

The engines at the heart of relational database engines are broken, and Deep Information Sciences, which is uncloaking from stealth mode today, thinks it has come up with a way to fix them. The upshot of the new Deep Engine, which has been under development for nearly five years and which can be plugged into MySQL databases and soon other relational databases and various datastores, is an order of magnitude better performance on various database tasks and scalability that stretches to over one trillion rows in a single instance.
MySQL may not generate the billions of dollars per year that commercial-grade relational databases from Oracle, IBM, and Microsoft do, but it is arguably the most popular database in the world if you could installations. The trouble is, MySQL does not really scale all that well, which is one reason that hyperscale companies created NoSQL and NewSQL alternatives. Facebook created the Cassandra NoSQL datastore for precisely this reason, and it still manages the largest MySQL database cluster and the largest Memcached cluster in the world because you have to pick the right tool for the job.
These NoSQL and NewSQL alternatives usually sacrifice one or more of the ACID properties of the relational database – chant them with me: Atomicity, Consistency, Isolation, Durability – to scale out their performance or capacity or both. Thomas Hazel, the founder and chief architect at Deep, took another approach to goosing the speed and scale of relational databases.
Cutting Down The B+ Trees
“The problem with databases, even modern iterations and including Oracle and SQL Server and NoSQL and NewSQL, all of are based on the same algorithms – B trees, B+ trees, and LSM trees – all of which was invented in the late 1970s and early 1980s,” explains Chad Jones, chief strategy officer at Deep, who was brought into the company after it secured $10 million in Series A funding back in April 2013 to commercialize the technology that Hazel has invented. “As things progressed, MySQL was built on technologies from 1995, but that was on Pentium Pro machines that did not have the modern architectures that we see today. A lot of the technologies that are in the database engines that slide under MySQL are really just wringing out the performance of this legacy computer science. MySQL can scale to a certain extent, but boxes become I/O bound long before they become CPU bound, so you can’t really make use of this hardware.”
The typical MySQL server has something on the order of 15 percent to 20 percent CPU utilization with the I/O maxxed out on a node; the highest sustained CPU utilization we have seen for commercial-grade databases on big NUMA boxes running DB2 or Oracle databases are in the range of 40 percent CPU utilization. Clearly, there is some CPU that can be put to good use.
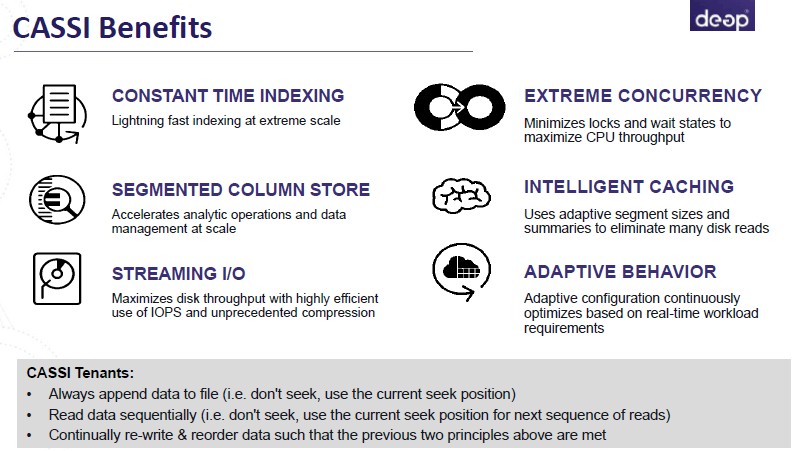
That is, in part, what the Deep Engine database engine is doing. The algorithms inside Deep Engine that Hazel has created replaces the tree structure that is still embedded inside relational databases with a set of machine learning algorithms that adapt to conditions in the database as it is running, extracting more performance out of the hardware rather than using hardcoded routines that provide a kind of average performance profile over very different database tasks. (These algorithms are collectively known as CASSI, short for Continuous Adaptive Sequential Summarization of Information.)
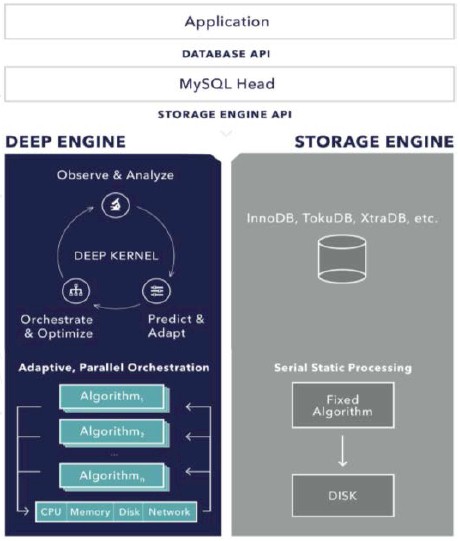
The Deep Engine is only 10 MB in size – about the size of Lynyrd Skynyrd’s Freebird, as Jones put it – and can accelerate applications that thwack against MySQL and its several clones, including Percona Server, MariaDB, and perhaps even WebScaleSQL, the hyperscale variant of MySQL that Google, Facebook, LinkedIn, and Twitter created a year ago. Deep Engine, says Jones, is what amounts to a database kernel and an information orchestration system based on machine learning techniques so that the static way information is moved from memory to disk or flash, for instance, can be handled in different ways, in a dynamic rather than static fashion, as conditions in the system and the database load dictates. The on-the-fly optimization of database reads and writes is not just done for the specific hardware that the database is running on, but is also adjusted for the manner in which data is being requested at the time.
“We have separated the database structure and its behavior from each other,” Hazel tells The Next Platform. “The B+ trees and the LSM trees are fixed structures, and a database administrator will come in and reconfigure those structures to best meet the workload. Since we have actually separated that behavior from the structure, we can use the heuristics in the machine learning to look at what the CPU, memory, and I/O actually adapt and actually organize the data in memory and on disk to meet that workload. DBAs have made a lot of money in recent years doing this, but Deep Engine autotunes and autoconfigures right out of the box. And because these machines run out of I/O first, we use the compute and memory of these systems to organize, defrag, and compress the data to use as little I/O as possible for each write and read.”
The other interesting thing about Deep Engine is that it can get the same kind of high transaction rates and low latency as in-memory databases, but the information is actually persistent on disk as it is stored in MySQL. Deep has tested against VoltDB, the in-memory relational database created by database legend Michael Stonebraker, and has been able to sustain similar transaction rates for MySQL. (The performance data is not yet released.) The MySQL-Deep Engine combination can also be run in-memory if customers need to push the transaction rates up and the latencies down even further.
The performance differences can be quite large for the Deep Engine running in conjunction with MySQL. The company has been able to generate transaction rates as high as 64X that of MySQL using the InnoDB engine controlled by Oracle. Other MySQL engines that offer higher performance than InnoDB are still getting beat by Deep Engine by a factor of 4X to 10X, depending on the engine and the test. (This is all for single node database performance, by the way, without requiring database clustering or data sharding. This is what we at The Next Platform call scale-in performance, which means making the same iron go faster, as opposed to scale-out, which means replicating systems to goose performance, or scale-up, which means building a bigger system to get more oomph.)
For data ingestion, Hazel says that a single node running the Deep Engine underneath MySQL can do the work of seven nodes running Hewlett-Packard’s Vertica parallel database. These tests had machines revved up to ingestion rates on the order of 3 million to 5 million records per second with heavy indexing, and the Vertica database has to shard the data to reach those performance levels. That Vertica system, says Hazel, would require around $1.5 million in software licensing fees, compared to tens of thousands of dollars to license the software for Deep Engine.
To show the top-end performance, Deep will be on hand at the Percona Live conference next week, and will be showing off a single server that uses 5,400 RPM disk drives that can process over one million inserts per second, with heavy indexing no less, against a database with more than one trillion rows. Let me say this again: That is all on one machine, and in one table, all driven by 25 MySQL clients trying to pump bits into rows in the MySQL database as fast as they can.
“Since we have actually separated that behavior from the structure, we can use the heuristics in the machine learning to look at what the CPU, memory, and I/O actually adapt and actually organize the data in memory and on disk to meet that workload. DBAs have made a lot of money in recent years doing this, but Deep Engine autotunes and autoconfigures right out of the box.”
Not only does Deep Engine boost the performance of MySQL, but it reduces the disk capacity needed to run MySQL by around 30 percent on uncompressed data, and for compressed data, it reduces it by 80 percent. That factor of 5X reduction in disk storage can have a big impact on the capital expenses for database servers. While the Deep Engine can benefit from solid state disks, this has not been a focus during development. “We like to say we make HDDs look like SSDs without the high cost,” says Hazel.
For those who need more database oomph than a single node can provide, Deep Engine is architected to work with MySQL Fabric, the high availability and database sharding add-on to the popular database.
Databases that have a plug-in architecture like MySQL can in theory have their database engines swapped out and replaced with the Deep Engine motor. At the moment, the open source MySQL and Percona Server variants are supported, running atop Deep plans to have a variant out the door by the end of the year that slips underneath the MongoDB NoSQL database, which has a plug-in architecture. The Deep Engine will also eventually be put underneath the PostgreSQL database, which is nowhere near as popular as MySQL in hyperscale and enterprise uses, but which has its niche.
Deep is packaging and pricing Deep Engine for wide adoption and is taking a long view on generating revenues. There is a community version of Deep Engine, and this is free and intended for developers to use for database testing. The standard version of Deep Engine is also free to academic institutions and commercial entities that have under $1 million in revenues, with the idea being to seed Deep Engine into the next wave of Internet giants and capture the money later. The enterprise version of the database engine is aimed at companies with more than $1 million in revenues, and while Jones is not divulging the price, he did tell The Next Platform that it is “not even close to $10,000 per machine” and he hopes companies will be able to go “from zero to Facebook without having to rearchitect.”


The Cloud Outgrows Linux, And Sparks A New Operating System
Ultimately, every problem in the constantly evolving IT software stack becomes a database problem, which is why there are 418 different databases and datastores in the DB Engines rankings and there are really only a handful of commercially viable operating systems. But what if the operating system is the problem? …
Oracle Runs OCI Clones At Rival AWS, Google, And Azure Clouds
It’s a multi-cloud world and one with a cloud infrastructure services market that is dominated by three large players. If you’re one of those cloud services providers that is not among the big three, how do you expand the reach of your own cloud offerings? Well, on strategy is that …
Databricks Is Going To Be The Next Platform For Many Enterprises
The hyperscalers, cloud builders, HPC centers control the design and manufacturing of own AI infrastructure. They have big bucks, and they can afford to get exactly what they want. For the rest of the world, and particularly large enterprises who cannot afford to start from scratch and who want to …
Trillion rows per table on one server sounds too good to be true.
If that’s what was in fact claimed by Deep, did they specify server hardware specs and/or number of columns and/or uncompressed avg rows size for this trillion rows table?
What kind of queries (except inserts and most basic point or range queries) they claimed to have an acceptable response time against this trillion rows table?
Trillion rows is an impressive number to us too. We tested two machines (one Amazon instance 16 CPU General Purpose SSD with 64G cache, one bare metal 48 CPU HDD 5900 RPM with 128G cache) each to be used to describe Deep Engine’s architect at Percona Live Conference, April 12, 2015 next week. Both machines completed the trillion rows in about two weeks using one table respectively. It’s a simple schema with one primary index totaling around 23 TB of storage. Now we don’t recommend actually storing trillions of items on one machine, but when you think trillion, billions looks much more manageable. We do recommend Deep Engine and billions of rows. At the Percona conference we will also be demonstrating billions of rows per table will many indexes (e.g. IIBenchmark).