AMD Builds Out Its AI Software And Services Stack With Silo AI Buy
You can build a software ecosystem if you have time. But sometimes, you want to speed things up, and then you have to pay to build that ecosystem out. And that is precisely what AMD has been doing for the past year, and what we expect the company to do …
Cerebras Shows Off Scale Up AI Performance For Big Pharma And Big Oil
Historically, the largest organizations in the world – the Global 2000 plus the biggest national government and academic research institutions – have always had the most complex data processing needs. And by virtue of the size of their IT budgets and the sophistication and scale of their workloads, they get …
Price/performance improvement of 100x is highly unlikely imho – but even 10-20x would be a major achievement.
I’d be happy to be proven wrong on this.
Is there any plan to support remote GPUs in MapD over fast low latency networks (50-100GbE w/RDMA) using rCUDA etc.)? That may increase data size that fits in GPU memory at least 3 times.
I should have really pursued that idea from 2008! Here’s a blog post I did about this back then:
https://unhandled.wordpress.com/2008/02/27/gpu-accelerated-databases/