
If there is one consistent complaint about open source software over the past three decades that it has been on the rise, it is that it is too difficult to integrate various components to solve a particular problem because the software is not really enterprise grade stuff. Well, that is two complaints, and really, there are three because even if you can get the stuff integrated and running well, that doesn’t mean you can keep it in that state as you patch and update it. So now we are up to three complaints.
Eventually, all software needs to be packaged up and supported like proprietary software has been for enterprises for decades before Unix and Linux came along and changed the way system software was created. Open source is really about writing software and improving it and, excepting for the world’s very largest – and largely self-sufficient – organizations, most companies could care less about software being open except that it gives them choice and control. Red Hat has built Linux operating system and Java middleware streams that comprise the vast majority of the $1.95 billion in infrastructure software subscriptions that the company raked in during its fiscal 2018 ended in February. Red Hat is by far the largest company selling packaging and support for open source software, and it commands the kind of lead in this area that Amazon Web Services has in the public cloud, which can be summed up thus: It is so big, how in the hell can anyone else ever hope to catch it?
That said, Red Hat has not quite been able to capitalize on open source storage software in the same manner that it has done with its Enterprise Linux distribution and its JBoss Java middleware and related application development tools. Not for lack of trying. (And on a side note, eventually Red Hat will have to provide some sort of virtual networking stack to compete with the likes of VMware in the enterprise. But that is a different story.)
Red hat has always been deep into file systems, and like other Linux distributors used the ext3 and ext4 file systems at the heart of the operating system. It then supported the Extents File system (XFS) journaling file system, created by Silicon Graphics for supercomputers back in the early 1990s, as a faster option for certain workloads. For a short time in recent years, Red Hat had adopted BTRFS, which was preferred by rival SUSE Linux in its distribution, as an alternative to the ext4 file system atop its Linux kernel, and ignored the clamor to support the Zettabyte File System (ZFS) created by Sun Microsystems and controlled by Oracle. More recently, support for BTRFS was deprecated and Red Hat backed a different file system, called Stratis, which is currently under development and which can be controlled by an API layer (like all modern systems software) as well as a command line interface (meaning, by humans), in contrast to XFS and BTRFS.
That is storage on a node, but you also have to scale storage across nodes. To get such capability, Red Hat ponied up $136 million back in October 2011 to buy Gluster, a spin-off from a supercomputer maker called California Digital Corp that provided the “Thunder” Itanium-based supercomputer to Lawrence Livermore National Laboratory, which did a lot of the funding behind the open source Lustre parallel file system that is used in a lot of HPC centers. Anand Babu Periasamy and Hitesh Chellani, who worked together on the Thunder system, founded Gluster in 2005 after CDC decided to get out of open source software and hardware and focus on more proprietary software. (Not a great move for CDC, obviously.) The company they started was not even focused on file systems, but in cobbling together software stacks based on open code, and they backed into the whole Gluster effort accidentally because of the limitations of storage scale at the time on Linux. The GlusterFS prototype – short for GNU Cluster File System – came out in early 2007 and the first commercially supported release came out in May 2009, and talking to us when the deal went down in 2011, Periasamy quipped to us: “Gluster started off with a goal to be the Red Hat of storage. Now, we are the storage of Red Hat.”
The secret sauce in GlusterFS was that, unlike both Lustre and its rival in HPC, IBM’s General Parallel File System (now Spectrum Scale), Periasamy and his team created a clustered file system that did not have a metadata server – often a performance bottleneck – at the heart of the cluster, but rather came up with an elastic hashing algorithm that allowed GlusterFS to scale across as many as 500 nodes and many petabytes of capacity at the time that Red Hat acquired it. GlusterFS could ride atop nodes using ext3, ext4, or XFS as their own file systems, and applications were exposed to the file system using NFS or CIFS mounts; it was also possible to wrap up GlusterFS an run it on EC2 compute on the AWS public cloud. A year later, when GlusterFS was polished up and relaunched as Red Hat Storage, the company had 100 paying customers, and it had created a shimming layer just like Lustre and GPFS had that allowed for GlusterFS to replace the HDFS file system underneath Hadoop batch data analytics software. This HDFS switchup has never really taken off for GlusterFS, Lustre, or GPFS, but for no good reason we could identify. At the time, Red Hat said that NAS appliances cost on the order of $1 per GB, but it could create GlusterFS clusters that delivered the same performance and capacity for something between 25 cents to 30 cents per GB.
Since that time, Red Hat has repackaged GlusterFS as the heart of its Hyperconverged Infrastructure, which simply meant melding its KVM hypervisor and GlusterFS on the same nodes to have a virtual server-NAS hybrid cluster that could compete with the likes of vSAN from VMware and the Acropolis Infrastructure Stack (which has had many other names) from Nutanix. This hyperconverged stack from Red Hat includes Ansible automation to run the code and keep it updated.
That could have been the end – or the beginning – of the Red Hat storage story had it not been for the exploding object storage market. To address scale-out object storage, and by extension also file system and block storage, Red Hat acquired Inktank, the commercial company behind the Ceph open source project, for $175 million in April 2014. Ceph was created by Sage Weil at the University of California Santa Cruz and initially sponsored by the US Department of Energy through Oak Ridge, Lawrence Livermore, and Los Alamos labs, and it is interesting in that it has block interfaces into the object storage and also has a POSIX-compliant file system overlay, called CephFS, that runs on top of it. That is the magic trifecta of storage, but Ceph does not fit all use cases in terms of scale or performance and that is why GlusterFS is still in the game.
Which brings us to today. While the operating system has largely been separated from the underlying hardware in servers for many decades, this has not been the case for either storage or networking, where machinery is largely still sold as sealed appliances. There is much weeping and gnashing of teeth by the hyperscalers about this black box approach, and they have done a lot to pry open the boxes, particularly with network devices. But the fact remains that an appliance approach is something that enterprises, who don’t have herds of PhDs on hand like hyperscalers, cloud builders, and academic centers, need even if they don’t want a sealed box appliance that limits their choices. They want to pick their hardware and software from a selected list of preferred and certified vendors and then get completed systems to show up, just like they get for servers and just like they really want for switches.
This is why Red Hat has cooked up a new approach to pushing storage called Storage One, where it is going to partner tightly with makers of storage server iron and eventually bundle and tune up its GlusterFS and Ceph storage software with its Ansible management stack and create something that can compete directly with other storage appliances from NetApp, Dell EMC, IBM, Hewlett Packard Enterprise, Nutanix, and so on in terms of features and ease of installation and use.
The obvious question, which we asked, is why did this take so long, particularly given Red Hat’s experience with partnerships with the OEM server makers who have pushed Linux into the enterprise in the past two decades. (Hyperscalers and cloud builders roll their own Linux for their own infrastructure, and the cloud builders allow commercial Linuxes from Red Hat, SUSE, and Canonical on their virtual machines, but customers have to pay for them and manage them.)
“There are a couple of factors,” Irshad Raihan, senior product marketing manager for storage at Red Hat, tells The Next Platform. “You could argue that storage at Red Hat is a relatively young compared to the more established businesses. Frankly, we were playing catch up om feature parity with the incumbents for the first couple of years. And next, we had to understand what use cases and workloads our customers were running, and then we had to build out the partner ecosystem. And now we feel that we can bring that learning and apply the 80/20 rule to create a few key configurations to meet the workloads that our customers have.”
That is why Red Hat Storage One is focused initially on two key areas to start, which are scale-out network attached storage and media content repositories. With this approach, Red Hat is working with key hardware suppliers to bundle Red Hat storage software with specific configurations of OEM hardware to create appliance-like systems that can be bought from the OEM with a single product number and sold just like a traditional storage array. And just as has been the case with Enterprise Linux on servers for years, the OEM has a contract to resell the Red Hat software and also a technical team that provides Level 1 and Level 2 technical support, backed up by Red Hat’s expertise for Level 3 issues that are over their heads.
With the initial Red Hat One stacks, GlusterFS is the file system that is being peddled first, and Supermicro is the hardware OEM that is getting to do the bundle first.

The scale-out NAS setup is based on a Supermicro SuperServer with a pair of eight-core “Skylake” Xeon SP-4110 Silver processors running at 2.1 GHz in each node, with 128 GB of memory, one PCI-Express Intel Optane 3D XPoint memory card with 375 GB of capacity for caching, and a dozen 3.5-inch storage bays for disks. The server has a built-in Broadcom 3108 RAID controller card and four 10 Gb/sec Ethernet ports coming off the motherboard for connectivity with other nodes and to the outside world. The base Storage One NAS cluster has four nodes based on 6 TB SAS disk drives, and it has 288 TB of raw capacity across those nodes, which converts to 120 TB of usable capacity after GlusterFS is installed on it and set up with two-way replication and an arbiter to avoid “split brain.” (This replication allows the cluster to keep running through disk, server, and network failures.) The clustered NAS can scale in two-node increments to a total of 24 nodes, with 1.73 PB of raw capacity, which works out to 720 TB of usable capacity across the cluster. Including a three-year GlusterFS software subscription and all of the hardware (72 TB raw), a base node costs $25,000. So it is around $100,000 for a base configuration. (Supermicro gets to set the price, not Red Hat.)
The Storage One setup for media content repositories is based on the same SuperServer configuration, but starts out with a six-node base configuration that uses fatter and cheaper 8 TB SATA disks, with 576 TB of raw and 384 TB of usable capacity in those nodes. This cluster can scale to 24 nodes as well, but in six-node increments that deliver 384 TB of usable capacity, yielding a maximum configuration of 24 nodes delivering 2.3 PB raw and 1.54 PB usable capacity. This capacity boost is also partially enabled by a shift from RAID protection to erasure coding, which provides protection for two disk failures in the cluster as it is configured.
Red Hat did not provide any pricing comparisons in the NAS case, but it did offer this comparison for the media content repository:
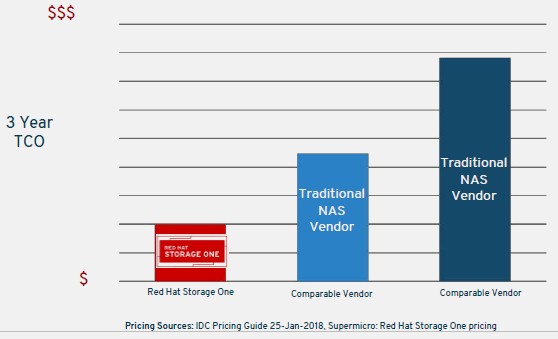
As you might imagine, we don’t like comparisons without specifications, without actual dollar values on the Y axis, and without naming the competition and their products.
Raihan says that Red Hat is working with other OEMs to bring them into the Storage One program, and obviously server makers that don’t have their own incumbent storage arrays or software-defined storage will be the most enthusiastic about this. But many who do have their own storage products will be agnostic so long as they can sell the iron and get the Red Hat support sale, too, as happened with servers. We expect that Red Hat will not only add Ceph versions of Storage One in relatively short order, but that it could perhaps be enticed into supporting Lustre for HPC shops and also create versions of these appliance clusters that are aimed at hyperconverged storage, data analytics (Hadoop and Spark overlayed on GlusterFS or Ceph), IoT, and other workloads.
It is time Red Hat started making money proportional to the market in storage, and this is how enterprises buy it. The do-it-yourself crowd can carry on as they have been, buying their own hardware and using the open source code or buying support licenses from Red Hat directly.

In addition to Gluster and Ceph, Red Hat offers OpenStack, which comes with its own distributed object storage server, known as “Swift”.
True. They don’t “own” it in the same way, and my guess is that it is not given any preferential treatment or even peer status to Ceph. I suppose the Cinder block storage from OpenStack should be in this list, too, for completeness.
A significant difference between Cinder and Manila versus Swift comes down to orchestration versus the actual service. Cinder arranges for your block storage to be delivered by Ceph RBD or a proprietary vendor exporting iSCSI volumes, but it does not actually serve the data. In contrast, Swift is an actual storage sever, not an orchestration. It is, as they say, in the data plane. Both Gluster and Ceph are data plane services too.