

For the past two decades, Intel has taken on the processor makers for servers and storage in the datacenter and vanquished all but a few suppliers of alternative architectures from the glass house. With several aggressive suppliers of ARM processors ramping production this year and Intel having its own aspirations to take a bigger chunk out of the networking space with its Atom and Xeon CPUs and various network ASICs, the last thing that you might think Intel would do is veer off on a tangent and spend a lot of money on Altera, one of the two dominant makers of malleable chips called field programmable gate arrays, or FPGAs.
But the rumors running around right now suggest that Intel is indeed in talks to buy Altera, as reported by the Wall Street Journal last Friday. This is not the first time such a deal has been whispered about. Ever since Altera partnered with Intel to use the PC and server chip giant as a foundry for its FPGAs back in February 2013, tongues have been wagging that eventually Intel would just get out the checkbook and acquire Altera, thereby expanding its presence in the chip space.
It would have been far cheaper for Intel to have done such a deal back then or before the WSJ story broke on Friday morning for sure. For the past several years, Altera’s market capitalization has wandered sinusoidally between $9 billion and $11.5 billion, and after the Intel acquisition rumor broke last Friday, the company’s value rocketed up 28.4 percent to $13.4 billion. Any deal will have to command a premium over this level, and the fact that Altera is sitting on nearly $5 billion in cash and investments with only around $1.5 billion in debts will push the price higher. If Intel does do an Altera deal, it will be its most expensive ever, probably at least twice the $7.7 billion price tag it paid for security software maker McAfee.
Call it somewhere between $15 billion and $17 billion, just for argument’s sake. Why is a maker of FPGAs that generated only $1.93 billion in revenues and $472.7 million in net income worth so much money? The reason would be that Intel sees some big changes coming in the landscape for computing in the datacenter, in wireless and wired networks, and in client devices on the horizon that it cannot address with its Atom and Xeon processors or its various network ASICs. Computing is going hybrid, and more and more systems are being tailor made from a variety of components that often include general purpose X86 processors but are not restricted to them. The relative homogeneity of the datacenter that was caused by the dot-com boom and the rise of the hyperscalers is being undone, workload by workload, by hybrid computing that often mixes several types of computing and programming models into a single system.
“FPGAs are a much better device to use in the datacenter for hardware acceleration, and certainly in many cases are much better than a GPU and, due to its very low power, a CPU,” Altera chief financial officer Ron Pasek told Wall Street at the annual Credit Suisse technology conference in December. “A year ago, when we were talking about this, it was not resonating at all, and since then some major announcements have helped people understand the opportunity.”
This certainly fits with what we at The Next Platform have been hearing. As we report elsewhere this week, a new data analytics appliance maker called Ryft is making waves by using FPGAs to do some common search and term frequency algorithms on a single node that take hundreds of nodes using Spark.
To be sure, big financial trading firms have been using FPGAs for a long time – in systems, embedded in network interface cards, or inside of switches –to accelerate relatively static functions like handling market data feeds and parsing them for applications. Sometimes they use FPGAs to run Monte Carlo simulations, and we know of one company that has an entire high frequency trading system implemented on FPGAs. As is often the case, the oil and gas industry was out in the front of the accelerator wave, experimenting with FPGAs, DSPs, and GPUs as they became commercialized. And now, it is beginning to look like FPGAs could take off in the clouds, making it a lot easier for enterprises to experiment with them and deploy applications on them.
Intel Cozies Up To The FPGA
Last June, Intel announced that it was working with an unnamed FPGA supplier – which is almost certainly Altera – to create a hybrid Xeon-FPGA chip that will plug into a single processor socket. The disclosure by Diane Bryant, general manager of Intel’s Data Center Group, did not say much about this hybrid device but did indicate that it would be aimed at very high end and sophisticated customers looking to accelerate their Xeon workloads. “These folks know exactly what they need to accelerate their workloads,” Bryant explained. “This has been an evolving, continuous process from general purpose to system on a chip to fixed function accelerators, which we launched a few years ago, and now to a flexible, customized FPGA.” The interesting bit was when Bryant said that FPGAs “can give 10X, 20X, or 30X performance improvements, and by moving it into the Xeon package, it will double the performance again.”
We believe that CPU-FPGA combo will marry a future Altera FPGA etched using Intel’s 14 nanometer processes to the future “Broadwell” Xeon E5 processor due later this year. (That FPGA will probably not be mated to the just-announced Xeon D processor, which is also manufactured using the same 14 nanometer processes as the future Xeon E5 and the future Altera Stratix 10 FPGA.)
The disclosure that Intel was working on a hybrid CPU-FPGA product came only three months after Intel and Altera expanded their original fab agreement, moving from simply making Altera’s future high-end Stratix 10 FPGAs in 14 nanometer processes to creating system-on-chip (SoC) parts using those FPGAs that merge in components such as DRAM, SRAM, custom ASICs, and various kinds of processors and analog devices. The two have suggested that they can leverage the research and development that Altera has done in 2.5D and 3D chip stacking to cram all of these components onto a single package.
Altera and Xilinx have been selling hybrid SoCs that mix ARM cores and their FPGAs for many years, so this is no new thing for them. What is new for Altera is putting an FPGA right into the package and having it link to the Xeon processor through some sort of coherent link. The Xeon D processor does not have QuickPath Interconnect (QPI) coherent links as far as we know, but the future Broadwell Xeon E5 will, and it would be a relative snap to take a single Xeon E5 with two QPI ports and use one up linking to the FPGA.
Here’s the thing to remember about Intel: The company has two competing interests.
First, it wants to maintain and extend its Atom and Xeon franchise for computing and use that vast installed base of software coded for the X86 architecture to create what is essentially an annuity revenue stream. Second, it wants to maintain its substantial manufacturing edge. With a flat to shrinking PC market (depending on the quarter) and the company not having as much success selling chips into the smartphone and tablet markets and not making much of a dent in the ARM collective there, Intel has to do everything it can to pump up the volumes on its most recent manufacturing processes to keep those fabs running at the highest production rates possible. It is not about chip volumes for their own sake, but rather that high volumes allow Intel to refine those manufacturing processes and extract the most profits possible from those plants more quickly.
Intel CEO Brain Krzanich has said as much. “We are not going to take the large volume, trailing edge customers and have a factory fill kind of strategy,” he explained last September at the Citi Global Technology Conference. “Our [strategy] would be, who could within the same year or maybe a year later at most take the leading edge technology that we have already ‘roto-rootered’ and made sure works and build a product with that, which can really differentiate. That way they can really go and change their markets, but they can also then hopefully make it at a profit so they can pay us a reasonable margin.”

If Intel buys Altera, it is an admission that FPGAs have found a home in the key server, storage, and networking markets and Intel will focus on doing them well and leveraging its chip-making edge to get Altera ahead of rival Xilinx and its foundry partner, Taiwan Semiconductor Manufacturing Corp. (TSMC is the foundry for Altera’s older FPGA parts.)
We can – and will – get into the technical and programming issues of using FPGAs instead of other kinds of compute in future stories on The Next Platform, but not here. For now, suffice it to say we are aware of those issues and let’s just look at some examples of FPGA acceleration that have been made public so you can see the issues that could be driving Intel’s potential acquisition of Altera.
It’s Azure Thing
Microsoft has released details on two workloads accelerated with FPGAs in the past year, and has been helping Altera and Xilinx alike in spreading the FPGA gospel. Here’s how Microsoft sees the spectrum of chippery:
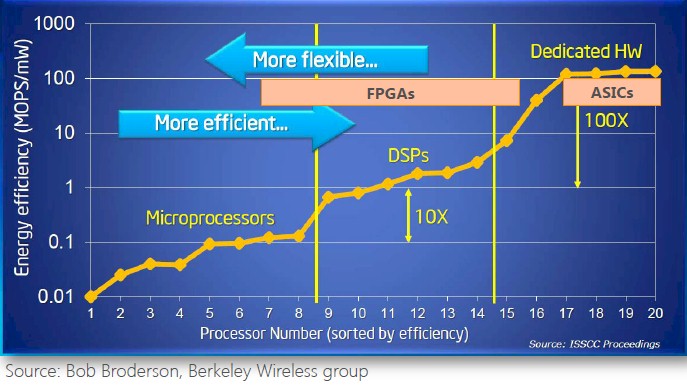
As you can see, there is a constant interplay between energy efficiency and the specificity of compute functions on a chip. Processors are general purpose devices and are more flexible and DSPs and custom ASICs offer gradually more efficiency. (GPUs are not on this Microsoft chart, but they should be.) FPGAs hit the sweet spot between general CPUs and custom ASICs that do very precise tasks, and in the real world, some chips start out as FPGAs and when their products finally get into high production volume, then their functions get implemented in ASICs to lower their cost and improve their performance.
Last September, Microsoft divulged at the Hot Chips 26 conference how it had been experimenting with FPGA acceleration for three years and had come up with a scheme that worked with its Open Cloud Server designs, which have been donated to the Open Compute Project. For its so-called Catapult system Microsoft chose a Altera’s Stratix V D5 FPGAs and put them on a mezzanine card that snapped into the Open Cloud Server nodes. (The card is shown in the featured image at the top of this story.) Microsoft used a very clever network based on MiniSAS peripheral controllers that directly links all of the FPGAs in a 48-node rack to each other in a 6 x8 torus interconnect that is independent of the server network. This hardware was first used to accelerate the page ranking functions in the Bing search engine, and Microsoft found that on a system with 1,632 server nodes, those with the FPGAs installed (one per node) ran the ranking software with 29 percent lower latency and at twice the throughput, with only a 30 percent increase in the cost of a server node and adding less than 25 watts per server, too. This FPGA-accelerated Bing page ranking system is going to be deployed in production this year.
Machine learning techniques applied to image recognition were the hot topic at the recent GPU Technology Conference hosted by Nvidia, and company co-founder and CEO Jen-Hsun Huang showed how a future “Pascal” GPU coprocessor working in conjunction with X86 processors and running a CNN-based image recognition application would be able to offer up to 10X the performance of a current “Maxwell” generation coprocessor. Both systems were trained using the popular ImageNet image database.
In February, Microsoft released a white paper explaining how it had used a modified version of this system to accelerate a convoluted neural network (CNN) that is running its image recognition software. Microsoft tested with the Altera Stratix V D5 FPGAs, but plans to swap them out for the Arria 10 FPGAs, which deliver about 1.5 teraflops of single precision floating math in dedicated blocks on the chip. (The Microsoft research paper says 1 teraflops, but it is wrong.) But here is the gist of why Microsoft is deploying FPGAs for image processing, but you have to read it carefully:
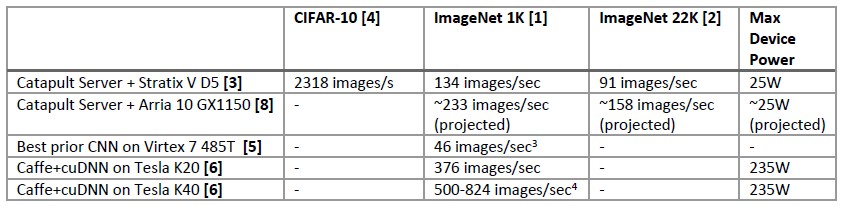
Microsoft ran its tests on a number of different image databases, but the ones that matter are from ImageNet, and Microsoft tested the variant with 1,000 different image classifications and the other one with 22,000 image classifications. While server nodes tested by Google with Nvidia Tesla GPUs and running the Caffe deep learning framework had the most performance, the FPGAs win out based on performance per watt – at least for this particular workload running in Microsoft’s datacenter and at least when only looking at the accelerator device itself. That last bit is the important bit.
However, if you look at it at the server node level – there are two Xeon E5 processors in those nodes, remember – and add all that heat together, the gap is not what it seems to be between the FPGA and the GPU. Let’s do the math.
Microsoft says that the FPGA adds 10 percent to the thermal envelope of the server, so that means the Xeon E5 node in the Catapult system consumes about 250 watts. Add in 235 watts for the Tesla K40 GPU, and you are up to 485 watts, but it can do between 500 and 824 images per second, which works out to 1.03 and 1.7 images per second per watt. The K20 system delivers 0.78 images per second per watt. The Stratix V FPGA in a node with a total of 275 watts per power draw delivers 0.49 images per second per watt, and the expected performance on the Arria 10 FPGA is around 0.85 images per second per watt. The K20 is in spitting distance with the future Altera Arria FPGA on a performance per watt basis.
The thing is, Microsoft doesn’t want to have to modify its Open Cloud Server nodes to accept hotter GPUs, even if they can potentially do more work per node because they throw off a lot more heat per node. The heat and the form factor are big issues here, and that may or may not be the case with all hyperscale, enterprise, or HPC customers. It is also possible to build a server with fewer Xeon sockets and more accelerators and get a better performance per watt measure.
The important thing to note is that the FPGA can definitely hold its own against GPUs. It would have been interesting to see a CPU-only cluster trying to run the same Microsoft benchmark, and it is probably good for Intel that it didn’t. Presumably the numbers would not have been so great, and that is why Intel might be looking to acquire Altera for FPGA acceleration in places where its future “Knights Landing” Xeon Phi parallel processor and coprocessor cannot go because of similar thermal issues.
Networking Might Be More Important Than Compute
Intel has made no secret that it wants its Data Center Group to double in size over the coming years and take a much bigger share of datacenter spending. The company has the lock on CPU shipments with servers, but there is still some revenue to chase. But if Intel was able to destroy the 30 percent or so of the server revenue that was not based on X86 processors, oddly enough it would not create as much of a revenue boost. Intel has been able to get its Xeon and sometimes Atom processors into most storage arrays and clustered storage products and has had mixed results in networking.
According to CFO Pasek, somewhere between 20 percent and 25 percent of Altera’s revenues come from the compute, network, and storage business. Call it $500 million for a nice round number. This maps directly to Intel’s Data Center Group, which had $14.4 billion in sales last year. The Altera contribution is a drop in the bucket, unless you reckon that every accelerated workload costs Intel lost Xeon processor sales. Another 20 percent to 25 percent of Altera’s revenues come from companies that make embedded and defense products, but somewhere between 40 percent and 45 percent of revenues – call it a cool $1 billion – come from sales of FPGA devices to makers of telecommunications gear. This is real money to the Data Center Group, and being able to sell hybrid X86-FPGA compute to such customers could help Intel cope with the ARM vendors who are also talking up their hybrid capabilities and entering the market in earnest this year.
Intel has been willing to spend money to buy its way into the datacenter networking business, but nothing on the scale of a potential deal to buy Altera. Intel got into datacenter networking by acquiring Ethernet switch chip maker Fulcrum Microsystems for an undisclosed sum back in July 2011. (Probably in excess of the $102 million in five rounds of funding that Fulcrum took down.) Then in January 2012, Intel bought the InfiniBand switch and adapter business from QLogic for $125 million. The current 40 Gb/sec InfiniBand products are sold under the True Scale brand and are the foundation of the future Omni-Path interconnect that Intel will ship in the second half of this year. Intel followed this up with a $140 million deal in April 2012 to acquire the “Gemini” and “Aries” supercomputer interconnects from Cray, as we suspect that some of the smarts of the engineers who worked on those products (who have been under the employ of Intel for the past three years) are going into the Omni-Path line, too.
Suffice it to say, Intel has plenty of engineering here. (Although it is not clear if Intel is yet fabbing its acquired networking chips.)
Here is the funny thing about the networking and embedded markets where FPGAs sell well. Most of the ASICs that are used in the markets that compete against FPGAs are nowhere near the leading edge in terms of manufacturing processes. Take a look at this chart Pasek showed, which pits programmable logic devices of all kinds (including but not limited to FPGAs) against ASICs:
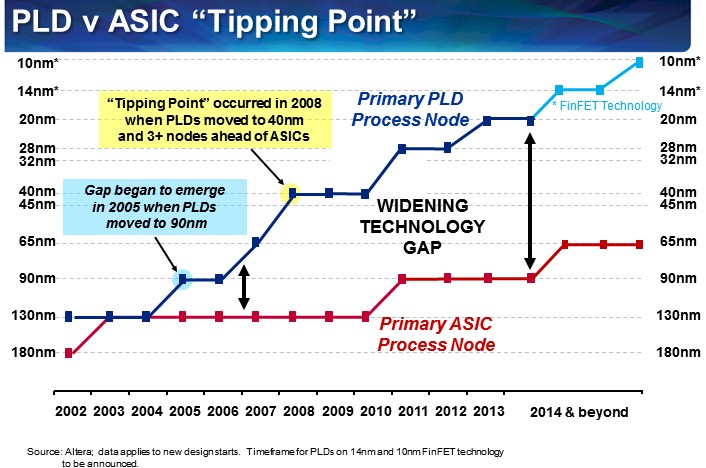
As Pasek put it, as the cost of etching fixed function devices keeps rising, the benefit of programmable logic gets even more compelling. Pasek said that the tipping point where an FPGA was the same physical size as an ASIC happened only six years ago, and that was when FPGAs hit 40 nanometers and the most common ASICs used outside of PCs and servers were at the 130 nanometer node. “We are now at three and four and soon to be five nodes ahead of most common ASICs,” Pasek explained. “The most common ASICs starts are at 90 nanometers and that is because most people can’t afford to do leading edge devices unless they have very high volumes.”
Unless, of course, you are Altera and you get acquired by Intel and your parent company wants to take a bigger chunk out of the $63 billion accessible market for ASICs and ASSPs (similar application-specific chips that are not technically ASICs), which dwarfs the $5 billion market for programmable logic devices. Any place one of Intel’s existing server CPUs or networking ASICs might not play, an FPGA might.

Intel Rounds Out “Granite Rapids” Xeon 6 With A Slew Of Chips
It is no secret that chip maker Intel is having a tough time these days on a number of fronts, but it is important to remember that nearly two out of every three processors sold into the datacenter are Intel Inside. This is a good business that can be moderately …
What Will AMD Do With Programmable Logic And Other Xilinx IP?
AMD has finished its acquisition of Xilinx, which ended up costing close to $49 billion instead of the original $35 billion projected when the deal was announced in October 2020 thanks to the rise of AMD’s shares over the past year and a half. And now, with AMD getting the …

Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …
If they really want FPGAs to fly someone is going to have to do something about VHDL. Its like writing assembler back when C first came out.
My first experience with FPGAs was not writing HDL, but doing schematic capture using the DOS version of Orcad and generating an EDIF netlist. It worked great and you could see the flow of everything easily. I had high level blocks that at a glance told me what was going on. The compiler took care of all the details. I designed four different cards using Altera logic this way and they all worked fine.
I have heard horror stories of an FPGA expert spending three days pouring over 50,000 lines of code to find a single syntax error that kept his code from compiling (he was either missing or had one too many commas somewhere). This is not the wave of the future.
In 2010 Intel announced an Atom E600C with an Altera FPGA in one package.
The processor and the FPGA were connected by a PCI bus (2.5GB/s).
Let’s hope better success to the new hybrids.