
This is the third in the series of articles on The Machine, a future system coming from Hewlett Packard Enterprise. Up to now, we have gone out of our way to avoid talking about what really makes it The Machine. For all of the benefits of having persistent memory – we will be calling it fabric memory in this article – close to and byte addressable by the processors, The Machine really shines when the notion of a node gets replicated a lot of times.
Rather than a few terabytes of persistent memory, the node replication also multiplies this very same persistent memory into and above the petabyte range, and all of it still accessible by all processors. So, there we start with this article, The Machine combines closely couple persistent memory. (You can see the first article discussing The Machine’s overall architecture at this link, and the second one talking about its memory addressing here.)
In traditional distributed-memory clusters, scads of nodes get hung together using I/O communication links like Ethernet or InfiniBand, and more recently PCI-Express, to name just a few. Memory in such distributed clusters is completely disjointed; a processor of one cannot access the memory of another. Data sharing requires communications-based copying between the nodes. Some wonderful things have been done – and a lot of money has been spent designing and doing it – using such I/O linked inexpensive compute nodes, but sharing of even moderately changing data remains a real problem.
On the other end of the spectrum, a cache-coherent NUMA-based shared-memory cluster allows all processors on any node to access all memory, historically all DRAM memory, as well as all cache throughout the system. Sharing here is natural, and the performance degrading effects of the longer-latency memory can often be managed. But, largely due to the need for the hardware to globally manage cache coherency, “scads of nodes” becomes instead “a goodly number of nodes.”
Still, in both of these quite different memory models, the basic building block is a compute node containing lots of DRAM and often multiple chips of processor cores.
With The Machine, we seem to have something different, and yet the same. The Machine, too, is a multi-node “system;” the design of the first is said to have 80 such nodes. As shown again in the block diagram of a node, The Machine is linked together by what appears to be each node exporting some high bandwidth optical link to some notion of a switch, here called the Innovation-Zone Board. Not shown is that each node also exports Ethernet, as would be expected for a traditional distributed-memory system.
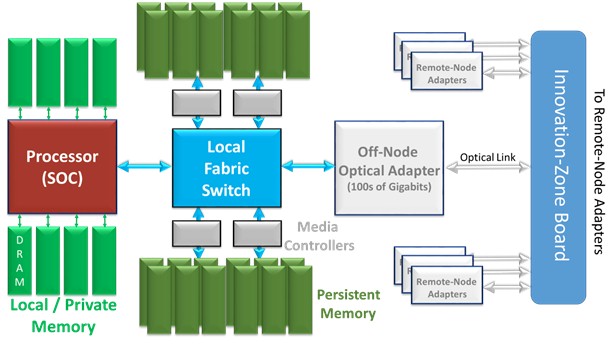
So far, perhaps, it does not seem all that different. At some level, the optical adapter could simply be driving Ethernet. In such a traditional I/O-linked cluster, each of the nodes have their own distinct real address space. In this same context, the only thing new about such a system would be that each node also has some closely coupled, byte-addressable persistent memory. Stopping here, though, this is just a distributed system with Persistent Memory on each node. Cool, useful, even innovative, as far as this goes.
In The Machine, though, each and every byte of the Persistent Memory in the entire multi-node system is accessible by any processor, no matter the node. Directly. Load/Store. No I/O enabled copying required. Considering this inter-node optical link to be The Machine’s fabric for enabling this, the preferred name for this globally accessible persistent memory is fabric memory. We will follow suit.
Each processor of every node has the physical means of directly accessing any of The Machine’s fabric memory. But, as a reminder from previous articles, only processors residing on the same node as the node’s Local/Private memory can access this volatile DRAM memory.
It is obvious that for local/private memory accesses (i.e., of local DRAM), this is by no means a NUMA (Non-Uniform Memory Access) system; only local DRAM memory is accessible and all such local DRAM has essentially an equal access latency.
It happens that for fabric memory, although NUMA-like – where local persistent memory is more rapidly accessed than the persistent memory of another node – the actual latency of accessing persistent memory is long enough that the difference between local and remote accesses can be largely ignored. This difference, even if noticeable (and we don’t know that it is), is also intentionally hidden by The Machine’s programming model. Consider the following from HPE’s Paolo Faraboschi and the Hewlett Packard Labs team:
“We like to think of the first prototype of the machine as having a 2-level main memory hierarchy: a volatile performance tier, and a persistent capacity tier. In “traditional” NUMA systems, different threads have different latencies to the same memory location. So, a programmer is forced to allocate memory and compute in close proximity for optimal performance. In our system, all threads are at the same distance to the same memory location. In other words, latency is a property of where you allocate memory, not where you allocate the compute. This is consistent with our “data centric” view of the world, and we think it makes the programmer life easier. For example, you do need to worry about identifying “hot data” (in DRAM) and “warm data” (in fabric memory), but once you do that, you are free to allocate the threads anywhere you want, since they will all be (approximately) equidistant from that location. In lack of a better term, we internally refer to this as “KUMA” (kind-of-UMA)… “
OK, not NUMA, but more importantly for inter-node (as opposed to intra-node) accesses of fabric memory is not a cache-coherent NUMA system, either. The scope of cache coherency is limited to only the processor caches residing on individual nodes. A processor on any node can potentially access any data block of fabric memory on any node, and it can also hold such blocks in its cache, but cache coherence is maintained only amongst the processors on the same node as that cache.
You can see this effect in the following animation, using MIT’s Scratch. A data block residing in Node A’s Fabric Memory is separately accessed by four different processors, two each on Nodes A and B. Each processor, as a result, gets a copy of that block in its own cache. One of the processors on Node A changes that block (making it red), invalidating the copy in the other Node A processor’s cache. This works because The Machine supports cache coherency within each node (so here Node A). But The Machine does not support inter-node cache coherency; the change made to the shared data block by the processor on Node A, although perceived by the other processor on Node A, is not perceived by any processor on Node B. Unlike in a cache-coherent NUMA-based system, here Node B’s processor caches remain unaware of the change, keeping the previous, now stale, version of that data block. This remains true even when the changed block is flushed from the Node A processor’s cache and returns to memory.
https://scratch.mit.edu/projects/89489652/
Much of the reason that full cache-coherence is normally supported is to maintain the illusion for software that processor caches don’t really exist; from software’s point of view, which perceives all accesses as though coming from memory, the cache is transparent.
Large cache-coherent NUMA systems do exist, but there is a cost to performance and design complexity, especially when the cache-coherency hardware cannot easily determine the locations of caches holding data blocks. For example, in our simple animation, with node count multiplied 10s to 100s of times, how does a processor on Node A, wanting to make a change to its cache line, know what other nodes need to be contacted to find all of the other processors with caches containing that same data block? It frequently doesn’t know, so all nodes end up being asked.
The Machine design has made the determination that it should not be the hardware’s responsibility alone to ensure that inter-node caches are maintained in a way that is transparent to software. Again, the cache is transparent as long as processors accessing some shared data all reside on the same node. This remains true whether the local caches hold data blocks from local DRAM, local fabric memory, or remote fabric memory. Indeed, just as with most modern caches, if these processors find the needed data – no matter the original source location – in a local processor’s cache, cache fills are done from those local caches rather than any memory; given fabric memory speeds, this is a performance win.
Sharing of data intra-node is perceived as the more typical case; inter-node sharing on The Machine is more atypical (and not even possible on truly distributed-memory clusters). Inter-node sharing of the same locations in fabric memory – say a common database table – is completely possible and indeed reasonable on The Machine. Sharing without modification, where processors on multiple nodes are only reading from fabric memory, is also completely reasonable and efficient to support; think program code here as well as data.
Inter-node processors, though, are also allowed to modify that same Fabric Memory-based shared data. It is here that some special handling is required to manage such sharing. A Node A wanting to write changes to a database record – one whose contents might be in a Node B’s cache – needs to ensure that the Node B’s cache does not continue to work with stale data after the change. A protocol, supported by an API in The Machine, arranges to the desired outcome.
As you have been seeing, this is one of a number of places in The Machine impacting your normal mental image of how to program. Most of the program model remains much as you would expect. Intra-node cache coherency keeps the program model much as you expect it to be for data sharing within the bounds of a node. Expanding to execute inter-node sharing – something that can’t be done anywhere as well or as simply across the distributed-memory nodes of a traditional cluster – needs a slightly different programming model, largely because it is different; inter-node fabric memory can be easily accessed in The Machine (unlike distributed memory clusters), but doing so is not kept cache coherent (unlike cache-coherent NUMA systems).
Of course, The Machine’s designers are well aware of this potentially extra complexity and provide software libraries for allowing such shared and modified inter-node data to be globally visible when it needs to be. The full system’s cache is just not transparent to all Fabric Memory accesses.
In the next article in this series on The Machine, we will be looking at addressing and related security. How does a program accessing into fabric memory know how and where to access and, given that any thread executing on any processor of any node can access any fabric memory, how does The Machine ensure that only those with the right to do so access only their allowed portions of fabric memory?
Related Items
Drilling Down Into The Machine From HPE
The Intertwining Of Memory And Performance Of HPE’s Machine
Weaving Together The Machine’s Fabric Memory
The Bits And Bytes Of The Machine’s Storage
Operating Systems, Virtualization, And The Machine
Future Systems: How HP Will Adapt The Machine To HPC


Lawrence Livermore To Surpass 2 Exaflops With AMD Compute
As the steward of the nuclear weapon arsenal for the United States government, it is probably not an overstatement to say that Lawrence Livermore National Laboratory, one of the main supercomputer and scientific research facilities operated by the Department of Energy, is keenly interested in bang for the buck. And …

HPE Throws Everything At AI – And AI At Everything
Hewlett Packard Enterprise has kept a steady drumbeat for much of the year as it looks to position itself as the go-to IT hardware and software vendor for the rapidly expanding AI market, which has grown from chatbots to AI agents in under three years. To that end, HPE is …
Ethernet Consortium Shoots For 1 Million Node Clusters That Beat InfiniBand
Here we go again. Some big hyperscalers and cloud builders and their ASIC and switch suppliers are unhappy about Ethernet, and rather than wait for the IEEE to address issues, they are taking matters in their own hands to create what will ultimately become an IEEE standard that moves Ethernet …
Be the first to comment