

Times are booming for the high performance computing oriented Tesla division within Nvidia, according to the company’s CEO, Jen-Hsun Huang who pointed to 10X growth in their supercomputing line since 2008 during his keynote this morning at the annual GPU Technology Conference. But in the sessions devoted to specific topics, including supercomputing and large-scale deep learning systems, the focus was on the key enabling technologies that support future Pascal and Volta generation GPUs.
Nvidia’s CTO for the Tesla division, Steve Oberlin, detailed the role of the high performance NVlink interconnect this afternoon in the context of upcoming HPC systems that will set the stage for exascale computing in the 2020(ish) timeframe. Currently, Oberlin is working with the Tesla group to bring two key GPU-powered supercomputers for the U.S. Department of Energy into the fold. These machines will set the stage for what’s next in terms of Nvidia’s supercomputing business, which itself is propelled by its high speed NVlink interconnect. This will allow data to speed between the GPU and CPU between 5-12X faster than with current PCIe approaches, which offers both performance and energy efficiency advantages.
 Oberlin says that since the beginning of his career at Cray there has been a performance improvement nine orders of magnitude leading to the present, with the expectation that sometime around 2020 with the arrival of exascale-class systems there will be yet another leap. Just how swift that leap will be will become apparent as the first of the CORAL systems come online in 2017. Two of the three pre-exascale machines in this procurement, Summit and Sierra, will be based on the Power9 and Tesla GPU architectures, which will be connected with NVlink, providing a machine that is 5X to 10X faster than the Titan machine at Oak Ridge National Lab using 1/5 the number of nodes—and all within the same power envelope of the current Titan system.
Oberlin says that since the beginning of his career at Cray there has been a performance improvement nine orders of magnitude leading to the present, with the expectation that sometime around 2020 with the arrival of exascale-class systems there will be yet another leap. Just how swift that leap will be will become apparent as the first of the CORAL systems come online in 2017. Two of the three pre-exascale machines in this procurement, Summit and Sierra, will be based on the Power9 and Tesla GPU architectures, which will be connected with NVlink, providing a machine that is 5X to 10X faster than the Titan machine at Oak Ridge National Lab using 1/5 the number of nodes—and all within the same power envelope of the current Titan system.
Oberlin joined Nvidia in 2013 as CTO for the high performance computing Tesla division, where he leads the overall roadmap and architectural direction. His supercomputing roots begin with Cray, where he helped develop early Cray vector multiprocessors. Following his work at Cray, he founded a company called Unlimited Scale, which provided a Linux-based HPC software stack for managing scalable clusters—an effort that was rolled into Cassatt Corporation (later acquired by CA Technologies) that was among the first cloud management and automation frameworks. In that time he says he’s seen quite a few architectural trends come and go, but more recently, the tension about how to eliminate the PCIe bottleneck for future systems consumed his interest, particularly in terms of seeing how companies like Intel are meshing the GPU and CPU on the same die.

“A couple of years ago people were talking about integrating CPU and GPU cores—making them self-hosted. I never thought this was a good idea and argued against it strongly when I came to Nvidia, even if I can see why some thought there were good reasons to create a self-hosted part,” Oberlin explained. “The CPU is optimized for latency and has a much larger memory but the GPU, even though it has way less memory has incredible memory bandwidth. It makes much more sense to simply get these two to communicate in a way that appears to achieve integration without putting them on the same chip, which would make the CPU rather unhappy hooked into the GPU memory hierarchy.”
For now, according to sample benchmark simulations that showcase how the NVlink-enabled Pascal generation GPUs will performance against real-world scientific codes over PCIe. For example, codes like Fluent, which can take advantage of the relative massive amount of memory bandwidth, will perform particularly well.
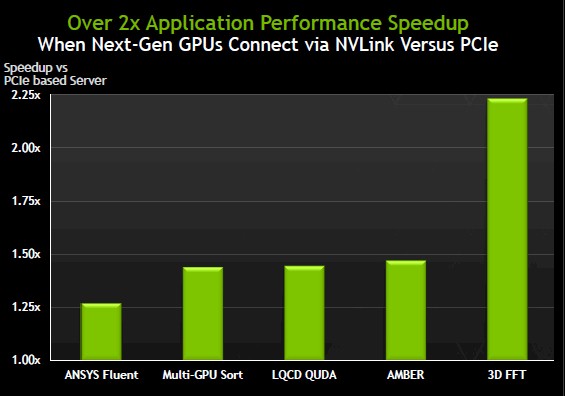 Tomorrow we’ll be reporting more specifics around upcoming Summit and Sierra machines following a deep dive on the architecture from GTC 15 that should show how these real-world codes are being considered for future pre-exascale machines.
Tomorrow we’ll be reporting more specifics around upcoming Summit and Sierra machines following a deep dive on the architecture from GTC 15 that should show how these real-world codes are being considered for future pre-exascale machines.

Be the first to comment