
Enterprises are purchasing storage by the truckload to support an explosion of data in the datacenter. IDC reports that in the first quarter of 2017, total capacity shipments were up 41.4 percent year-over-year and reached 50.1 exabytes of storage capacity shipped. As IT departments continue to increase their spending on capacity, few realize that their existing storage is a pile of gold that can be fully utilized once enterprises overcome the inefficiencies created by storage silos.
A metadata engine can virtualize the view of data for an application by separating the data (physical) path from the metadata (logical) path. This expands the domain beyond a single storage silo to span all storage resources within a namespace. Data management software can make use of information the metadata engine gathers about data and metadata to intelligently move and place even active data across storage resources. This enables enterprises to put storage to work in the service of data, making their investments more efficient, powerful and simple to manage. Let’s take a closer look at how a metadata engine can resolve these inefficiencies in Network Attached Storage (NAS) systems.
In-Band Metadata Degrades Performance
With traditional NAS systems, the metadata (control) path lies in the data path. This increases congestion and queuing of metadata operations waiting for data operations to complete, which can slow application response times. Metadata having to wait for data is like a little grain of pure sugar (metadata) having to wait behind an elephant (a large packet of data) to be eaten.
Enterprises attempt to minimize this problem by distributing data for active applications across nodes in a cluster. Even so, it’s common for an I/O spike on a node to create a hog and runt problem, where one application consumes all storage resources at the expense of the others, and this can affect business.
When one storage node in a cluster becomes oversubscribed, hot spotting becomes more frequent and severe. Enterprises typically avoid oversubscription through massive overprovisioning. When budgets don’t allow overprovisioning, IT currently addresses oversubscription by manually redistributing data across other nodes in the cluster. This process is disruptive, involving manually moving data to another storage node in the cluster, and possibly shutting down or stalling applications or processing queues. This can cause work delays from hours to a day.
While manual redistribution can temporarily solve the problem of predictable and permanent hot spots, frequently, I/O spikes are unpredictable and transient. In these cases, IT rarely has enough time to locate the node that is oversubscribed, let alone fix the problem. The complaints just have to endured until the activity subsides. Enterprises often attempt to address transient hot spotting by throwing more hardware in the cluster. Adding hardware does not address the hot spotting issue because data on the hot storage node cannot be moved. If a single storage node holds 70 percent of an organization’s active data and IT adds more storage nodes, the additional hardware only improves performance for the remaining 30 percent of active data in the cluster – the data that doesn’t need it.
A metadata engine solves hot spots in several ways. First, it improves the performance of data and metadata operations by offloading metadata operations. This guarantees that metadata operations do not get “stuck” in the queue behind other data requests, which improves the performance of all individual nodes. Second, it improves overall performance by enabling applications to access multiple storage nodes in parallel, eliminating the one-to-one relationship between an application and storage. The following diagram illustrates these improvements:
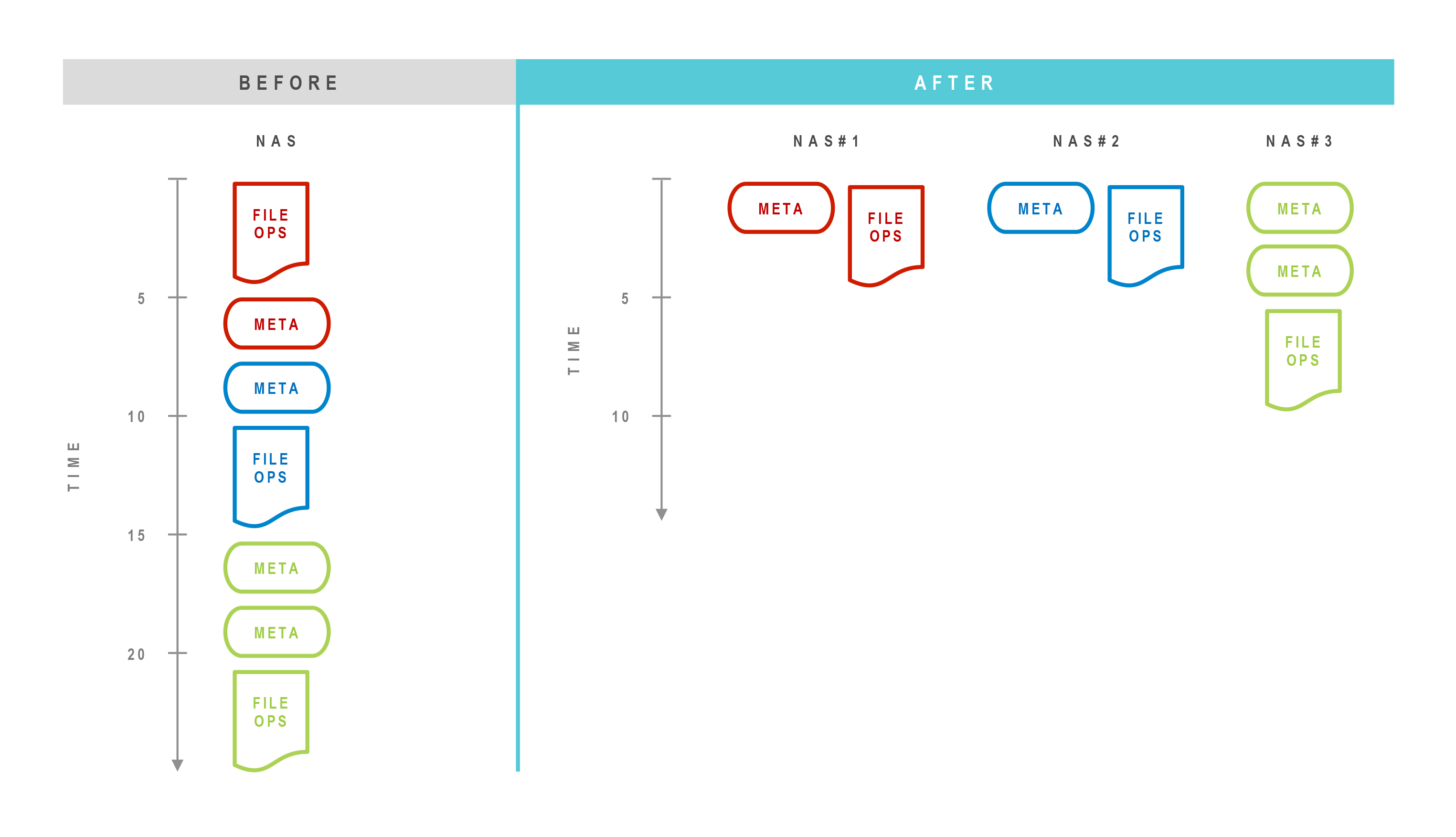
Importantly, a metadata engine also enables live data mobility without application disruption, so enterprises can automate the distribution (and redistribution) of data, on demand, according to business objectives across performance, protection, and price. Hot spots are addressed automatically, without impacting applications, as soon as they arise, enabling IT to guarantee higher service levels. Each storage node can be used much more efficiently and scales performance and capacity linearly to reduce costs.
Inefficient Capacity Utilization Drains Dollars
While NAS bottlenecks and data gravity create inefficiencies in performance, the inability to easily move data is a key factor in wasted spending on capacity. It’s not uncommon for IT to double requested capacity to avoid business disruption by avoiding the need to move data. This means raw capacity spending is at least double what is necessary. If data growth projections are high, this waste grows exponentially.
IT typically places an application’s entire data set on one type of storage. This is costly since studies have found that about 75 percent of data stored is typically inactive, or cold, meaning up to three fourths of storage capacity is being used inefficiently.
The overpurchasing of capacity grows even more wasteful given that IT typically places data on storage designed to meet an application’s peak needs, and those peak needs might need high performance storage with an equally high price tag. The gap between storage cost and the value of data grows quickly as data ages and requires far less performance from the storage system it resides on.
A metadata engine solves the problem of this misalignment by enabling even live data to move automatically across storage nodes without application disruption. This movement is data-aware, as the metadata engine monitors how applications are experiencing storage and moves data to the right resource, on demand, as business needs evolve. Companies can then reclaim up to 75 percent of NAS capacity by automatically archiving cold data to a lower cost filer, on-premises object or public cloud storage, greatly extending the life of their existing investments.
This efficiency translates into much lower costs. Once high performance storage is no longer stuck hosting data that’s gone cold – which currently accounts up to 75 percent of its total capacity, as noted above – each system can store up to 4X more active data. By placing the right data on the right storage resource, metadata servers like DataSphere help IT departments greatly reduce the amount of high performance capacity they require. In addition, since DataSphere enables additional capacity to be deployed in minutes, enterprises can greatly reduce overprovisioning without risking business continuity.
Manually Tiered NAS Systems Are Complex And Costly
The archival use case for cold data introduces the concept of using different NAS systems as tiers. Indeed, it’s quite common for enterprises to maintain multiple NAS clusters with varying capabilities to support different application requirements or when they reach the scalability limits of a NAS system. The problem is that each NAS system will suffer from the inefficiencies discussed above, and each must be managed separately.
Some enterprises, particularly those in industries such as Media and Entertainment, manually tier data across different NAS clusters as part of a workflow. These tiering approaches are complex and error prone. For example, to ensure applications don’t need to be changed as data is copied from one cluster to another, admins might create a root NFS export, mount it across the cluster, then use an automounter to graft mounts from each tier to the root NFS export, as needed. Data movement is still manual, though it can be scripted, and consists of copying data to the destination tier, which disrupts applications, drains compute jobs and stalls work. Data access is maintained through a proliferation of symlinks that are often recorded in spreadsheets, which admins must reference whenever they move data to keep production applications from breaking.
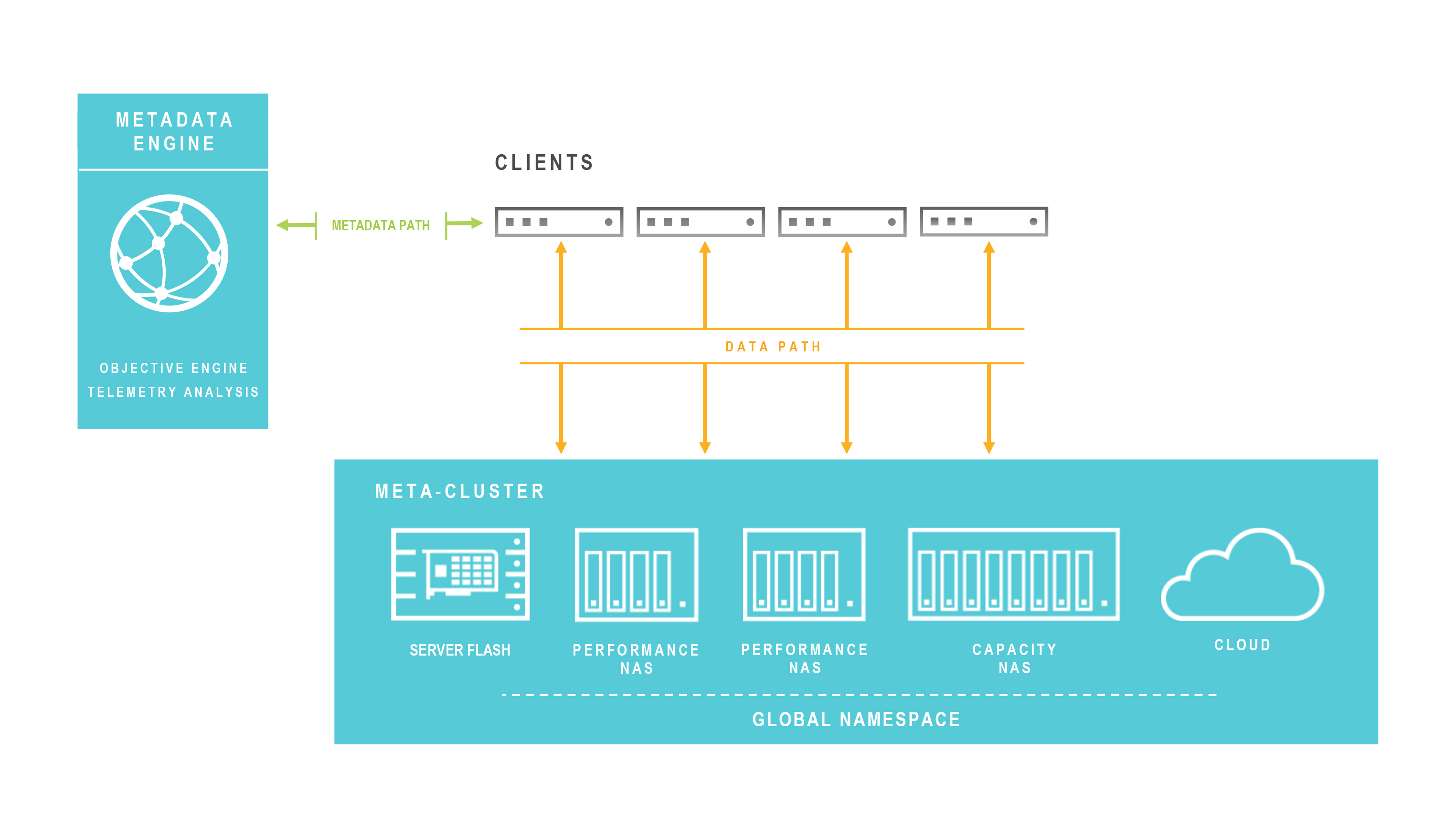
A metadata engine can tier data across different NAS types without disrupting applications, and without the need for IT intervention. Enterprises can add multiple NAS types to create a “meta-cluster,” if you will, composed of different storage with different capabilities. The metadata engine knows what each storage device is capable of and can move data across them, as needed. Workflows can be automated. Data can move to lower cost storage either via an admin manually applying a different policy to data, or dynamically through a policy that will move data that has not been accessed within a predefined time window. In addition, whereas typical workflows are unidirectional, data can be moved up and down tiers as needed.
For example, when media and entertainment companies work on a sequel, they must often move data from the original movie to their Tier 1 system. A metadata engine an automatically detect when artists are accessing archived data and retrieve it to a Tier 1 device. This means no more late night and weekend migrations in preparation for the next big project. It also means no need for IT to dedicate huge amounts of Tier 1 storage to support the maximum number of running projects a company might be working on. The diagram below illustrates a metadata engine NAS environment:
Inefficiencies Of Purchasing Through A Single Source
NAS systems typically excel in one or two capabilities. One system might offer the best performance, while another might offer the best management tools. Enterprises frequently choose to buy all their NAS systems from the vendor whose NAS system meets the needs of their most critical apps to avoid the need to hire new staff or learn to manage many different systems. This compromise can reduce a business’s effectiveness since the enterprise sacrifices capabilities for less critical apps and can increase costs.
A metadata engine can be protocol- and vendor-agnostic. This enables enterprises to purchase and deploy NAS clusters with exactly the capabilities they need. The metadata engine will optimize the placement of data across all of them. Enterprises can even easily expand performance by adding flash in a commodity server or implement elastic capacity through seamless integration with on-premises object or public cloud storage.
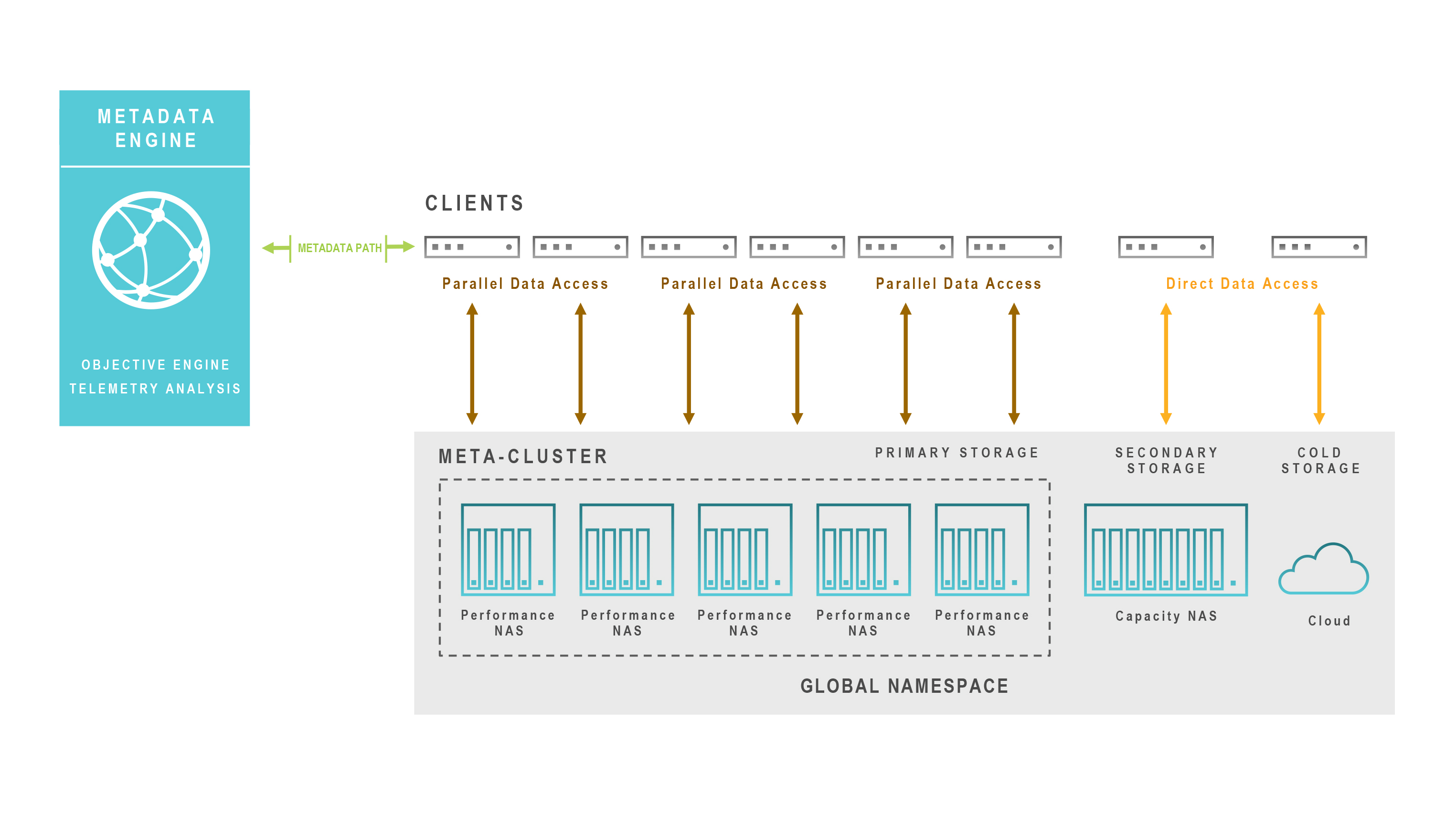
An Efficient, Integrated NAS Ecosystem
A metadata engine eliminates storage silos and solves the inefficiencies of NAS systems, enabling enterprises to put storage capabilities to work in the service of data through live data mobility without application impact. This helps enterprises create a dynamic ecosystem comprised of different NAS types and even cloud/object storage to increase service levels, accelerate time to market, and reduce storage costs.
David Flynn is co-founder of startup Primary Data and has been architecting disruptive computing platforms since his early work in supercomputing and Linux systems. Flynn pioneered the use of flash for enterprise application acceleration as founder and former CEO of Fusion-io. He designed several of the world’s fastest InfiniBand and RDMA-based supercomputers, and was chief scientist and engineering vice president for Project BlackDog, and developed thin client solutions at Linux Networx and Network Computer, a spin-off of Oracle Corporation. Flynn holds more than 100 patents across web browser technologies, mobile device management, network switching and protocols, to distributed storage systems. He earned a bachelors degree in computer science at Brigham Young University.

Be the first to comment