

Several years ago, the HPC systems designed for wide-ranging scientific computing were quite a bit different than those built for intense scalability and maximum peak performance. The top-end machines that were designed to deliver ultimate floating point capabilities were the first to deploy large numbers of accelerators (NVIDIA GPUs almost exclusively) and had an emphasis on networks and systems software to allow that all-important scalability, even if it would be limited to a few key applications.
At the same time, the capability machines, the ones designed to serve broad, diverse research communities, were often comprised of jobs that barely stretched beyond a single node, and were much more architecturally conservative. They were generally CPU-only machines designed for brute forcing as many users as possible through the queue. If there were GPUs, they were small in number and designed for a few key workloads, often small and specific, and for experimentation.
The difference was not just in accelerator count for these two system types. The emphasis on ultra-low latency often gave way to budget-related decisions about what is good enough given massively mixed workload types and while performance was useful, ultimate efficiency and the ability to have high utilization and keep cores fed was top of mind.
It is hard to say when the change happened, but over the last two to four years, there has been surprising convergence given opposite workload profiles. The systems designed to serve as many users with smaller or mid-sized jobs have begun to look a lot like the peak performing systems architected for massive scalability of key applications.
To understand why this convergence happened, we looked to one important example at the San Diego Supercomputer Center (SDSC). The facility’s most recent system, the upcoming “Expanse” machine is a living example of this trend.
When the center’s deputy director, Shawn Strande, first started working with Dell to pull lessons from the previous machine, Comet, it became clear that leading edge technology was not just for the big centers with massively parallel jobs that encompass the entire machine. In his collaborations with Dell and his teams, with their extensive workload analysis and profiling, a top-tier system could be just as efficient and useful for many more smaller jobs with diverse requirements as one designed for large workloads.
To give a sense of that diversity, SDSC jobs include everything from modest scale batch jobs of tens of cores, to several hundred cores, to high-throughput computing jobs from the Open Science Grid, which are characterized by tens of thousands of single-core jobs. They also handle data analysis of experimental facilities like the LIGO Gravitational Wave Observatory, and the IceCube Neutrino Observatory. Science gateways for a wide range of academic areas have added more requirements for support, and naturally, the anticipated large GROMACs, NAMD, and other important community codes must also run efficiently and scale well. SDSC, through work partially support by NSF’s E-CAS project, has also developed tools to support public cloud-bursting, specifically for the widely-used CIPRES phylogenetic gateway. Supporting all of these workloads and usage models has taken great effort on the entire infrastructure stack, from hardware decision-making to systems software backbones.
“Expanse was a response to an NSF call for a capacity system that would serve research workloads across virtually all domains of science and engineering. We think of our workload as being comprised of 5 computing modalities. First are traditional batch-scheduled single core and modest scale computing jobs to a few hundred cores. Second, we support high throughput workloads, via integration with the Open Science Grid. Third, are science gateways, which are now a ubiquitous way of accessing HPC. Fourth, cloud bursting from the on-prem system via integration with the batch scheduler. And finally, a composable system feature that is best described as the integration of computing elements (e.g., some number of compute, GPU, large memory nodes) into purpose-built scientific workflows that may include data acquisition and processing, machine learning, and simulation. Collectively, we these 5 modalities comprise our approach for supporting the “long tail of science,” Strande explains. It comes with some constraints, but these are more operational if enough diverse, high-performing infrastructure is in place.
“Our approach to system architecture is to start with a thorough understanding of our current workload, add to that where we see emerging needs in the community (like cloud integration), and within the constraints of a fixed budget, i.e., the funding from NSF for the system, develop a design that gives users as much compute as possible simultaneous with one that will achieve high levels of utilization while addressing the workloads. Our processor selection, interconnect design, data elements (like local NVMe on all nodes, and both a Lustre and object storage system), and software environment are the outcome of a deep understanding of the community, and a collaborative process with our vendor partner, Dell.”
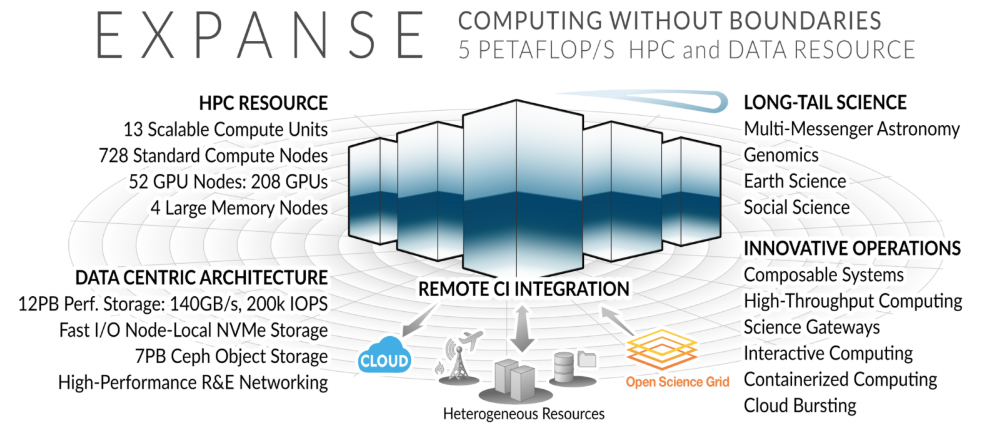
This collaborative process yielded a machine that is similar architecturally to many of the top-end supercomputers on the planet, even if not at the same scale (node/core count wise). The balance is what should stand out, particularly in terms of compute to memory, storage to network, and dense but appropriately sized nodes that can support both larger scaling jobs and single core research.
“Based on the nearly full utilization of our NVIDIA GPUs on Comet, we expect to see the same thing on Expanse. We see applications in a wide range of disciplines including molecular dynamics, neuroscience, materials science, protein structure analysis, and phylogenetics. Our GPUs on Comet are fully utilized and we routinely reduce by half the amount of time that we can allocate to GPU proposals versus how much time reviewers recommend. From application readiness efforts that are underway now for systems like Summit, and Perlmutter, it’s clear that the demand is there for large GPU-based systems, and the growth in machine learning and AI will only increase this demand. Systems like Expanse, though modest in comparison, provide a vital onramp for NSF users and those who are planning for scale-up on these large systems.”
Just because of modest size (relative, of course) and mixed workloads, some consuming only a single core, no longer means the high-end capabilities of the top supers is overkill. Providing access to low latency, high performance compute, accelerators, and I/O has now become standard, the only difference is overall core count for an increasing number of broad-base research machines. Dell Technologies and N VIDIA have experience helping centers build ultra-high-end machines that top the Top 500 and brought that experience to bear with Expanse, albeit at a smaller scale.
“Tens of thousands of researchers will be able to access vast amounts of memory, I/O and cores in the system, expanding our understanding of astronomy, genomics, earth sciences, biology and the social sciences, to name a few.” – SDSC Director Michael Norman, the Principal Investigator (PI) for Expanse, and a computational astrophysicist.
A deeper dive into the rationale and design of the Expanse machine can be found here.

Dell Sets Up For A Killer Spike In AI Server Sales
Back in February, Dell, the world’s largest server maker, told Wall Street that it was planning on selling and delivering $15 billion in AI servers in its fiscal 2026, when will end in early November. Sales were a little more tepid than we and many on Wall Street had expected …
Attacking The Novel Coronavirus With Supercomputing Cycles
Dan Stanzione has a lot of compute power at his fingertips. As executive director of the Texas Advanced Computing Center (TACC) in Austin, Stanzione is in charge of a number of supercomputer, including “Frontera,” a Dell EMC machine powered by Xeon SP Platinum processors from Intel that was deployed last …
Dell: Living On The Edge With Its Head In The Clouds
Deepak Patil knows all about the cloud. For the last third of his more than 15 years with Microsoft, Patil was one of the key figures behind the launch of Azure, the enterprise software giant’s public cloud. Azure has grown steadily and become the second-largest public cloud provider, gaining ground …
Be the first to comment