

The new Intel Xeon processors E5 v4 product family, based upon the “Broadwell” microarchitecture, is reported to deliver up to 47%* more performance across a wide range of HPC codes. To get to the heart of these claims, we first look at why these processors can make applications run faster starting with the per-core floating-point changes that can improve even binary-only and poorly scaling applications. After that, we examine how more cores and new instructions plus improvements to the handling of virtual and physical memory increase both parallel performance and application efficiency across a wide range of HPC problem domains ranging from deep learning to Monte Carlo methods and the secure data transmission and encryption of data. Finally, we discuss how these processors make the procurement process easier as part of the Intel Scalable Systems Framework.
Improvements to the vector floating-point multiply and scalar divide are but two of the per-core microarchitecture changes that allow binary-only commercial and legacy applications to run faster. Recompilation is not required which can benefit owners of commercial codes – such as those in structural analysis and computational fluid dynamics (CFD) – that may be difficult or expensive to upgrade. Even poorly scaling codes will run faster on the new processors due to the per-core performance improvements. Of course, best performance on the Intel Xeon processors E5 v4 product family can be achieved by recompiling to utilize the new instructions and other microarchitecture improvements that benefit deep-learning, mixed HPC workloads, security, encryption, and Monte Carlo applications (to name a few).
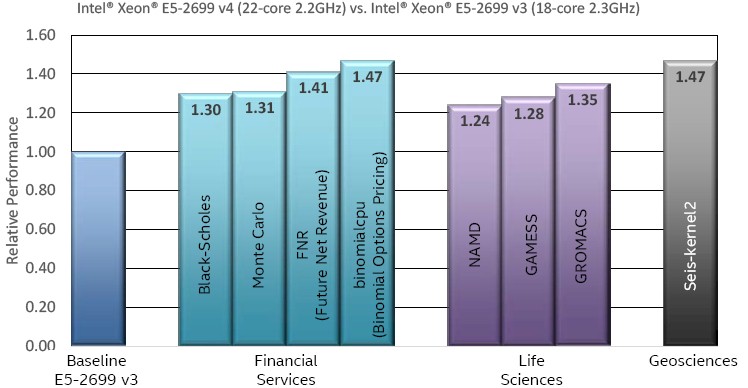
Multiply the individual per-core performance benefits by a factor of 22 on the highest core count Intel Xeon processors E5 v4 products to see the HPC benefits reported in the figure below. Both physical and virtual memory improvements – including the ability to utilize faster DDR4-2400 memory – means that these new processors can potentially improve all aspects of HPC application performance from IO DMA operations, to processing serial sections of code, as well as delivering increased performance on both task- and data-parallel applications. Even better, these new chips are a socket compatible replacement for Intel Xeon processor E5-2600 v3 on Grantley, which can make upgrades easier and more cost effective.
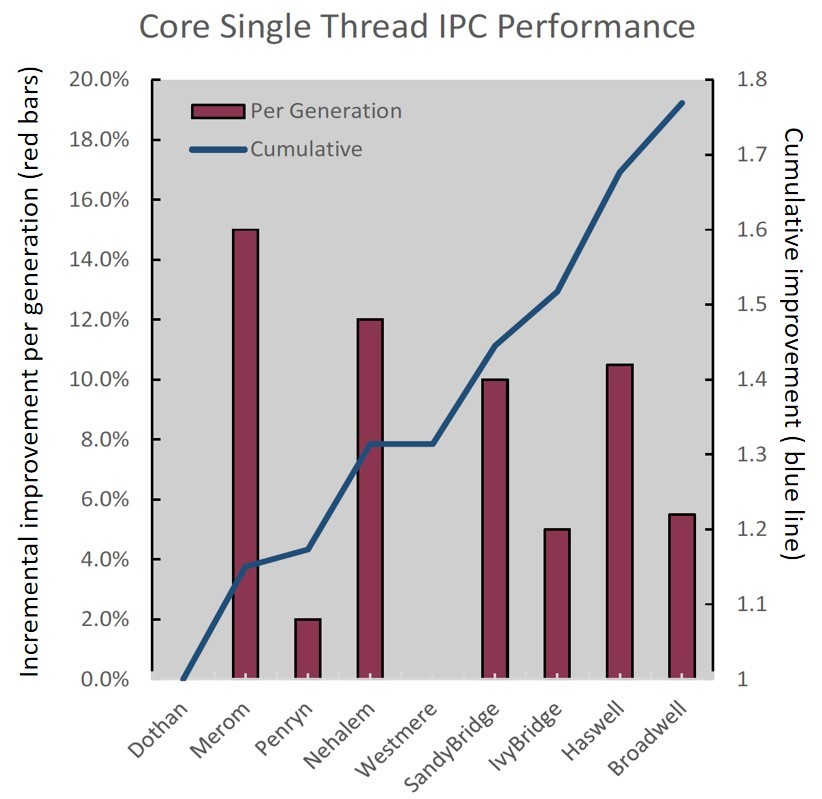
The following chart shows the increased single-thread per core performance of the Broadwell microarchitecture over previous generation microarchitectures. The Instructions Per Cycle, or IPC is an indicator of processor performance. A higher IPC means that the processor can get more work done per unit time, which generally translates to faster application performance.
Pure floating-point performance
Most HPC applications are heavily floating-point performance dependent, which is why the decrease in latency of the vector floating-point multiply from five clock cycles to three in the Broadwell microarchitecture is important which Saleh notes, “For HPC that is going to be a pretty big improvement”.
Deep learning (both during the training and prediction phases) plus a vast array of linear and matrix-multiply based applications will particularly benefit from the 40% latency reduction of the FMA (Fused Multiply-Add instruction) instruction introduced in the previous generation microarchitecture coupled with the improved vector multiply performance of the new Intel Xeon CPU microarchitecture.
| uArch | Instruction Set | SP FLOPs per cycle | DP FLOPs per cycle |
| Nehalem | SSE (128-bits) | 8 | 4 |
| Sandy Bridge | AVX (256-bits) | 16 | 8 |
| Haswell/Broadwell | AVX2 & FMA | 32 | 16 |
Figure 3: Flops per second according to microarchitecture (Courtesy Intel):
Similarly, the performance of scalar and radix-1024 divides have been improved. The divider throughput in cycles to start next (lower is better) is shown below[1]. In addition, the ADC (Add with carry), SBB (Subtract with Borrow), and PCLMULQDQ (Carry-Less Multiplication Quadword instructions now complete in one clock cycle**.
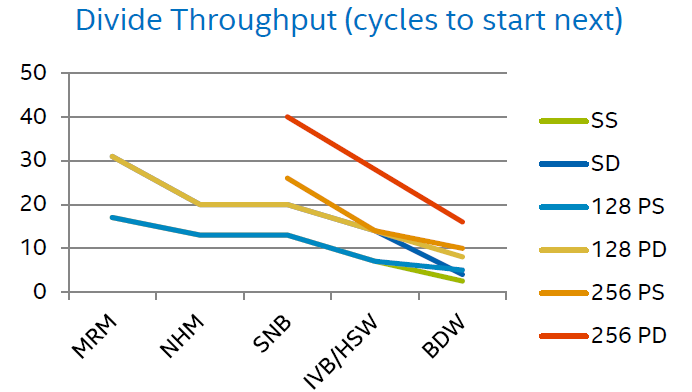
In other words, each core of a Broadwell microarchitecture processor can run many HPC applications faster simply because it can perform common arithmetic operations like multiply and divide faster. The per-core microarchitecture improvements can help make HPC applications run significantly faster – including those applications that cannot be recompiled and those that do not scale well to large numbers of cores!
The per-core microarchitecture improvements can help make HPC applications run significantly faster – including those applications that cannot be recompiled and those that do not scale well to large numbers of cores.
Memory access capability
Not only do the new processors perform arithmetic faster, they also can find and access memory both faster and more efficiently. In particular, the microarchitecture includes physical memory improvements such as DDR4-2400 memory support, and improvements to the virtual memory subsystem (specifically the translation lookaside buffer, TLB) that improve address prediction for branches and returns, reduce instruction latencies, provide a larger out-of-order scheduler, increase the size of the STLB (from 1k to 1.5k entries), and more. These improvements help the memory subsystem keep pace with the improved processing capabilities of these next generation Intel(R) processors.
HPC users will be thrilled that the hardware assist for vector gather results in approximately 60% fewer ops. In addition, the Intel AVX instructions have been optimized so that a core running these instructions does not automatically decrease the max turbo frequency of other cores in the socket running non-AVX codes. This can translate to increase mixed workload performance.

Transactional memory for parallel applications
Broadwell microarchitecture improvements can also decrease the time spent in locked, critical sections of code, which in turn can increase (potentially significantly) the performance of HPC parallel codes.
The improve microarchitecture provides a legacy compatible instruction set interface for Hardware Lock Elision (HLE) transactional execution. HLE provides two new instruction prefix hints: XACQUIRE and XRELEASE. These hints can increase parallel performance as they allow other logical processors to speculatively enter and concurrently execute the lock-protected section as shown below for a parallel hash table. The processor automatically detects data conflicts that occur during the transactional execution and will perform a transactional abort if necessary.

New Restricted Transactional Memory (RTM) instructions (XBEGIN, XEND, XABORT) provide an alternative to HLE that gives the programmer the flexibility to specify a fallback code path that is executed when a transaction cannot be successfully executed.
An XTEST instruction is also provided to determine if the execution status is in HLE or RTM.
New instructions for cryptography, random numbers, and more
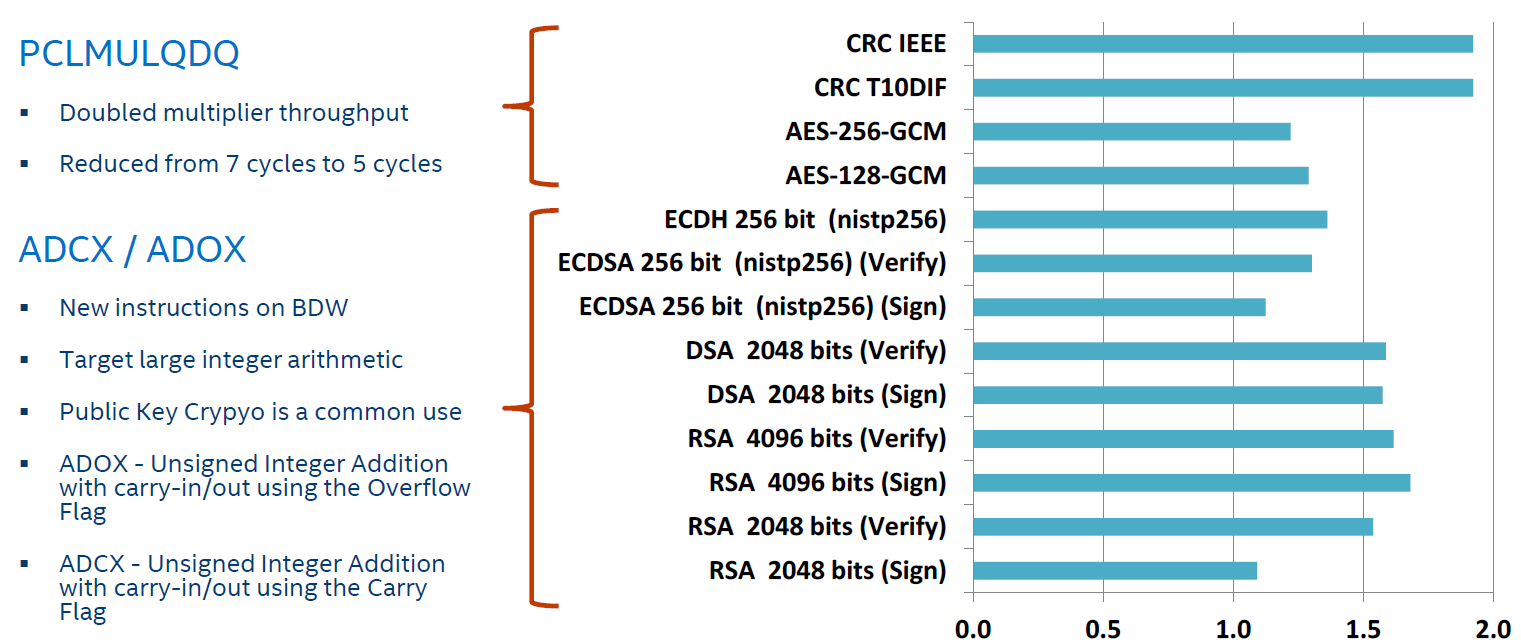
New and improved instructions increase the performance of public key cryptography (e.g., RSA) for secure data transport as well as large multi-precision integer arithmetic libraries. Faster cryptography means less time spent communicating data over secure channels and to/from encrypted files. Specifically, the new ADCX/ADOX instructions increase the performance of public key cryptography (e.g., RSA) for secure data transport as well as large multi-precision integer arithmetic libraries. Performance has also been improved for the integer PCMULQDQ instruction (latency has been decreased from 7 cycles to 5). The impact can be seen in the following figure***.
Many HPC applications make heavy use of PRNGs (Parallel Random Number Generators). The new RDSEED instruction can help as it generates 16-, 32- or 64-bit random numbers from a thermal noise entropy stream according to NIST SP 800-90B and 800-90. This instruction can provide a strong source to seed another pseudorandom number generator for security, Monte Carlo, and a wide variety of other HPC applications. RDSEED is intended for use those who have an existing PRNG, but would like to benefit from the entropy source of Intel Secure Key. With RDSEED you can seed a PRNG of any size. For more information see: https://software.intel.com/en-us/blogs/2012/11/17/the-difference-between-rdrand-and-rdseed.
With a potential 47%* performance increase at stake, it is well worth benchmarking the new Intel Xeon processors E5 v4 to see the performance they can deliver on your applications. Upgrades can be simple as these new processors are socket compatible with the Grantley platforms. It’s an easy way to significantly bump the performance of your HPC workstations and computational nodes!
The Intel Xeon processor E5-2600 v4 product family are the first processors to be part of Intel Scalable System Framework (Intel SSF) recommended configurations.
“HPC has become a ubiquitous and fundamental tool to insight, whether it’s traditional sciences, large enterprises, small enterprising, or merging usages” – Hugo Saleh, Director of Marketing, Intel High Performance Computing Platform Group
Intel SSF is a holistic approach that incorporates Intel’s existing and next-generation of compute, memory/storage, fabric, and software products, including Intel Xeon processors, Intel Xeon Phi™ processors, Intel Enterprise Edition for Lustre* software, and Intel Omni-Path Architecture. The goal is to simplify the selection process to help customers as they purchase increasingly larger system sizes and higher-performance workstations.
Rob Farber is a global technology consultant and author with an extensive background in scientific and commercial HPC plus a long history of working with national labs and corporations. He can be reached at info@techenablement.com.
* Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. Results based on Intel internal measurements as of February 29, 2016.
** Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmarkand MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.For more complete information visit http://www.intel.com/performance. Results shown are based on detailed models of the core created by Intel. The models simulations utilize over a thousand instruction sequences which are believed to approximate the expected behavior of a wide range of customer applications. They are estimates and for informational purposes only.
*** Source as of 12 January 2016: Intel internal measurements on Durango platform with Xeon-D (8C), Turbo disabled, 2x8GB DDR4-2400,CentOS 6.4, OpenSSL-1.0.2-beta3. Intel Aztec City Platform with E5-2699 v3 (18C), Turbo disabled, 4x32GB DDR4-2133, Fedora16, OpenSSL-1.0.2-beta3. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmarkand MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance ofthat product when combined with other products. For more information go to http://www.intel.com/performance. Other names and brands may be claimed as the property of others.
[1] PS is packed single, PD is packed double, SS is scalar single, SD is scalar double, BDW is Broadwell, IVB is Ivy Bridge, HSW is Haswell, SNB is Sandy Bridge, NHM is Nehalem, MRM is Memron.

The Once And Future FPGA Maker Altera
Back in 2015, when we were launching The Next Platform, a lot of stuff was going on all at the same time, which is part of the zeitgeist that we were tapping into and that we wanted to chronical upon and participate within. And Intel was front and center of …
Intel Pits New Gaudi2 AI Training Engine Against Nvidia GPUs
Nvidia is not the only company that has created specialized compute units that are good at the matrix math and tensor processing that underpins AI training and that can be repurposed to run AI inference. Intel has acquired two such companies – Nervana Systems and quickly right after that Habana …
Hope Springs Eternal For Arm Servers
IT organizations are funny creatures, indeed. On the one paw, they are eternally optimistic about the prospects for new technologies, and on the other paw, they are extremely resistant to change because of the economic and technical risks that change requires. For more than a decade now, the people who …
Great article, Rob. Thanks! On the IPC performance chart, I am trying to determine the improvement from Ivy Bridge to Haswell. If I use the blue, “cumulative” line, would I be correct at calculating the performance increase at approximately 17% – 13% = 4% increase?
We have been using two Ivy Bridge 10C E5-2690V2 3.0Ghz processors with XenServer supporting virtual desktop workloads. The virtual desktops run Autodesk Revit, which is single threaded in many of its operations. I am evaluating new servers with Haswell and Broadwell procs but due to the thermal constraints, I can no longer get a 10 core / 3 GHz processor in any form factor under a 4U server. Currently we have 1U servers so we are not going to 4U. I am trying to determine if a 2.6Ghz Haswell or Broadwell core can perform as well as a 3GHz Ivy Bridge.
Thanks for any insight you have on this!
Richard