

Switch chips have a very long technical and economic lives, considerably longer than that of a Xeon processor used in a server – something on the order of seven or eight years compared to three or four. As it turns out, the various GPUs used in Nvidia’s Tesla accelerators look like they, too, will have very long technical and economic lives.
Even after a new technology is introduced, sometimes the old one can be had at a much cheaper price and therefore continues to be a good price/performer even after it has been presumably obsoleted by an improved product. Its economic life outlives its technical life in this regard, and it is not obsoleted instantly (often to the frustration of its creator, which wants to sell the shiny new stuff). But sometimes this is in fact the plan.
With the launch of the “Pascal” GP100 engine in the Tesla P100 accelerators this week, which are already shipping to hyperscaler customers and which will be available to the rest of the world in volume later this year, Nvidia now has three generations of GPUs – including the Kepler devices that debuted in May 2012 and the Maxwell devices that finally made their way into Tesla units back in November 2015 – in the field at the same time, and they are aimed at somewhat different use cases. While the products based on Kepler and Maxwell will eventually be obsoleted, Nvidia is not in any kind of hurry on this front and the obvious question for customers who are looking to buy Teslas to accelerate their workloads now is whether or not these prior generations will continue to have a long technical as well as economic life in the Nvidia lineup.
“It is a long time,” Marc Hamilton, vice president of solutions architecture and engineering at Nvidia, tells The Next Platform, in reference to how long of a life these Kepler and Maxwell products will have. “We continue to do incremental upgrades, and for instance we just quietly released the Tesla M40 with 24 GB of memory. Pascal is really designed for the best scalability in eight ways – and things like HBM2 and NVLink have a cost and so customers who need that two hours of training time on their neural networks, that is priceless to them. And if you do the math against 250 servers with just CPUs or even four or eight Pascal box, a lot of customers are fine with a two GPU or four GPU box, and for these customers, the Tesla M40 and Tesla K80 make a lot of sense to keep going. We have not set an end-of-life date for these, but once we send out such a notice, they are available for twelve months. So we expect these products to ship through the end of 2017, if not longer.”
This makes a lot of sense for Nvidia’s business, too, since it cannot ship the Pascal-based Tesla P100 accelerators in volume until later this year and they won’t appear in certified systems from key OEM and ODM partners until early 2017.
But the situation is more subtle than that. While Nvidia shipped a very powerful and energy efficient Maxwell-based Tesla that was aimed at certain kinds of single precision workloads – machine learning, seismic processing, genomics, signal processing, and video encoding all work perfectly fine at single precision and do not more work at double precision – it never did get a Maxwell chip into the field in a Tesla form factor that had more double precision floating point performance than the Tesla K40. In fact, instead of such a hypothetical GPU (which presumably would have been called an M40, like the real product was), Nvidia created a variant of the Kepler GPU called the GK210B, dialed down the cores and clocks a bit, and put two of them on a single card with two GDDR5 memory blocks, and called it a Tesla K80. This is exactly the same kind of thing that processor makers have been doing since the late 1990s, although inside of a single processor socket usually as a stopgap until a new product comes out.

We could, in fact, eventually see a Tesla card with a pair of Pascal GPUs embedded on it, and maybe even with GDDR5 memory like the older cards use for jobs where memory bandwidth is not the bottleneck and where NVLink, which looks like it will only be available on high-end Pascal GPUs, is not necessary. We have a hard time believing that memory bandwidth is not the bottleneck for everyone, but for certain kinds of jobs, perhaps memory capacity is more of a problem, and it is very expensive to add HBM2 memory to a Pascal card at this point and GDDR5 memory is relatively cheap.
Imagine a two-GPU Pascal P80 card with maybe 48 GB of memory, which might cost considerably less than a Pascal P100 card. There could also be Tesla P4 and P40 equivalents to the current M4 and M40 Teslas, but it is reasonable to expect that Nvidia will want to get as much mileage out of Kepler and Maxwell accelerator cards as it can.
Just for fun, it is also interesting to contemplate doing a straight process shrink from 28 nanometers to 16 nanometers on the prior GPUs used in the Kepler K40 and K80 accelerators or the Maxwell M4 and M40 accelerators to boost their clock speeds and reduce their thermal envelope. But we did not get the impression from Hamilton that this was something the company was considering.
Our thinking is this: The feature set in Pascal GPU is universally appealing, and will eventually be cascaded, where appropriate, across a complete Tesla Pascal product line. Nvidia might have added FP16 half-precision math for AI researchers and commercializers, and these customers are driving the architecture, they are eager to buy, and they are paying a premium. So this is all good the for Tesla business. But over time, Nvidia will ramp it up and as the 16 nanometer process matures, it will gradually flesh out a full Pascal product line for Tesla accelerators.
In the meantime, the Pascal P100 accelerator will definitely cost more than any current Tesla card. “Pascal will be priced at a premium because it is a more expensive product, and that is part of the reason why M40 and K80 will have a long life,” explains Hamilton. “The best throughout performance, especially at the low-end with one or two GPUs, will be there.”
Here is how the current Teslas available on the market stack up:
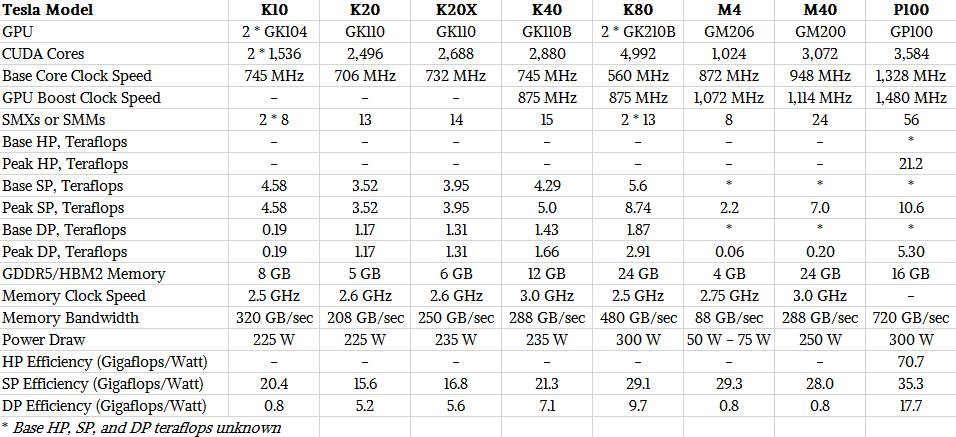
Nvidia does not publish list prices for its Tesla products, so it is hard to say how much of a premium it is charging in terms of dollars per flops or dollars per flops per watt (which is probably a better measure). But for customers doing machine learning, the increase in cores and clock speeds with the Pascal GP100 GPU compared to the Maxwell GM200 plus the shift to FP16 half precision math means that this 16 GB of HMB2 memory looks and feels like 32 GB would be at FP32 single precision and that the effective performance of the device as it double pumps the CUDA cores comes in at 21.2 teraflops per device. That is a lot higher than the 8.74 teraflops SP for the Tesla K80 and the 7 teraflops SP for the Tesla M40 card, which did not support FP16 data and processing.
How much of a premium that Nvidia can charge for the Tesla P100 card is a good question, but our math working backwards from the $129,000 price tag of the Nvidia DGX-1 appliance, which has eight of these cards, is that the P100 costs around $10,500 initially. NVLink and the ability to very tightly lash up to eight GPUs together, the 2.5X increase in memory bandwidth thanks to HBM2, and the delivery of a 12X speedup over machines with four Maxwell M40s on machine learning training algorithms is a big component of that price premium, as is the FP16 support that helps drive that performance on AI jobs.
If you compare the three generations of Tesla coprocessors based on their raw SP performance alone, the Pascal P100 does better than the Tesla or Maxwell cards, but not anything like a 12X performance jump. Nvidia has only released peak teraflops ratings for the Maxwell and Pascal cards at single and double precision, and this is with GPU Boost overclocking running at full tilt. Systems may or may not have the thermal overhead to allow this overclocking, but for the sake of argument, let’s say that they do.
In that case, the Tesla P100 offers 2.1X times the performance of the Tesla K40 and 51 percent more oomph at single precision than the Tesla M40. It only delivers 21 percent more raw SP performance than a Tesla K80. The performance per watt of the P100 on single precision work is 70 percent better than on the K40, but it is only 26 percent better than the M40 and only 21 percent better than the K80. (You can’t optimize on all fronts, obviously.)
For double precision work, the Tesla P100 has 26.5X more performance than the Tesla M40, which doesn’t really do DP, and 3.2X that of the Tesla K40 and 1.8X that of the Tesla K80. These numbers suggest to us that, at least initially, Nvidia can charge at least twice as much for raw SP and DP performance compared to the Tesla K40s and Tesla K80s, and then add on a premium for FP16, memory bandwidth, and NVLink GPU lashing.
Given these numbers, maybe a $10,500 per unit price is not so outlandish an estimate at all. A survey of the web pegs the Tesla K40 at somewhere around $5,500 list price when it launched and around $3,200 street price today, and the Tesla K80 was around $5,000 at launch and around $4,500 at street price today.
The other thing to remember is that the “Volta” kicker to the Pascal GPU for high end processing is expected by the end of 2017 for the “Summit” and “Sierra” supercomputers being built for the US Department of Energy. Very little is known about these machines, except that they will sport a second generation of NVLink that offers more bandwidth and an improved unified virtual addressing scheme across the GPUs and between CPUs and GPUs. So we could end up with a situation where there are four different generations of GPUs in Tesla accelerators in the field at the same time.
And there is nothing wrong with that, so long as the price of the older stuff keeps coming down on something resembling a Moore’s Law curve and customers can still get good work done on the older devices.


A GPU Upgrade For “Leonardo” Supercomputer But Not A Budget Upgrade
Neither scientific progress nor the budgetary process can wait for compute engine and interconnect roadmaps. At some point, an HPC center is at a cadence for upgrading its supercomputers that is difficult to change, and you get the best supercomputer you can get at any time and you try not …

TACC Fires Up “Vista” Bridge To Future “Horizon” Supercomputer
The Texas Advanced Computing Center at the University of Austin is the flagship datacenter for supercomputing for the US National Science Foundation, and so what TACC does – and doesn’t do – is a kind of bellwether for academic supercomputing. So it is noteworthy that TACC is installing its first …
Nvidia Sacrifices Profits To Preserve Revenues In The US
Making a graphics card for gamers is one thing, but manufacturing a rackscale supercomputer with over 600,000 components that burns 120 kilowatts of power, that has over 5,000 copper cables for an all-to-all interconnect mesh for 72 dual-chip compute engines, and that weighs over 3,000 pounds is another thing entirely. …
“Sunsetting”? Of course they’re “sunsetting”. The day is not quite over (sunset -> the sun is still out) = they’re still being sold! But they’re clearly telegraphed for obsolescence, as truly as night follows day.
How can Nvidia sunset existing GPUs if Pascal is essentially vaporware and will remain such for another 9+ month for vast majority of potential users (unless AWS or Google Cloud will make it available)?
Well the question is will there be a Pascal GPU that is build for the enthusiast or consumer market in the meantime? Surprisingly there was not a single mention anywhere on this. Which points me to believe probably not! Which is odd as AMD surely will release something in 2H2016
NVIDIA is launching such Pascal GPUs in June. http://www.extremetech.com/extreme/226879-rumor-nvidia-may-have-killed-maxwell-production-ahead-of-june-pascal-launch
Kind of like Apple’s iPhone strategy.
The pricing is wrong in my opinion.
When new technology released older version price will drop
The new technology price can be around older version current price or little bit higher.
In my opinion it is good if the Tesla p100 price around $ 5500 to 7000 maximum.
And I hope Nvidia will have AI service for rent
1 for p100 user to make it faster and better
2 for non p100 user to use the AI