

Habana Labs has unveiled the Gaudi HL-2000, a custom-built AI processor that the company claims can outrun Nvidia’s best and brightest GPUs at training neural networks. In conjunction with the release of the new chip, the Tel Aviv-based startup is introducing a series of Gaudi-based PCIe cards, as well as an eight-processor server that can be used as the foundation for building super-sized training clusters.
Gaudi represents Habana’s second foray into the AI market. In the fourth quarter of 2018, the company began shipping its Goya inference card to select clients. As we reported at the time, compared to Nvidia’s V100 GPU, the HL-1000-powered Goya delivered more than four times the throughput, twice the energy efficiency, and half the latency when used on ResNet-50 for inference. According to Habana Chief Business Officer Eitan Medina, the company has collected close to 20 Goya customers, who are currently evaluating the technology.
 The new HL-2000 announced on Monday, is the training counterpart to the HL-1000. Again, using ResNet-50, Gaudi demonstrated it could reach 1,650 images per second with a batch size of 64. (The best training results we could find for a V100 is 1,360 images per second, with an unspecified batch size.) “The basic attribute that allows us to achieve this performance at small batch size has to do with the core architecture – the fact that it was designed from the ground up and is not piggybacking on an old architecture, like a GPU or a classic CPU,” Medina told The Next Platform.
The new HL-2000 announced on Monday, is the training counterpart to the HL-1000. Again, using ResNet-50, Gaudi demonstrated it could reach 1,650 images per second with a batch size of 64. (The best training results we could find for a V100 is 1,360 images per second, with an unspecified batch size.) “The basic attribute that allows us to achieve this performance at small batch size has to do with the core architecture – the fact that it was designed from the ground up and is not piggybacking on an old architecture, like a GPU or a classic CPU,” Medina told The Next Platform.
Habana isn’t offering much in the way of details on the internals of the chip, only stating that it is based on second-generation Tensor Processing Core (TPC), the first generation of which went into their inference chip. Medina told us that the Gaudi processor supports typical floating point formats used for training, like FP32 and bfloat16, as well as a few integer formats. On-package memory is in the form of 32GB HBM2, mirroring what’s available on GPU accelerators, like Nvidia’s V100 and AMD’s Radeon Instinct MI60.
Habana is not divulging any raw performance numbers for the new processor. “If I tell you how many multipliers I put on the chip and what frequency they are operating at, but the architecture does not allow you to utilize them, all I’m doing is misleading you,” explained Medina. According to him, because of their clean-sheet design, they can achieve much high utilization rates for their silicon than is possible with GPUs.
Perhaps the biggest potential strength of Gaudi will be its ability to deliver performance at scale, which has been a persistent challenge for building larger and more complex neural networks. For most training set-ups, once you go beyond 8 or 16 accelerators, that is, once you get outside of the server chassis, performance tends to flatten out. Not so for the Gaudi technology, said Medina, who pointed to near linear performance gains on the same ResNet-50 training scaling to hundreds of HL-2000 processors. When compared against the V100, the Habana technology was able to open up a 3.8x advantage in throughput at about the 650-processor level.
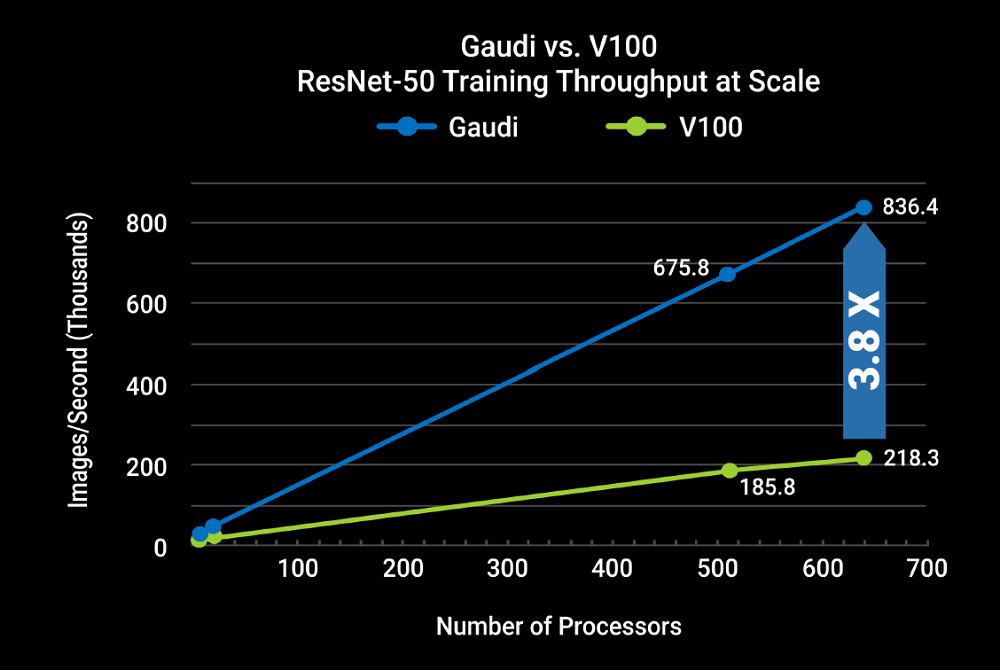
Habana was able to do this by inserting a ton of networking bandwidth, in the form of RDMA over Converged Ethernet (RoCE), into their Gaudi chip. The rationale behind using Ethernet, instead of something more exotic like NVLink or OpenCAPI, is that it enables customers to easily slide the Habana hardware into existing datacenters, as well as build out AI clusters using standard Ethernet switches available from a wide array of network providers.
In the case of the HL-2000 processor, 10 100GbE interfaces are integrated on-chip, some of which can be used to connect to other HL-2000 processors within a node, while the remainder can be used for intra-processor communication across nodes. The latter feature does away with the need for NICs.
An illustration of how this works can be seen in Habana’s own HLS-1 system, a 3U DGX-like box outfitted with eight HL-2000 processors. Internally, seven of each chip’s 100GbE links are used to connect the HL-2000 processors to one another in non-blocking, all-to-all fashion, while the remaining three links are contributed to the server to build out larger clusters – so 24 100GbE external ports. None of the Ethernet bandwidth is chewed up connecting to host servers or flash storage. For that, Habana has provided four PCIe Gen4 x16 interfaces.
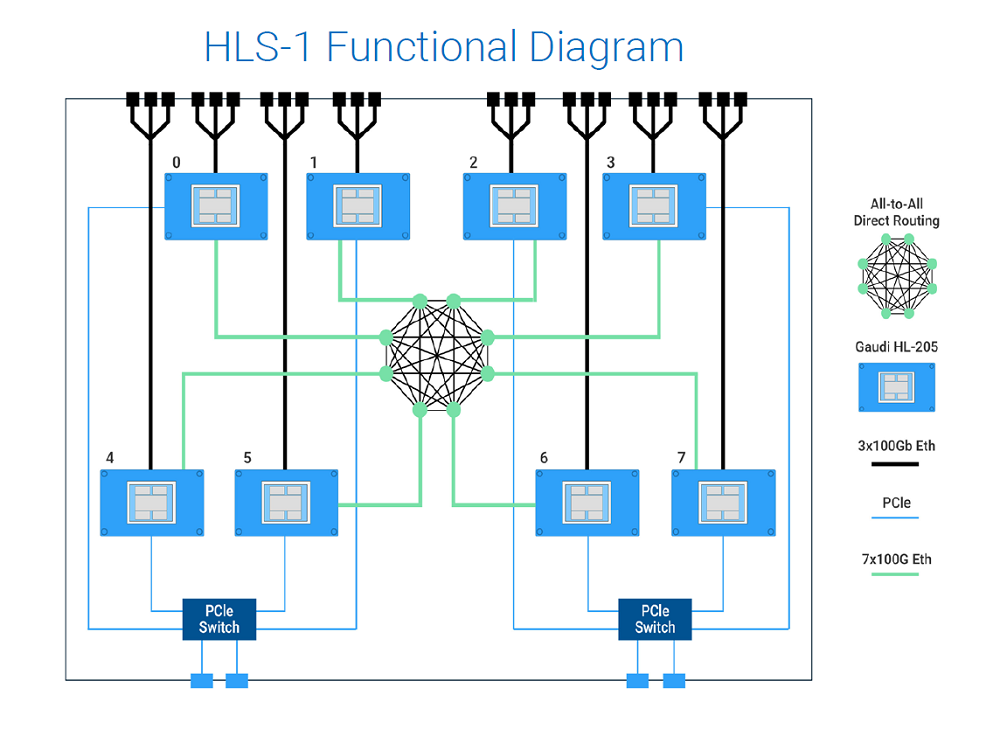
Contrast that with a typical GPU-accelerated server, which is usually limited by single network interface. The best to be had in this regard is Nvidia’s latest 16-GPU DGX-2 system, which is equipped with a whopping eight 100G ports, but that’s still a fraction of what the 24-port HLS-1 provides.
A rack of Habana Gaudi systems can be constructed by interspersing six HLS-1 servers with six CPU host servers – the HLS-1 doesn’t come with a host processor – plus a top-of-rack Ethernet switch. Racks like these can be strung together to build arbitrarily large clusters. While the absence of an on-board host processor may be annoying to some, it does allow customers to choose the make and brand of CPU and also give them the ability to fine-tune the ratio of CPU cores to AI accelerators.
Customers who want to build their own Gaudi-based systems can use Habana’s HL-200 PCIe card, which offer eight 100GbE ports, or the HL-205 mezzanine card which comes with 20 56Gbps SerDes interfaces, which is enough to support 10 100GbE or 20 50GbE ports of RoCE. The HL-200 consumes 200 watts, while the HL-205 draws 100 watts more.
The mezzanine card is the basis for Habana’s HLS-1 server. But it’s also possible to use it to construct even larger systems. For example, a 16-processor box can be built using the 16 HL-205 cards if you step down to 50GbE for the all-to-all connection in the box, still leaving 32 ports of 100GbE to scale out. If you want to build a smaller server, you can daisy chain up to eight HL-200 cards in a single enclosure.
The mezzanine card, by the way, supports the OCP Accelerator Module (OAM) specification, an open-hardware compute accelerator module form factor developed my Facebook, Microsoft and Baidu. Which tells us a lot at where Habana is aiming this particular product.
Unlike what Nvidia has done with NVLink, Habana is not supporting cache-coherent global memory space across multiple processors. The Gaudi designers figured that that cache coherency is a performance killer and can’t scale efficiently beyond a handful of accelerators. From their perspective, achieving scalability for training neural networks is fundamentally a networking problem and, with RDMA, is very effective for generating larger models.
Habana’s competition may also be coming around to this way of thinking. As Medina pointed out, at the recent GTC conference, Nvidia CEO Jensen Huang talked up RoCE as a way to greatly improve scalability for deep learning work. The implication here is that the GPU-maker has some pretty specific ideas about leveraging Mellanox’s Ethernet technology once that acquisition is consummated later this year.
Software-wise, Gaudi comes with Habana’s AI software stack, known as SynapseAI. It’s comprised of a graph compiler, runtime, debugger, deep learning library, and drivers. At this point, Habana supports TensorFlow for building models, but Medina said that over time they will add support for PyTorch and other machine learning frameworks.
It can be a long road from evaluation systems to production deployments, but if the Habana technology delivers as promised, the AI market will happily turn on a dime to chase better performance. That said, when it comes to AI hardware, Nvidia has proven itself to be a fast-moving target, for both startups and established chipmakers like Intel and AMD. One thing is assured: the demand for bigger and better AI is creating a highly competitive market where nimble execution by engineering teams is nearly as important as architectural design.
Habana will be shipping Gaudi platforms to select customers in the second half of 2019. Pricing has not been disclosed, although Medina tells us the Gaudi offerings will be “competitive” with comparable products on the market.

That’s an interesting system level/interconnect strategy! Would ditching PCIe altogether, towards a flow computing paradigm, make sense?
Interesting to see AI Chips accelerator to challenge GPU Chips in times to come even though it GPUs is starting or beginning to co-exist with Intel and AMD well establised CPUs.