

The datacenter is a battleground with many fronts these days, with intense competition between compute, memory, storage, and networking components. In terms of revenues, profits, and prestige, the compute territory is the most valuable that chip makers and their system partners are fighting for, and the ARM and OpenPower collectives are doing their best to take some ground from a very powerful Intel.
As such, chip makers end up comparing themselves to Intel Xeon or Atom processors, and Intel sometimes makes comparisons back. At the high end, Intel is battling the Power8 processor championed by IBM and to a lesser extent, the Sparc chips from Oracle and the Sparc64 chips from Fujitsu, and mostly for running in-memory and database workloads. At the low-end, a number of ARM suppliers are attacking Intel from below, aiming their processors at distributed workloads such as web serving, cold storage, caching, application serving, and analytics.
With the ThunderX ARM chips from Cavium getting traction in recent months and Cavium and its partners making performance claims about the systems as they relate to Xeon machines, the competitive analysis techies at Intel’s Data Center Group decided that they had best get their hands on a system and put it through some benchmark paces to see what kind of performance ThunderX chips are delivering on a variety of benchmarks that Intel uses to rank its own processors against other generations of its own chips and against alternatives. Intel reached out to The Next Platform and shared its test results with us first, given our focus on future platforms that companies could be deploying in their datacenters.
The results are interesting, and point out that even though ARM server chip makers Applied Micro, AMD, and Cavium have gone a long way towards making ARM-based machines look and feel like a Xeon platform in terms of form factor, BIOS, and management tools, putting the best foot forward on benchmark tests still requires familiarity with the nitty gritty of any architecture. Even though Intel’s techies know plenty about systems, they had trouble setting up and testing the ThunderX server from Gigabyte that they were able to get their hands on. (In many cases, vendors peddling ARM servers will not sell a machine to Intel, and the company does not feel it is appropriate to go through third parties to acquire ARM systems for test.)
Intel secured a Gigabyte server based on the ThunderX_CP variant of the Cavium processor, which is based on custom ARMv8 cores and which is aimed specifically at compute workloads as opposed to other versions of the ThunderX chips aimed at storage, networking, and secure compute. Intel was not able to obtain systems based on these other ThunderX_ST, ThunderX_NT, and ThunderX_SC processors to test them on appropriate workloads, nor was it able to acquire ThunderX_CP parts running at their top bin 2.5 GHz speed. Cavium tells us that the 2 GHz part is the sweet spot in terms of price and performance per watt, but that it is indeed able to make the faster parts if customers want them.
According to David Kanter, a chip analyst at MicroProcessor Report, the original design goals of the ThunderX processor were to have a 48-core part in a 95 watt thermal envelope at that 2.5 GHz clock speed, but as far as he can tell the chip as delivered using 28 nanometer processes from Samsung and GlobalFoundries actually burns at 135 watts running at 2 GHz. Kanter further estimates that a 2.5 GHz part with all 48 cores on the ThunderX_CP fired up might consume 150 watts to 160 watts.
The one lesson that is clear from the presentation that engineers at Intel, gave us on its benchmark tests is that it takes a certain amount of expertise to use any new chip architecture and system to its full potential, and Intel admits that it may not know all of the tricks to make a ThunderX system roar. In this regard, Intel is not much different from the sophisticated, bleeding-edge hyperscalers, HPC centers, and large enterprises that have deep expertise on the Xeon instruction set and are going to take an ARM server chip out for a spin for the first time running their applications.
The other thing that Intel stressed is that there can be a big difference between datasheet specs and performance on benchmarks, and we would add that these two are not necessarily indicative of the performance organizations will see running their own specific applications. Testing systems with your own code is key – if you can get your hands on the systems, that is. The ARM server chips can be hard to get still.
By the datasheet matchup, Intel has a lot more bandwidth for sharing main memory NUMA-style with its “Broadwell” Xeon E5 v4 processors, the most current motors it has for workhorse two-socket machines. (The Xeon D processor that Intel compared to the ThunderX chips from Cavium are only available in single socket variants.)
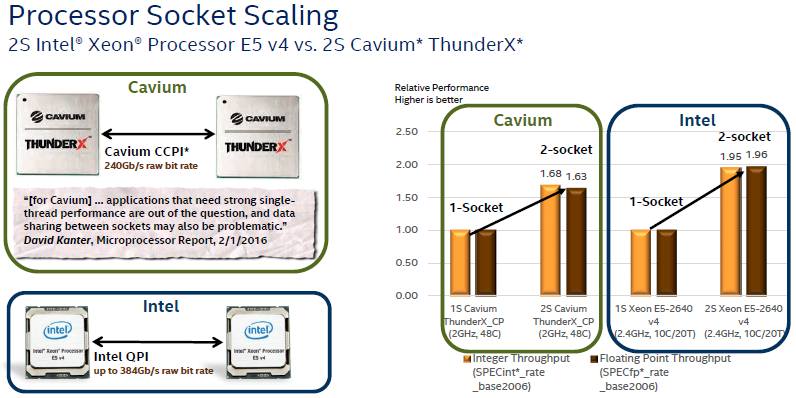
As you can see, the ThunderX implementation of NUMA for two-socket configurations has 240 Gb/sec across its CCPI bus, which is quite a bit slower than the 384 Gb/sec bandwidth that the two QuickPath Interconnect (QPI) ports offer between a pair of Xeon E5 v4 processors. Based on SPEC integer and floating point tests, the two socket scaling seems to be much more efficient on the Xeon E5s than on the ThunderXs, as the chart above shows. While SPEC tests are table stakes to get in the running for datacenter jobs, as Cavium and Applied Micro have said again and again, the real test is not the SPEC benchmarks, but rather how the processors do on real work. The point Intel is making in the chart above is that it has mastered NUMA scaling, which is no surprise since the company has been at it for decades. We think that Cavium will get better over time, too, and very likely at a faster rate because a lot of what Intel, IBM, Oracle, and others had to learn the hard way is now common knowledge among chip designers today.
For workhorse jobs in the datacenter, NUMA scaling is important, but so are the speeds of cache and main memories, and here is how Intel lines up the ThunderX against the Xeon D and the Xeon E5. Intel has a deeper cache hierarchy, with L1, L2, and L3 caches and soon with the “Skylake” Xeons will be adding an L4 cache layer to stage more data in front of the processor cores and keep them fed at a faster rate.

Like other ARM server chip makers, Cavium is sticking to L1 and L2 caches and is trying to make it up with faster memory and a relatively high number of memory channels – more than initial ARM server chips from Calxeda and AMD offered and more akin to what a Xeon E5 offers. The tables above are fun because they put some numbers on reads across the memory hierarchy, the kind of data that is tough to come by. (Hence, why we included it in this story.)
It can be difficult to visualize the architectural differences between the Xeon E5 and ThunderX chips, so this might help:
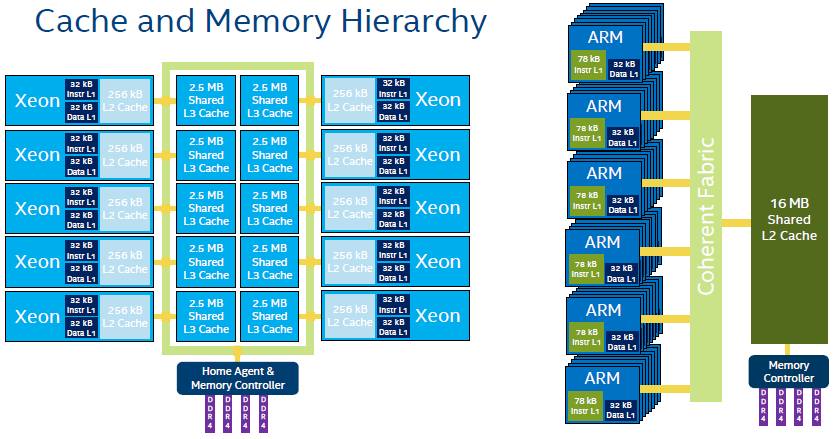
The paths and the distances traveled across the Xeon E5 and ThunderX chip components are very different, and this will obviously have a big impact on the performance of applications running on them. It will all come down to tuning the applications for the specific architecture, and in this regard, Intel has the advantage now because its compilers are so well tuned for its processors and for the tests people use to compare chips. On the SPEC benchmarks, Intel’s homegrown compilers yield somewhere between 15 percent and 20 percent more performance compared to the open source GCC compilers, according to Kanter. It seems highly unlikely that Intel will tweak its Compiler Studio to run well on ARM architectures, but Intel sort of is an ARM server chip maker thanks to with its Altera acquisition, since some of the FPGA system on chip designs include ARM cores, so it could happen.
Intel makes no bones about the fact that the company is putting its best foot forward in testing the Xeon E5 and Xeon D systems and that Intel struggled itself to not only procure a ThunderX system, but that it could only acquire a compute variant, not one that had accelerators turned on for storage, networking, and security that might have shown better results on certain tests. Intel did its tests with the variant of Linux that shipped with the Gigabyte system it acquired, which was Ubuntu Server 14.04 and which is a bit long in the tooth, and was not able to update the kernel to the latest level. It was surprising that Intel chose to try to update the old Ubuntu Server 14.04 rather than just get a fresh new release of Ubuntu Server 16.04, which has the latest kernel patches and which has been tuned up even better to run the ThunderX processors. It is hard to say what issues Intel had in doing its tests were due to using a variant of Linux that is two years old and how much is due to inexperience with the ThunderX chip. Every new platform has its teething issues, and techies at the incumbent server makers based on CISC and RISC processors were saying the same thing about Intel Xeon platforms two decades ago. Kinks get worked out as new architectures get put into production, and if the volumes ramp enough, ARM chips will find their footing.
To make its comparisons, Intel bought similar sleds from Gigabyte equipped with its “Broadwell” Xeon E5-2640 v4 and E5-2699 v4 processors, and also bought a single-socket server based on the Xeon D-1581 from Supermicro, as shown below:
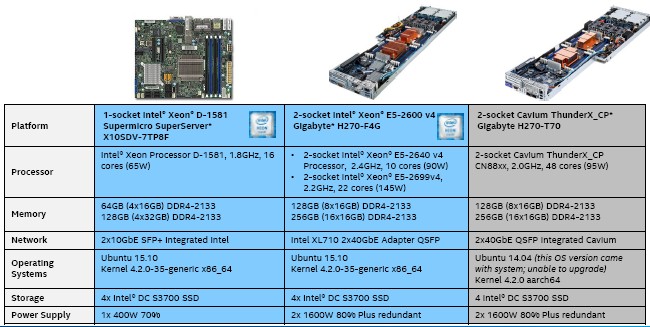
Intel used a bunch of two-socket Xeon E5 servers as client load generators, which were linked to the machines using a pair of 40 Gb/sec and 10 Gb/sec Ethernet ports, the fastest of whichever was available on each machine. The idea was to not create any network bottlenecks, or at least to push them to the limits.
Cavium is a full licensee of the ARMv8 design from ARM Holdings and as such it creates its own cores. From the get-go, Cavium designed its ThunderX chips to have lots of cores ganged up and aimed at multithreaded workloads rather than aiming at jobs where single-threaded performance is the key factor. As such, the throughput per socket rather than the performance per core is perhaps a better metric for ThunderX, and hence the SPECint_rate_base_2006 is a gatekeeper of sorts. Intel combed through the statements ARM chip vendors have made over the years about their wares plus the benchmarks it has done on ThunderX as well as the Atom S, Xeon D, and Xeon E5 processors and put it all into a single chart:
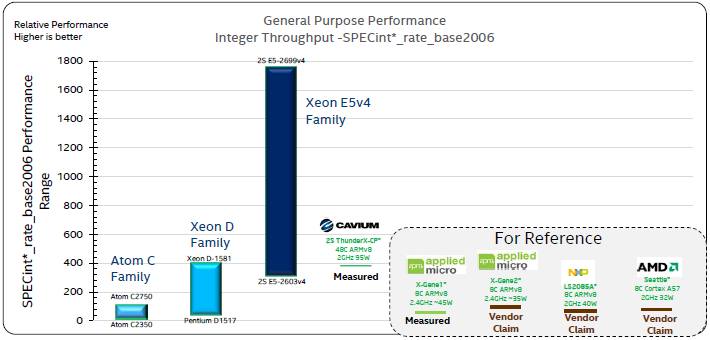
It is clear from this chart why Intel is focusing its competitive benchmarking on the ThunderX processor, seeing as though it offers considerably more throughput performance than an eight-core X-Gene 1 or X-Gene 2 processor from Applied Micro, the Opteron A1150 from AMD, or the NXP LS2085A. The performance numbers for these processors are based on claims, with one test for the X-Gene 1 by Applied Micro on a Hewlett Packard Enterprise Moonshot m400 microserver node. That X-Gene 1 processor was rated at 59.7 on the SPEC integer throughput test with eight cores running at 2.4 GHz and a thermal envelope of 45 watts. Applied Micro says that the X-Gene 2 kicker to this chip with the same clock speed and core count runs at 35 watts and delivers a SPEC integer throughput rating of 99. The NXP LS series chip has eight cores running at 2 GHz and a thermal envelope of 45 watts and is said to have a SPECint_rate_2006 of 74, while the AMD “Seattle” A1150 was said to have a rating of 80 way back in January 2014.
The two-socket Gigabyte H270-T20 server, which has two ThunderX chips running at 2 GHz for a total of 96 cores, was tested by Intel to have a SPECint_rate_2006 throughput of 378, which is a lot higher than what the other ARM server chips are delivering. (None of them have NUMA clustering, so they only can bring one socket to bear. Applied Micro is working on a software implementation of NUMA, as we have previously reported, for its X-Gene 3 chip.)
In analyzing these results, Kanter tells The Next Platform that the SPEC integer throughout ratings that Intel got on the ThunderX system are low and adds that by the modeling done by MicroProcessor Report that a two-socket ThunderX machine should be able to deliver a rating of around 600 on the SPECint_rate_2006 test with 48 cores running at 2 GHz, but again this is in a power envelope of 135 watts per processor. That heat is one side effect of having so many cores in a 28 nanometer design, and it is also why Kanter estimates that a pair of 2.5 GHz chips might deliver about 670 on the SPEC integer throughput test but do so with somewhere between 300 watts and 320 watts. Clearly Cavium needs to get to a 14 nanometer process as Intel has done with the Xeon D and Xeon E5 v4 chips so it can drop its thermals way down. If you want to do single socket comparisons, figure the 2.5 GHz ThunderX chip has a rating of around 350 on the SPEC integer throughput test and the 2 GHz part has a rating of around 280, says Kanter.
The Pentium D – Xeon D processors from Intel fall in a similar performance band as the ThunderX chip, with a low of 41 on the Pentium D1507, which is a two-core part running at 1.2 GHz and a 20 watt thermal envelope, to a high of 401 on a 16-core Xeon D-1581 running at 1.8 GHz and a 65 watt heat dissipation. You can see why Intel doubled up the core count in the Xeon D recently, and why it will probably boost the core count again. The Atom line, which is not very good for most compute workloads, brackets a range of 20.1 on an Atom C2350 with two cores running at 1.7 GHz and a 6 watt envelope to 106 on an eight-core Atom C2000 that runs at 2.4 GHz and that fits in a 20 watt power band.
As you can see, based on the SPECint_rate_2006 tests that Intel has performed, the Broadwell Xeon E5 v4 processors have a very wide range and a two-socket ThunderX chip only kisses the bottom of the range. (Again, the expert we talked to said Intel’s result in its tests is probably not as good as the ThunderX can do, and its own results on the Atoms and Xeons are highly tuned for the SPEC tests.) The low-end Xeon E5-2603 v4 chip has six cores running at 1.7 GHz and has a SPEC integer throughput rating of 356 for two sockets and a pair of the top-end Xeon E5-2699 v4 chips with 22 cores each is rated at 1,760 on the integer benchmark.
To help visualize the interplay of effective performance per core of all of these chips versus throughout across the cores, Intel cooked up this chart:
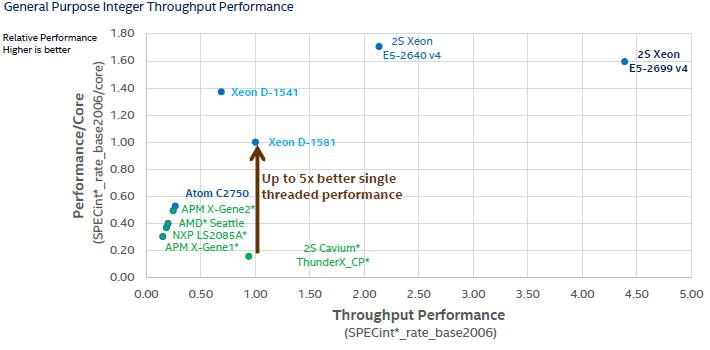
Everything in the chart above is measured relative to the Xeon D-1581, and it includes two-socket machines. Here is what Intel estimates the performance to be for single-socket machines:
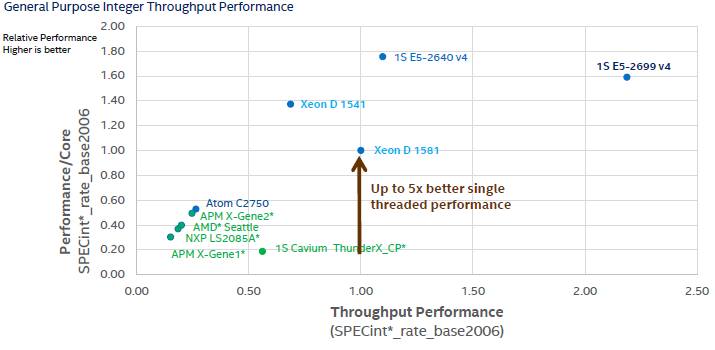
For the single-socket ThunderX configuration, Intel is making its own estimate because it says it was unable to figure out how to disable one of the processors in the dual-socket Gigabyte system.
The SPEC integer tests are not the be-all, end-all of course. They are just the table stakes. So Intel tried to fire up some other benchmarks on the ThunderX and Xeon D processors. Intel was able to get SPEC floating point and dynamic web serving results for the ThunderX machines, but Intel says that its techies could not get what it reckoned were meaningful results on Java and Memcached benchmark tests on the Gigabyte ThunderX machine. Here are the results of these tests:
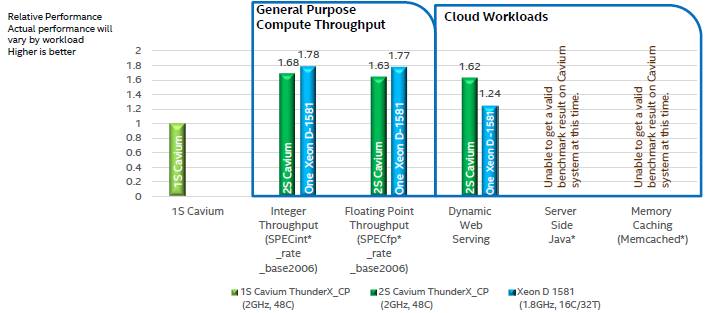
The performance in the charts above is reckoned against a single ThunderX processor, and Intel’s tests show that a single Xeon D-1581 has about the same performance as a pair of ThunderX chips on SPEC integer and floating point throughput tests and for dynamic web serving. The Xeon D system burned 140 watts running dynamic web serving test, according to Intel, while the dual-socket ThunderX system consumed a staggering 410 watts. It is hard to say why this number was so high, but we suspect that the power management features of the ThunderX server node were not configured properly, and even Intel admits to not being sure of the cause.
Intel estimates that if it could disable one of the processors, a single-processor ThunderX system would burn about 180 watts. We would love to see Cavium tune up a machine with Ubuntu Server 16.04 and run the same tests, of course, and with this data from Intel now out there, it might just do that. Intel also tested the cryptographic processing capability of the ThunderX_CP against the Xeon D-1581, but without the cryptographic accelerators turned on, it is not really much of a surprise that the Xeon D did a lot better. It would be good to pit the ThunderX_SC variant against the Xeon D on the crypto tests, but Intel could not get one of these chips to test.
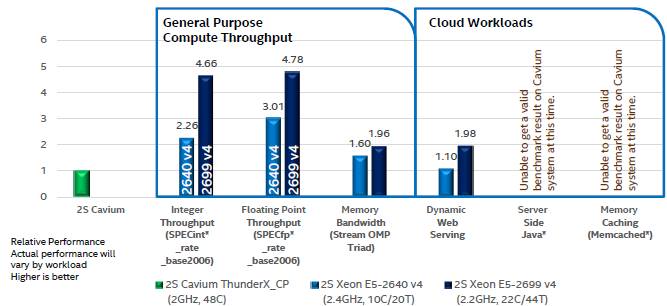
As shown above, Intel ran the same set of tests on Broadwell Xeon E5 machines and plotted their results against a two-socket ThunderX machine. This time the STREAM memory bandwidth test was added to the mix, and the ThunderX system delivered 65.1 GB/sec of bandwidth on the STREAM Triad. The a two-socket machine using Intel Xeon E5-2640 v4 processors came in at 102.4 GB/sec while one using the top-bin E5-2699 v4 delivered 127.7 GB/sec. Interestingly, for dynamic web serving, the machine with two E5-2640 v4 chips did only a little more work than a two-socket ThunderX system, and with the top-end Xen E5-2699 v4 chip, the system only did about twice the work. Intel’s SPEC tests show a bigger gap than the memory bandwidth and web serving tests do. And on dynamic web serving, Intel is only showing about 50 percent better performance per watt with power measured at the wall when the systems are running. On the machines that Intel tested the idle power was 110 watts for the two Xeon systems compared to just under 290 watts for the ThunderX system. The Xeon E5-2640 v4 machine consumed 290 watts running the dynamic serving test, and the Xeon E5-2699 v4 system consumed 535 watts, more than the 410 watts of the two-socket ThunderX machine.
What everyone wants is for Cavium and the rest of the ARM collective to put their own best foot forward tests into the field on their current chips and the impending ones as they come to market. The tests done by Intel are a good starting point because they are at least public and point out some of the issues that the company found in trying to do tests. We surmise that Cavium, which knows its systems best, can run the same tests Intel does across the Xeon line with its partners and give a more tuned set of results that are more directly comparable to the highly tuned Xeon results. We look forward to such tests being performed, and what kind of performance we can expect from Cavium ThunderX2, Applied Micro X-Gene 3, and AMD K12 ARM processors, as well as whatever Qualcomm is cooking up. The battleground is already starting to shift to the future “Skylake” Xeon architecture, and with the ARM collective moving to 14 nanometer or maybe even 10 nanometer processes for Qualcomm, 2017 could be shaping up to be a real battleground for compute. Particularly if the ARM chip vendors get aggressive about pricing.
This is, of course, a fight that many had been expecting for year after year for the past five years, and Intel has managed to stay one step ahead.

wow. intel is afraid of competition… from arms and POWERs… otherwise, why all this marketting campaing? they are loosing the technology advantage soon and they need to claim something. Xeons were good because there were no alternatives. Now, there are, and lets see if they are as good as they said for so many years.
Well nice article but we only are going to see similar benchmark from Cavium and other ARM players out there if they can proof that their architecture performs better otherwise they wouldn’t do it same as Intel has here. So since they haven’t done yet it shows that they probably can’t simple as that.
The reality is, none of the canned benchmarks matter including SPEC although accepted as the IT sys admin standard of measure. Everyone knew v8 systems require a non Intel foundation of measure, all the way back into 2012, and no one has delivered.
Intel’s comparison misses the workload points entirely,
Cavium and the ARM camp generally allowing their peers in the processor evaluation business to propagate Intel truth, on Intel tools, only goes to show certain of the newbie’s confounded lacking knowledge of Intel competitive strategies honed in the 1990s, remains a lost art, including on the Intel moles and their beholden wanting that knowledge to remain lost and therefore unutilized.
The hurdle, and the opportunity, developing that independent suite is the political backlash it will deliver upsetting the Intel status quo, by essentially, exposing its pundits as confused.
Engineers like frameworks. Throw in confusion and engineers who have basked in the many forms of Intel light, including false light, will freeze on the result of encountering a ystem inconsistency.
Constant coordinated disruption to establish the new status quo; get it?
Yet there are still secrets on that knowledge lost.
Mike Bruzzone, Camp Marketing
I think OOO custom cores will be either relatively wimpy or else a steep learning curve from the multiple generations of relatively simple in-order cores they have successfully used for networking parts in the past.
Ignoring the bringup pain various early people have experienced with ThunderX, and some of the wrongheaded/wildly inappropriate ecosystem nonsense, they’re roughly A53 level performance per core. Next generation they’re claiming roughly A57ish. Delivered perf on branchy integer code will be tricker than their marketing folks think — plus questions around size of core will be interesting to see play out, even on newer process, given the clock and core count targets.
They’re also running late if you compare to Mellanox news. I’d bet more heavily on them given the use of the relatively off the shelf A72 cores, which are higher ipc but shipping frequencies tbd, and the Tilera descendent interconnect (which screams high core count vs the ARM interconnect).
http://www.mellanox.com/related-docs/npu-multicore-processors/PB_Bluefield_SoC.pdf
Intriguing and likely to reach production long before ThunderX2.
Tim, did Intel use their optimizing compiler for the SPEC tests? I did not see reference to that in your fine piece. If so, they should degrade their SpecINT results by ~20% or more to reflect Gnu C results with standard optimization (-o2).
People always bring this up as argument but there is nothing to stop Calvium or ARM itself to bring out an optimized tool-chain themselves as well. If you’re using a certain architecture you might as well spend a bit of money on the best tools to get maximum performance out.
I agree that other companies will come out with benchmarks that will support their own ends. Really need to see how everything works when it’s out in the user’s hands.
—
Sam_Smith
Web Developer and Aspiring Chef
Large file transfers
http://www.innorix.com/en/DS“
Firstly, Broadwell is published by Q1,2016. And then ThunderX is published by Q4,2014. Maybe it should use Haswell (Q4,2014) to compare with ThunderX. Right?;Secondly, the shared cache should compare with the shared cache. ThunderX L2 cache is shared cache, it shouldn’t compare with Intel L2 cache. Right?; Thirdly,even for the compare, it should use the same GCC version and the same compiler flag.Or used ICC to test Intel
This is a ThunderX2 comparison, not the regular ThunderX2.
And the L2 cache comparison works well. It is sizes that matter for the software stack and the access latencies, not the micro-architectural details if they’re shared or not.
I personally don’t think the access latency is enough either, but some picky system engineers like to know those numbers because there are some latency sensitive workloads such as in networking and comms.