

While parallel programming on distributed systems is difficult, making applications scale across multiple machines – or hybrid compute elements that mix CPUs with FPGAs, GPUs, DSPs, or other motors – linked by a network is not the only problem that coders have to deal with. Inside each machine, the number of cores and threads have ballooned in the past decade, and each socket is as complex as a symmetric multiprocessing system from two decades ago was in its own right.
With so many cores and usually multiple threads per core to execute software, getting the performance out of software can be a tricky business. At the world’s hyperscalers, financial services behemoths, HPC centers, and database and middleware providers, the smartest programmers in the world are often off in a corner, with pencil and paper, mapping out the dependencies in the hairball of code they and their peers have created to find out the affinities between threads within that application. Having sorted out these dependencies, they engage in the unnatural act of pinning software processes or threads to specific cores in a physical system to optimize their performance.
Pinning threads is a bit like doing air traffic control in your head, and Leonardo Martins had such an onerous task a few years back. Martins got his start in the IT sector two decades ago as an engineer at middleware software makers Talarian and TIBCO before moving to Lehman Brothers to introduce Monte Carlo simulation systems for risk management to the bank. In 2004, he moved to Barclays Capital to introduce its first Linux-based systems as its senior middleware program manager and architect, and in 2010, he was the low latency senior architect at HSBC. While at HSBC, Martins was one of the wizards that would map out the applications and figure out how to pin their threads to specific cores in a system to maximize performance – a process that might take anywhere from two to eight weeks.
This is not big deal, right? Wrong. At the major financial institutions, the trading applications are updated at least monthly and sometimes as much as 200 times a year, so having the tuning process take weeks to months means code is never as optimized as it needs to be for a competitive edge. Martins looked around for a tool that would automate this thread pinning, and when he could not find one he found a few peers and set out to create one.
Martins founded Pontus Networks back in 2010 as a consultancy specializing in the tuning of latency sensitive applications, and was joined by Martin Raumann, an FPGA designer and specialist in low latency, high frequency trading hardware, and Deepak Aggarwal, another C, C++, C#, and Java programmer with deep expertise in distributed systems who built front office and back office systems for equities, foreign exchange, and fixed income asset trading at Barclays Capital, Credit Suisse, Citigroup, ABN, and Standard Chartered. They started work on the Pontus Vision Thread Manager and filed their first patents relating to the automated thread pinning in August 2014. The alpha version of Thread Manager debuted quietly at the end of November last year with its first customer, and the product is now available and has been acquired by three customers – all of whom are in the financial services sector. It is a fair guess that these companies are probably the ones where the founders of Pontus Networks used to work and do such painstaking thread pinning work, but that is just a guess.
Several other HPC-related users in government and university labs as well as a few Formula One racing teams are kicking the tires to see how Thread Manager might remove the human bottleneck and help get tuned software into production faster. In this latter case, Thread Manager is expected to help boost the performance of the mechanical engineering design and simulation programs as well as some of the post-processing that is done on designs to test them.) The company is also getting ready to do some performance tests on Hadoop clusters as well, and thinks that performance boosts on HDFS storage will be similar to what it has seen on Extract-Test-Load (ETL) applications that front end data warehouses. (Informatica is working with Pontus Networks on these tests.)
And as you have learned to expect from reading The Next Platform, none of these organizations looking for a bleeding edge advantage are willing to go on the record with their experiences just yet – and they may never do it because of that advantage. But we can tell you anecdotally what is going on and give you the results of some synthetic benchmarks to get you started.
Thread Manager is new enough that Pontus Networks is not precisely sure how different kinds of applications will make use of the automatic thread pinning capabilities, and Robin Harker, business development director at the company, tells The Next Platform that the company is just now getting some benchmarks under its belt to prove what Thread Manager can do.
The first and most important thing is that Thread Manager is a dynamic tool, working behind the scenes as software is running and changing, rather than a static, human-based optimization process that has to be invoked every time the code (or the hardware for that matter) changes. The dynamism is import in another way.
“If you look at an Oracle Exadata, where the company owns the whole box, they pin processes, not threads, which is a bit coarser grain control,” explains Harker. “So Oracle is probably pretty well optimized to run on a single box, and even across a RAC cluster for that matter. However, if you want to add a web application server to the same box, you are adding a different application that is going to have an effect on the Oracle system. But Thread Manager doesn’t care because all it sees is threads that talk to each other, and we don’t care if they come from Oracle or Tomcat or Linux or whatever.”
So the thinking of Pontus Networks, as more and more cores and threads get stuffed into single machines because we cannot really increase clock speed anymore to goose performance, companies will want to run multiple applications on machines (even if they are clustered) and they will have an even more complex thread pinning nightmare to deal with. Hence, the automation.
The idea behind Thread Manager is simple enough to show in a single image, so here it is:
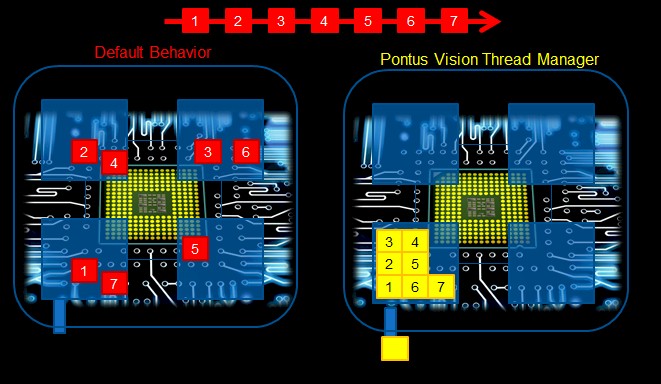
That image above shows seven different threads that are dependent on each other in a linear fashion. On the left, the processors and the operating system on a four-socket machine will disperse the application threads as much as possible to alleviate contention for cache, memory, and processing resources. But this will by necessity introduce latencies in the application as it runs. Thread Manager does the math on the dependencies and in this simplified case will move all seven threads of the application to one socket, where they can immediately share data as the crunching goes through its steps.
In the real world, the trouble is that applications are juggling dozens to hundreds to thousands of threads in many combinations and permutations on the hardware as they pipeline through the processors. This is a lot of thread dependencies to juggle at the same time.
Thread Manager has two modes. The first is a self-tuning mode which puts an agent on each node in the cluster that grabs the software and sees how it runs and then loads it up in a simulator to try different thread combinations across the processing resources to get something optimal. The Thread Manager also has a GUI that shows how threads are distributed in real time as applications run, and oddly enough, early customers are as excited about using this GUI as a thread profiling tool as they are automating thread placement because it is very, very difficult to visualize an application running with the frontal lobe all by itself. (Well, for most people.) After scoring the different threading simulations, the best one is applied to the actual application and threads are corralled to their appropriate cores and threads in the system.
With the second mode, Thread Manager can be used to model application software against hardware that is not actually installed by tweaking the simulator to look like that hardware. So not only can Thread Manager pin threads in applications, it can help system administrators and software architects figure out the optimal hardware configuration for running those applications.
One of the first benchmark tests that Pontus Networks has done is on a foreign exchange application at one of the major banks. Here’s the application flow:
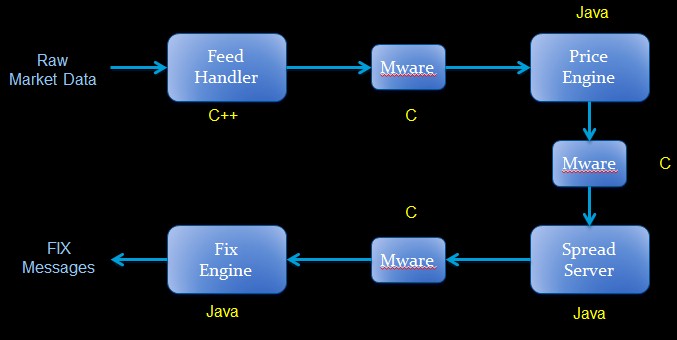
This particular foreign exchange application is comprised of a mix of C, C++, and Java applications that were coded by the bank and supplied by third parties. The Thread Manager software allowed for the application to be collapsed down from ten physical servers down to one (a fairly beefy box, mind you), but after the automated thread pinning, the overall latency of the application on systems running Red Hat Enterprise Linux and the Oracle HotSpot Java Virtual machine were reduced by 270 percent and the capital expenses were dropped by 50 percent. On the same machines equipped with the Zing JVM from Azul Systems, which had about half the latency of the HotSpot JVM on RHEL machines itself, Thread Manager could reduce latencies on the foreign exchange application by around 56 percent.
On another benchmark test using IBM’s Datastage ETL software, which simulated a retail banking application that has thousands of databases where duplicated customer names need to be removed daily from the system as new information is pumped into it, the ETL job out of the box from IBM took around ten hours to complete. Firing up Thread Manager reduced that to seven hours. Depending on the load on the system, Thread Manager sped up the applications by between 26 percent and 66 percent.
On the PGBench retail banking benchmark based on the open source PostgreSQL database, which simulates the operations of a bank with 100,000 bank accounts and ten tellers, the raw benchmark was capable of delivering 5 transactions per second with an average latency of 3.99 milliseconds and a standard deviation of the latency of 10.65 milliseconds. With Thread Manager added to the system, the throughput went up to 6 transactions per second, a 20 percent boost, and average latency fell by 19.5 percent to 3.34 milliseconds. Perhaps more importantly, the standard deviation of the latencies collapsed down to 3.63 milliseconds, meaning that the resulting system provided more deterministic results overall. This is a big deal for financial institutions, and indeed, any high performance applications. The long tail always needs to be clipped. This particular test was done on a Lenovo System x3850 X6 machine with four Xeon E7 processors with a total of 96 threads and 256 GB of memory.
Thread Manager will be soon be tested on modern infrastructure such as Docker containers and the Mesos workload scheduler, and Harker says there are plans to test the MySQL database and some other software, such as virtualized servers running a hodge-podge of applications, too. If you want to help out, Pontus Networks is game. Thread Manager runs on X86 machines supporting Linux operating systems with the 2.4 level kernel or higher as well as machines running Microsoft’s Windows Server 2008 and higher. The automated thread pinner is also available on IBM’s Power processors and is supported with either Linux or AIX operating systems.
The Thread Manager software stack is licensed annually for $1,400 per socket, and Harker says that the typical financial services customer is running their applications on clusters with at least 100 nodes and 200 sockets. So this could add up to some pretty big money pretty fast for Pontus Networks, given how expensive and time consuming it is to do thread pinning by hand.

In case you are reading this now, Pontus has just finished doing the first set of Hadoop thread manager benchmarks; here’s the link to the case study:
https://www.google.co.uk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwieka630fDNAhUGCcAKHbreCFsQFggpMAI&url=http%3A%2F%2Fwww.pontusvision.com%2Fwp-content%2Fuploads%2F2013%2F09%2FHadoop_PVTM-White-Paper.pdf&usg=AFQjCNHuqP8u3tSYR2csnB84WI-QrlEVew&sig2=3c4Y9_kxIpBo6GwcAfDlAg