

The IT industry has gotten good at developing computer systems that can easily work at the nanosecond and millisecond scales.
Chip makers have developed multiple techniques that have helped drive the creation of nanosecond-scale devices, while primarily software-based solutions have been rolled out for slower millisecond-scale devices. For a long time, that has been enough to address the various needs of high-performance computing environments, where performance is a key metric and issues such as the simplicity of the code and the level of programmer productivity are not as great of concerns. Given that, programming at the microsecond level as not been a high priority for the computing industry.
However, that’s changing with the rise in warehouse-size computers running in hyperscale datacenter environments like Google and Amazon – where workloads change constantly, putting a premium on code simplicity and programmer productivity, and where the cost of performance is also of high importance – and the development of new low-latency I/O devices that work best at the microsecond level.
Given such trends, vendors need to begin developing software stacks and hardware infrastructure that can take advantage of microsecond-level computing and reduce the growing inefficiencies in modern datacenters, according to a group of researchers from Google and the University of California, Berkeley. The researchers argue that the “oversight” of focusing on nanosecond and millisecond levels “is quickly becoming a serious problem for programming warehouse-scale computers, where efficient handling of microsecond-scale events is becoming paramount for a new breed of low-latency I/O devices ranging from datacenter networking to emerging memories.”
“Techniques optimized for nanosecond or millisecond time scales do not scale well for this microsecond regime,” they wrote. “Superscalar out-of-order execution, branch prediction, prefetching, simultaneous multithreading, and other techniques for nanosecond time scales do not scale well to the microsecond regime; system designers do not have enough instruction-level parallelism or hardware-managed thread contexts to hide the longer latencies. Likewise, software techniques to tolerate millisecond-scale latencies (such as software-directed context switching) scale poorly down to microseconds; the overheads in these techniques often equal or exceed the latency of the I/O device itself. … It is quite easy to take fast hardware and throw away its performance with software designed for millisecond-scale devices.”
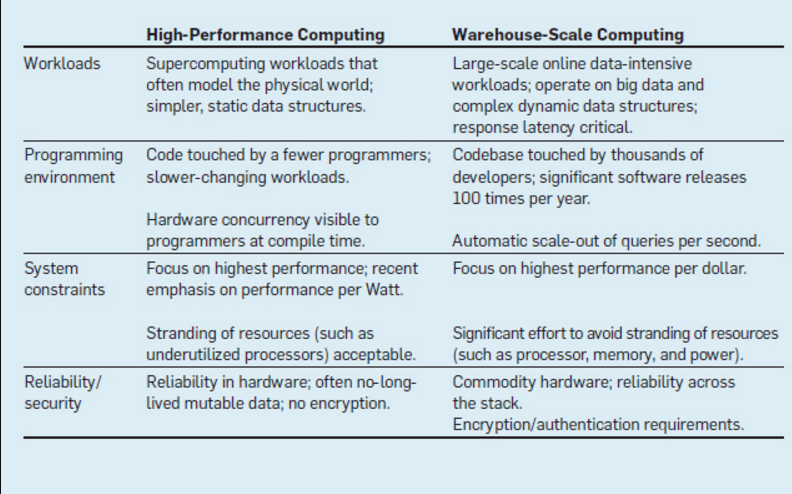
That hasn’t been much of a problem in the past, the researchers said. HPC organizations traditionally have gotten along with low-latency networks. They have workloads that don’t change nearly as often as those in high-end web-scale environments, and programmers don’t need to handle the code as much. Data structures within the HPC field also tend to be more static and less complex, all of which makes high-speed networks a good fit. In addition, while the HPC field is most concerned with performance, costs and resource utilization play much larger roles in the calculations for companies like Google and Amazon. “Consequently, [HPC organizations] can keep processors highly underutilized when, say, blocking for MPI-style rendezvous messages,” the authors wrote. “In contrast, a key emphasis in warehouse-scale computing systems is the need to optimize for low latencies while achieving greater utilizations.”
Hardware and software development to this point has targeted minimizing event latencies at the nanosecond and millisecond levels. On the nanosecond scale are such features as the deep memory hierarchy developed in processors, which include a simple synchronous programming interface to memory that is supported by a range of other microarchitectural techniques, such a prefetching, out-of-order execution and branch prediction. At the millisecond level, the innovations have primarily been in software. As an example, the researchers pointed to OS context switching, in which once a system call is made to a disk, the OS puts the I/O operation in motion while performing a software context switch to another thread to use the chip during the disk operation. “The original thread resumes execution sometime after the I/O completes,” they wrote. “The long overhead of making a disk access (milliseconds) easily outweighs the cost of two context switches (microseconds). Millisecond-scale devices are slow enough that the cost of these software-based mechanisms can be amortized.”
In dealing with nanosecond- and millisecond-scale devices, Google engineers prefer the synchronous model over the asynchronous. Synchronous code is simpler, making it easier to write and debug, and works better at scale, where organizations can take advantage of consistent APIs and idioms to leverage the applications that are usually written in multiple languages, such as C, C++, Go and Java, and touched by many developers and new releases are issued on a weekly basis. All of this makes synchronous coding better for programmer productivity.
Now microsecond-level technologies are hitting the industry that better suit the needs of hyperscale environments. There are new low-latency I/O devices that won’t work well in nanosecond or millisecond time scales. Fast datacenter networks tend to have latencies in the microseconds, while a flash device can have latency in the tens of microseconds. The authors also pointed to new non-volatile memory technologies, such as Intel’s Xpoint 3D memory and the Moneta change-based memory system, and in-memory systems that will have latencies in the low microseconds. There also are microsecond latencies when using GPUs and other accelerators.
The slowing of Moore’s Law and the end of Dennard scaling also have highlighted the need to use lower-latency storage and communication technologies, they said. Cloud providers, to address the changes in Moore’s Law and Dennard scaling, have grown the number of computers they use for queries from customers, and that trend will increase. Techniques used for nanosecond and millisecond scales don’t scale well when microseconds are involved, and can result in inefficiencies in both datacenter networking and processors.
What computer engineers need to do is create software and hardware that are optimized for microsecond scale, the researchers wrote. There need to “microsecond-aware” software stacks and low-level optimizations – such as reduced lock contention and synchronization, efficient resource utilization during spin-polling and job scheduling – designed for microsecond-level computing.
On the hardware side, new ideas “ideas are needed to enable context switching across a large number of threads (tens to hundreds per processor, though finding the sweet spot is an open question) at extremely fast latencies (tens of nanoseconds). … System designers need new hardware optimizations to extend the use of synchronous blocking mechanisms and thread-level parallelism to the micro-second range.”
There also needs to be hardware features for everything from orchestrating communication with I/O and queue management to task scheduling and new instrumentation for tracking microsecond overheads. In addition, “techniques to enable micro-second-scale devices should not necessarily seek to keep processor pipelines busy,” the researchers wrote. “One promising solution might instead be to enable a processor to stop consuming power while a microsecond-scale access is outstanding and shift that power to other cores not blocked on accesses.”
Given the growing demands from hyperscale datacenters, computer engineers need to begin designing systems that offer support for microsecond-scale I/O, they wrote. “Today’s hardware and system software make an inadequate platform, particularly given support for synchronous programming models is deemed critical for software productivity,” the researchers wrote, adding that “novel microsecond-optimized system stacks are needed. … Such optimized designs at the microsecond scale, and corresponding faster I/O, can in turn enable a virtuous cycle of new applications and programming models that leverage low-latency communication, dramatically increasing the effective computing capabilities of warehouse-scale computers.”

Be the first to comment