

Tis the season for massive supercomputer deals in the oil and gas segment. Just last week we learned of an upcoming five petaflop Cray XC40 system for Norway’s energy exploration ambitions and this morning, SGI released word that it would be building the follow-on to a top-tier supercomputer for French energy giant, Total.
The existing ICE X Pangea machine was the top commercial HPC system on the Top 500 supercomputer list when it was put into production in March 2013. The system was originally outfitted with 110,592 Xeon E5-2670 v1 cores, for a total theoretical peak performance of 2.3 petaflops. While Pangea dropped to #20 on the last incarnation of the list in November, barring any surprises in June when LINPACK benchmark results are published again, it will likely be in the top ten—right above the Cray oil and gas system when it emerges fresh as Pangea 2.
There are a couple of noteworthy elements here, although for those who follow supercomputing, they are not entirely unexpected. First, note that unlike many of the top HPC systems, the Total machine sports zero in the way of accelerators (GPUs or Xeon Phi). Second, the CPU-only machine is packing almost twice the compute in the same number of cores, and this is possible because of the FMA units in the “Haswell” Xeon E5 v3 chips, which can do 16 double precision flops per clock per core. The “Sandy Bridge” Xeon E5 v1 processors could only do 8 flops at double precision per clock per core.
With AVX2 vector processors and their FMA units, SGI can get 4.4 petaflops for Total with the addition of 4,608 nodes—bringing the total core count to 221,184 with the addition of this most recent 110,592 cores. (There was some confusion because SGI’s press release on the machine suggested the original Pangea 1 machine had a 10-core Ivy Bridge processor, which it doesn’t). So we put this table together to get it all straight.
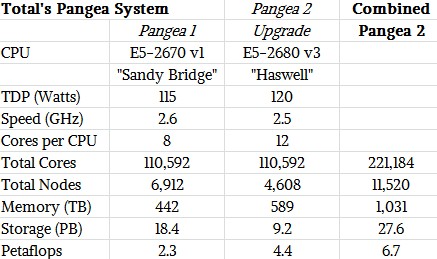
The first column shows the original Pangea 1 system with the correct processor and other feeds and speeds. To make Pangea 2, Total is adding this other set of nodes and cores to it. There are 4,608 nodes of Haswell Xeon E5 servers and while the core counts are the same, adding the two machines together creates the new system— making a total system with 6.7 petaflops. (We did not take into account the FMA units in the AVX2 vector processors in the Haswell Xeon E5s, which is why we thought the machine topped out at only 4.4 petaflops.)
These are, and we’ll get to this more in a moment, no different engineering-wise than the ICE X system that was installed in 2013—it’s more of a processor refresh. This is part of the reason why SGI’s Bob Braham said the talks about who would get the contract for the refresh boiled down largely to who could make the best deal. Considering Total has been an SGI customer for close to a decade, was the original vendor on this massive machine, it’s not a surprise, but the refresh was anything but a shoe-in for SGI.
With that said, to keep up with addition of compute, the system has been outfitted with an additional boost in memory, adding 589 terabytes to the original 442 terabytes, creating over 1000 terabytes–basically a petabyte of memory. The original 17,000 arrays behind the SGI InfiniteStorage also saw a jump by 9.2 petabytes running across an Intel Enterprise Edition Lustre file system with and distributed with SGI’s DMF tiered storage virtualization. The initial installation included roughly 4 petabytes of tape, but it was not clear if that was also bolstered.
For many oil and gas HPC system purchases, the interconnect is a key differentiator. SGI has a number of options in the ICE X system in terms of Infiniband topologies, including an fat tree and all-to-all (probably not the best choice for a cluster this size), standard hypercube is appropriate for a high node-count and MPI-dependent machine like this. SGI has its own “enhanced hypercube” that allows users to tap into more switching ports to add more bandwidth to the system. While SGI was not explicit how Total made this decision, Paul Kinyon, HPC Product Server Manager at SGI said, “As far as keeping the cost down, we figure out which code is the best price performance for the application being run. If you’re asking how we can compete with a company with a custom interconnect, it doesn’t just need to be ‘raw’ faster, it needs to be application faster per dollar.”
With all of this performance so densely packed, the power and cooling is critical—a defining factor for Total when they evaluated the system refresh and overall TCO, according to Braham. The whole system needs to run inside of 4.5 megawatts, up from the 2.5 megawatt window opened for Pangea’s first generation. “Closed-loop airflow and warm water cooling create an embedded hot-aisle containment, which lowers the cooling requirements and energy draw,” Braham said. Specifically, this comes from some custom engineering on SGI’s part. Called the M-Cell, this allows for extra density over previous ICE X machines.
With the company’s IP-115 blades, up to 9 power supplies can share a single 12 watt power bus bar. The interesting feature on these blades are the cold sinks designed for high frequency processors, which turn the concept of heat sinks on its head a bit by adding liquid-cooled plates just between the sockets on the top and bottom nodes. The liquid runs through the planes, one after another, then into small pockets in the enclosure, absorbing what SGI says is between 50-60 percent of the heat that floats off a regular dual-socket node without this feature. There is still bound to be heat left over and this is cooled by air in a unique closed-loop airflow system that’s been built into the M-Cell.
Recall that this system was part of an approximately $70 million deal, which included the funds to spin out Pangea two with double the performance. As The Next Platform’s Timothy Prickett Morgan speculated back when the first Pangea system was fresh, if you assume that the compute portion of Pangea is about a two-thirds of the cost, and about two-thirds of the total cost of the computing is in the initial system, with a third going into the upgrade, then Total is getting Pangea for around $15,000 per teraflops, and the upgrade to double the performance in 2015 would cost half that. (The plan as we understood it two years ago, when Pangea 1 came out, was to double performance of the machine, not to triple it, which is why we thought the 4.4 petaflops number was correct for the whole Pangea 2 machine and the 6.7 petaflops figure was wrong. Total got a much better deal in the end from SGI, which is the important thing.)
Some interesting observations. Pangea 1 and the Pangea 2 add on both had the same number of Xeon cores, but what a difference two generations of Xeon chips makes. By moving to twelve-core Haswell Xeon E5s, Total could get 1.9X the raw peak double precision performance in a third fewer processor sockets, which means a third fewer nodes and racks. While the Haswell Xeon E5 had a 12 percent higher list price (no one knows what Total paid for the processors), at list price the processor costs drop by 25 percent thanks to the node count shrink and the total watts consumed by the chips (as gauged in thermal design point, or TDP, rating from Intel) dropped by 30 percent. The result is that the cost per petaflops, when measured at just the CPU level, dropped by 61 percent. This is a big price/performance jump.
While HPC competitor Cray had its day in the sun last week, SGI had another large system enter the potential Top 500 ranks with another ICE X system win, this time for Japan’s National Institute of Materials Science. This 25,056 core system (1,044 nodes) also sports the E5-2600 v3 (Haswell) family of processors.

Pangea2 is 4.2PF peak, (2.1×2, the x2 from FMA in Haswell). So the total PF for final pangea is 6.5PF in theory.
SGI sent us a note and has corrected their release about the system–we had different specs from them and Total was in limited reach as we were writing this up. Thanks for the insight, the article has changed a bit since when you originally posted this comment.