

For some companies and research centers, managing access to massive pools of stored data across different systems has been a persistent challenge, especially with variations in file systems. As CERN experiments expanded and the data (and associated grid of compute and storage) grew, so too did the level of complexity for consistent global access.
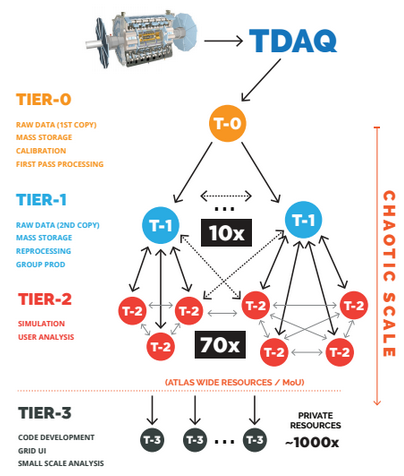
TRIUMF is one of ten Tier-1 datacenters tasked to handle the large amount of data from the CERN ATLAS experiment. In essence, the Canadian center reprocesses raw data from the colliders to create a filtered, usable dataset that is accessed by thousands physicists around the globe for further analysis.
The processing of the data streams is not as complex as the storage and data delivery mechanisms, but the center does have 5,000 cores (almost all “Sandy Bridge” Xeon E5 nodes, although there is some experimentation happening with GPU and Xeon Phi accelerators) dedicated to largely serial operations with future parallelization coming following current research. When the ATLAS experiment is running the Tier-1 is a required element as the proton collisions from the Large Hadron Collider and ATLAS detector are sent to the Tier-1 centers, which must very quickly determine from trigger data if a collision has noteworthy features. To give a sense of scale, the center narrows down 1,000 collisions per second to wind up on disk while another 40 million collisions per second are either rejected or stored directly to tape.
And make no mistake, tape plays a very active role with all data hitting the center’s 8.5 petabyte tape array before moving on through the queue. The rest of the center’s approximate 8.5 petabytes are comprised of DataDirect Networks storage, which has been tweaked via collaboration between the two entities to include embedded dCache.
Outside of CERN-related work, it’s possible you’ve never heard of dCache, especially if you’re not in Europe or involved in research computing. In essence, dCache aims to allow for massive storage and retrieval of distributed datasets under a single, unified virtualized file system access point that authenticated users can access worldwide. It is difficult to convey how important that layer, which allows for multiple file systems to be running on select nodes, is until one looks to large research centers that are storage-centric and tend to have a number of different existing storage systems from multiple upgrades.
“Before DDN and embedded dCache, we had a storage system on its own based on Fibre Channel, which meant we had to use separate file servers with 10GbE connectivity to deliver data to our clients. We wanted to have both systems together and managed under the same umbrella,” said TRIUMF research scientist for the ATLAS experiment, Reda Tafirout. The result was a standard DDN SFA 12XKE appliance, which means there are no more separate servers and Fibre Channel knots (there is just one dCache head node that controls the virtualized file system and the dCache pool nodes that “store the storage” via pool nodes). After rigorous testing through last summer, Tafirout says they have been impressed with the performance, relative ease, and smaller footprint.
“The benefit for us is that it’s independent of the file system you’re running underneath. You could have half of your storage in GPFS and other another on XFS. That is big for us, as it’s also important that it’s highly scalable, so if you want to add petabytes, because it’s not a clustered file system, you can take one component out or put others in without affecting the system,” Tafirout explained.
For worldwide access to the data, however, the other central features is that it is dynamically configurable, which lends control over how many clients can access storage concurrently and how many can be queued. Just as important, he says, is the ability to tune for different access protocols. “GPFS is all native, so you have to be part of the cluster, but with dCache you can have different access methods to get to the storage. Locally we use a particular access method, it’s the dCache access protocol, similar to copying files on a normal system, and for clients from outsde the Tier 1 center they use authentication via a grid certificate and we use GridFTP for that. The pro then is that you can use different access methods to your storage systems so whether you’re internal or if you’re from a remote site that wants to access a file from TRIUMF we can control all that.”
Tafirout described a scenario where this dCache top layer that exposes storage to the client might have 1,000 servers running different file systems, which can then be exposed on the other end as a single unified storage pool. Further, he said, the teams have developed tokens that are allocated for specific activities, just as one might find in other storage systems. This works to a certain extent, but ease of use and accessibility are still areas that need work if dCache is to find a home in other arenas. dCache itself takes some dedicated expertise. At the center there are two people that are more or less hooked to managing at this scale.
As one of the creators of dCache, Patrick Fuhrmann, explained, a key design feature is that “although the location and multiplicity of the data is autonomously determined by the system based on configuration, CPU load, and disk space, the namespace is uniquely represented within a single file system tree. The system has been shown to significantly improve the efficiency of connected tape storage systems, by caching ‘gather and flush’ and scheduled staging techniques.”
While the way the ATLAS Tier-1 sites like TRIUMF use tape so heavily is not something we see much in industry, where it does work—it works very well, says Tafirout.
The reliability of the system is also essential. As Fuhrmann describes, dCache optimizes throughput on both sides by “smoothing the load of the connected disk storage nodes by dynamically replicating datasets on the detection of load hot spots. The system is tolerant against failures of its data servers, which enables administrators to go for commodity disk storage components.”
In many ways, dCache seems like something the market might need, but as of now, ease of use is a problem (not that such a thing isn’t considered a plus when it comes to selling support around a [more or less] open source approach). But there are other barriers for now if one thinks about what might be next for dCache if a company like DDN or others would consider embedding it for other users with distributed storage and access needs.
First, it steps on some of the functionality of having a clustered file system, which is why the team uses XFS when possible. Still, in cases where there is, for instance, GPFS running alongside XFS, having a top layer to the storage stack that can unify and provide seamless central access for remote sites at massive scale might be something that oil and gas and other grid-centric companies might consider for their distributed, large-scale data storage access.
Another limitation, which the dCache team is hard at work on now, is that there are limited access protocols, which are focused on the high energy physics community now. However, there is currently work being done on the HTTP protocol, which could potentially open dCache to new markets and use cases with one of the most compelling “tales at scale” to tell about their ability to handle large, distributed datasets.
Using DDN SFA 12KXE with embedded dCache, the center ultimately consolidated both storage and data distribution within a converged architecture to deliver unlimited and seamless data access and sharing between nine other Tier-1 and 70 Tier-2 sites while minimizing access latency. As DDN noted today, “storage infrastructure now costs significantly less than before; the organization went from 21 4U servers requiring multiple racks to one DDN SFA system with 1.6 PBs running eight dCache virtual nodes in half a rack. Significant savings in data center space, power and cooling costs also have been realized.”


Boosting AI Storage With QLC Flash And Deduplication
A few years ago, DirectData Networks gave us a hint at the tectonic-like shifts that were emerging in datacenters at enterprises and high-end research institutions and were shaping the strategy of a company that had made its name in HPC with its parallel file system technology. New performance and storage …

DDN Uses Acquisitions to Grow In The Enterprise
For more than two decades, DirectData Networks has focused on HPC storage, supplying large systems to enterprises and research institutions wrestling with complex and data-laden workloads and taking on such challenges as acquiring the Lustre File System from Intel in 2018. At the ISC 19 supercomputing show in June, DDN …

Auto-Tiered Storage for AI and HPC
DataDirect Networks (DDN) has launched EXA5, the company’s fifth-generation Exascaler Lustre file system platform, which will be used to populate the company’s all-flash, mid-range, and high-end storage appliances. As is DDN’s custom, Exascaler is aimed at the HPC crowd, but this latest release also contains a number of features designed …
Be the first to comment