
By definition, a capability-class supercomputer means buying the best compute, storage, and networking available and getting high performance at just about any cost. But such machines are only for the elite of HPC and AI, and the rest of the market has to optimize for cost as well as performance, much as the cloud builders and hyperscalers have to do so they can maximize their profits.
The new “Vela” supercomputer built by IBM Research and running on the IBM Cloud is one such machine. Research does not directly drive revenue, so this arm of Big Blue has to be cost-effective while at the same time demonstrating that the kind of gear that it commonly deploys on its cloud can be tweaked to run the big workloads without having to resort to the latest and greatest GPU accelerators from either Nvidia or AMD. And besides, IBM seems to have absolutely zero appetite for building capability-class machine these days, so we don’t expect it to do that as a publicity stunt.
(We have some ideas about how IBM can deploy its Power10 servers in unique ways to drive HPC and AI performance. More on that in a moment.)
The Vela machine has been up and running since May last year, but IBM has only just now started talking about it. As far as we know, it has not run High Performance Linpack against it and submitted results to be put onto the Top500 supercomputer rankings; it may or may not decide to do so for the June 2023 list. If it did, the peak theoretical performance of this machine would be somewhere around 27.9 petaflops and that would give it a number 15 ranking on the November 2022 Top500 list. So it is no slouch even if it is not even close to an exascale machine, which IBM is clearly capable of building if it chose to.
You could build a Vela machine of your own by shopping for second-hand servers, CPUs and GPUs, and switches out on eBay, and IBM says in a blog unveiling the machine that the components of the machine were chosen precisely do IBM Cloud could deploy clones of this system in any one of its dozens of datacenters around the world. And we would add, do so without having to worry about export controls given the relative vintage of the CPUs, GPUs, and switching involved.
The Vela nodes are bog standard, and look like stuff that has been running inside of the cloud builders for several years now:
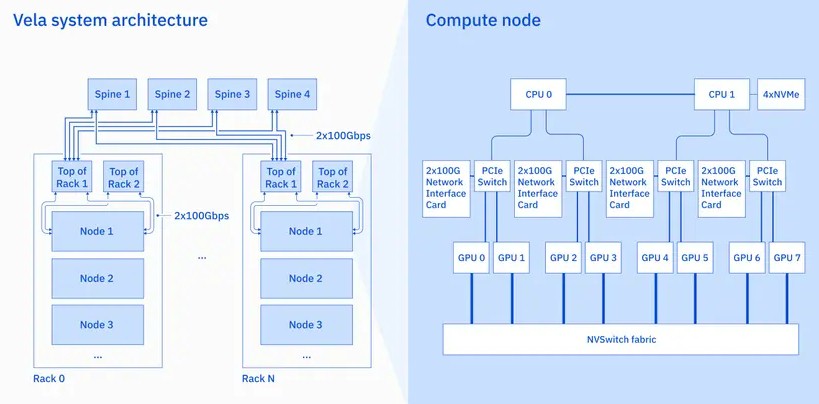
This looks like an HGX CPU-GPU system board that comes from Nvidia, and it is our guess that it is in fact one built by Supermicro given SoftLayer’s and then IBM’s long-time relationship with that server maker for its cloud infrastructure. The node has eight of Nvidia’s A100 GPU accelerators with 80 GB of HBM2e stacked memory and a pair of 24-core Intel “Cascade Lake CPUs, each with 768 GB of main memory attached to them. The GPUs are linked to each other over the NVSwitch fabric inherent in the HGX system boards from Nvidia, which provide NUMA-like memory sharing across the GPUs.
A quad of 3.2 TB NVM-Express flash drives provide local storage in the node, for a total of 12.8 TB and probably a few million IOPS of performance. Each pair of GPUs is linked to a PCI-Express switch that in turn links that GPU pair in the node to one of the two CPUs and a dual-port 100 Gb/sec Ethernet network interface card. We presume it is a ConnectX-5 card from Nvidia formerly Mellanox. IBM says that the network provides 600 Gb/sec orf bandwidth between two GPUs and the usable network bandwidth of the four flash drives is 128 Gb/sec Gb/sec and on the network ports is 200 Gb/sec (limited by the PCI-Express 4.0 port more than anything else).
We presume further that IBM is using Mellanox Spectrum-2 or Spectrum-3 Ethernet switches (we would guess Spectrum-2, which would be cheaper) to link the server nodes together. But it could be Intel NICs and Arista Networks or Cisco Systems switches. The point is, it really doesn’t matter because IBM chose to stick with Ethernet for its AI supercomputer because it does not want to do anything that is not standard in a cloud. There appear to be six nodes in a rack, which is consistent with cloud setups that do not want to push the thermal densities too high. There are definitely two leaf switches for redundancy and multipathing in each rack as well.
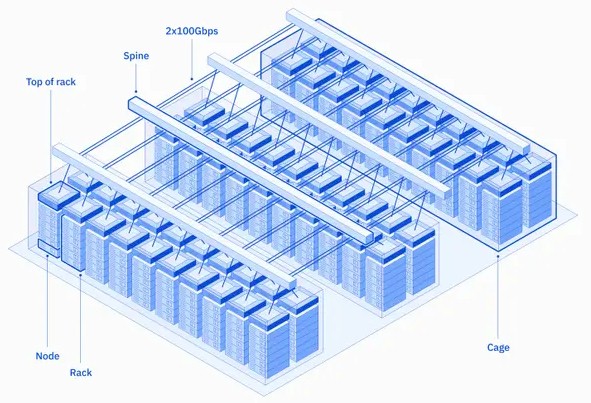
The server nodes are lashed together in a two-level Clos topology that is common among the cloud builders. Each rack hooks into a bank of four spine switches that provides what IBM said was “1.6 TB cross rack bandwidth” and has redundancy such that any failure of a NIC, top of rack switch, or spine switch does not take any of the 360 nodes in the Vela system down.
IBM has a long history in HPC, and knew that many of its researchers were using HPC job schedulers like its own Spectrum LSF, which IBM got through its January 2012 acquisition of Platform Computing. But other researchers – particularly those doing data analytics and AI, we would guess – make use of Kubernetes to pod up and schedule work on distributed systems, and IBM of course owns the most popular commercial version of Kubernetes (OpenShift) thanks to its acquisition of Red Hat more than four years ago. And thus, to satisfy both camps, IBM Research knew it needed to support a cloudy software stack complete with server virtualization, but do so in a way that did not impose huge performance penalties because HPC people hate that.

IBM says that the cluster nodes were configured with the full VXM hardware acceleration for server virtualization from Intel for its Xeon SP processors, turning on transparent huge pages for the Linux kernel, and turning on single-root I/O virtualization (SR-IOV) to use hardware to create and manage the virtual NIC and storage I/O in (what we presume) is the KVM hypervisor and the physical NICs. The idea is to deliver bare-metal performance inside of a VM.
“Following a significant amount of research and discovery, we devised a way to expose all of the capabilities on the node (GPUs, CPUs, networking, and storage) into the VM so that the virtualization overhead is less than 5 percent, which is the lowest overhead in the industry that we’re aware of,” IBM writes. “We also needed to faithfully represent all devices and their connectivity inside the VM, such as which network cards are connected to which CPUs and GPUs, how GPUs are connected to the CPU sockets, and how GPUs are connected to each other. These, along with other hardware and software configurations, enabled our system to achieve close to bare metal performance.”
Importantly, since Vela is a shared utility for many researchers, the use of SR-IOV means that all of the virtual private cloud (VPC) functions created by SoftLayer and improved upon by IBM (which we argue is one of the reasons why SoftLayer was a valuable acquisition for Big Blue) meant that all of the security groups, network access control lists, custom routes, private access to PaaS services, and access to Direct Link and Transit Gateway services of the IBM Cloud are all exposed to the VMs running on Vela as multiple researchers gain access to some or all of the machine.
IBM is also big on running PyTorch for AI training, and worked with the PyTorch community to get the Fully Sharded Data Parallel (FSDP) tool for sharding model parameters and spreading them over the GPUs in a cluster working properly on Ethernet rather than requiring InfiniBand and its RDMA acceleration. FSDP can also use CPUs as an offload memory engine, which we think is funny. Anyway, IBM has fired up PyTorch and FSDP to train an AI model with 11 billion parameters on 200 nodes of Vela, and it worked.
Now, having done all that, here is what we want IBM to do. Take a “Denali” Power E1080 or two and configuring them with the “memory inception” memory area network (our term, not IBM’s) that is possible with the OpenCAPI Memory Interface architecture inherent in the design, and use a big wonking 64 TB memory space on each Power E1080 as a memory server for PCI-Express versions of Nvidia’s “Hopper” H100 GPU accelerators in a cluster. It might mean using a Power10 processor as an auxiliary memory controller for the GPUs, since IBM for some reason does not support CXL on the Power10 chips and Nvidia for some reason does not support CXL on its PCI-Express 5.0 versions of its Hopper GPUs. Create a big shared memory space for the AI model and its data that does not have to be sharded, and let thousands of GPUs chew on it. See if this doesn’t yield more performance.

29 tflops is no where near 15th place.
Meant petaflops.
“the virtualization overhead is less than 5 percent, which is the lowest overhead in the industry that we’re aware of,” IBM writes.
Really?
https://aws.amazon.com/blogs/hpc/bare-metal-performance-with-the-aws-nitro-system/
“As shown in Figure 2, the normalized performance between the metal instance and the full-sized virtual instance is nearly identical. The differential in all of the evaluated cases is within 1% of the performance level.”
An article from one of their main competitors from August 2021 and IBM are not aware of it?
What was the server utilization by other virtual machines in the same server? Running a VM by itself on a server will indeed show little overhead (not null, but not significant). When you start with the context switching between virtual machines, and increased memory bandwidth competition between the multiple virtual machines running in the same system, you then start noticing the overhead.
There is no magic – you share resources, you will have overhead. A result showing “almost no overhead” strongly points to a best case scenario.
Hi David, maybe you have to take into account the fact that they only compare one instance of each class of EC2 server (if I did read it correctly). In the blog article you provide, it points to an article written by James Hamilton which I did comment in the past. I think we should wait for real results with real workloads that scale multiple instances of servers. I am sure IBM knows the real value of the “Vela Machine”.
It would surely be great to see a POWER10 HPC “demo” machine, a bit like NVIDIA’s Henri (HPL #405 in 11/22), just to get a taste of what these SerDes-heavy engines can do! POWER9 is still #5 (Summit) and that raises interest, suspense, and intrigue about what full-scale POWER10 systems might achieve. Then again, they seem rather specifically designed for composable heterogeneous motley crews of computational elements, for which they may serve as orchestra conductors, harmonically cutting through inter-system rigmarole, to yield a quite entertaining and performant system of this new class (even a demo would be valuable I think).
Can you provide more information on the Fully Sharded Data Parallel (FSDP) tool used by the Vela supercomputer? How does it compare to other parallelization methods and what are the potential trade-offs of using this approach? Can you explain how FSDP scales to larger datasets and models and whether it can be optimized for specific types of AI workloads?
None was offered but I can chase it down.