
Upstart ARM server chip maker Calxeda, known as Smooth Stone in its early days in reference to the five stones that David picked out of a riverbed to kill Goliath the giant with his slingshot, went bust back at the end of 2013 after a five year run to try to be the world’s first volume supplier of ARM server chips. It was an idea that was ahead of its time, or at least ahead of software development, and Calxeda didn’t make it.
But, as it turns out, the assets and the intellectual property behind Calxeda lived on and as we predicted when Calxeda shut down two years ago, the very clever Fleet Services integrated switching that Calxeda had cooked up for its EnergyCore family of ARM system-on-chip would find a use.
The integrated Layer 2 switching that is embedded on the EnergyCore chips is now being revived by Silver Lining Systems, a startup that is owned by AtGames Holdings, which is Taiwanese company that is roughly analogous to GameStop in the United States. AtGames sells legacy online games and their consoles, like GameStop, but is also ramping up a new online gaming service, first in Taiwan and then in China, that is the interesting bit as far as The Next Platform is concerned.
AtGames was going to be Calxeda’s biggest initial customer, and it had tapped the second-generation “Midway” ECX-2000 ARM processors for the servers underpinning its online gaming service. Contract manufacturer Foxconn built a density optimized hyperscale server based on the ECX-2000 that AtGames acquired, which was pretty much the only relatively high volume customer for the Calxeda chips.
Other vendors also shipped Calxeda chips in their products. Hewlett Packard Enterprise, through it was not called by that name back in November 2011 when its “Redstone” hyperscale servers debuted, tapped the earlier 32-bit Calxeda ECX-1000 chip – based on ARM Holding’s 32-bit Cortex-A9 cores – as the initial compute engine for those machines. The following year, when HPE launched the “Gemini” Moonshot follow-ons to the Redstones, which were never commercialized, the initial machines were based on Intel’s server class Atoms, much to the chagrin of Calxeda at the time. After a bit of time in the sun for Intel on Moonshot, ARM-based compute cartridges from Calxeda, Applied Micro, and Texas Instruments appeared.
The Midway ECX-2000 processors were based on Cortex-A15 cores, which process data in 32-bit chunks but which have 40-bit virtual memory addressing so the resulting server node can support up to 16 GB of main memory. While the Cortex-A15 cores can push up to 2.5 GHz, Calxeda topped them out at 1.8 GHz to keep the thermal envelope down. The Midway ECX-2000 chip had four cores, just like its predecessor, and it was etched using well-established 40 nanometer manufacturing processes from Taiwan Semiconductor Manufacturing Corp, just like the EXC-1000 was.
For the purposes of this story about networking, it is the Fleet Services integrated and partially software-based Layer 2 Ethernet switching that was embedded in the EXC-1000 and the ECX-2000 that is interesting. That fabric implements an 8×8 crossbar between the four cores on the die and the Ethernet ports that connect them to the outside world. This crossbar has 80 Gb/sec of aggregate bandwidth, which is not too shabby even in today’s world, and has enough MAC addresses in its transistors and microcode to allow for up to 4,096 nodes to be connected to each other using a number of different topologies. The ones initially supported by Calxeda were mesh, butterfly tree, fat tree, and 2D torus topologies, and bandwidth coming off the virtual ports on the switches could be allocated in chunks of 1 Gb/sec, 2.5 Gb/sec, 5 Gb/sec, and 10 Gb/sec capacities. The key thing was that these network topologies and the integrated distributed switching allowed for all of those nodes to be hooked to each other without the need of top-of-rack switches. This would eliminate a large amount of the cost of networking from a compute or storage cluster, as you might imagine. Which is why Calxeda went that route.
The problem with this approach is that the network was tied to ARM more than ARM was tied to the network, and moreover, Calxeda ran out of money before it could get its 64-bit and ARMv8-compatible “Sarita” and “Lago” processors to market in 2014 and 2015 using TSMC’s 28 nanometer processes. These chips were expected to have a next-generation distributed Layer 2 Ethernet fabric that could extend to more than 100,000 nodes – although the number of hops it would take to make such a large cluster was never revealed and it very likely was not a small number at that.
But, here’s the important thing. If what you want to do is interconnect the nodes on a few racks of servers with a few hundred nodes, then the Fleet Services fabric that was embedded in the Midway ECX-2000 chips will work just fine and there is not that many hops between nodes and the performance will probably be acceptable. (One issue with the Fleet Services distributed switch, we are told, is that if you get much beyond a few racks of servers, building the network routing tables can take more than a few hours, and this is not an acceptable timeframe.)
In any event, Silver Lining Systems is peddling the hyperscale servers based on the Midway chips as well as freestanding implementations of the Midway chips on network cards that will allow for the Fleet Services fabric to be used with any server that has PCI-Express links between peripherals and the processor complex – ARM, Xeon, Atom, or whatever has a driver and operating system support.

The Silver Lining Systems servers are called the “Pismo” Cluster Compute Server A300, and they cram a dozen server sleds into a single 2U rack-mounted server chassis. Each sled has four of the ECX-2000 processors running at only 1.5 GHz on it for a total of 48 processors and 192 cores in a 2U enclosure. That yields a maximum of 1,008 processors and 4,032 cores in a single rack, and you can pack it all the way to the top because you don’t need a top of rack switch. The nodes are a little light on memory, with only 8 GB per socket, but each node also has a 512 GB M2 flash stick for extra memory. The nodes in the Pismo systems are using 10 Gb/sec ports. The EXC-2000 chip delivers a total five links: four XAUI ports to link the servers to each other in the topologies, and one to act as an uplink. The port-to-port latency hop between nodes takes about 200 nanoseconds, which is pretty fast. The integrated fabric also supports the Link Aggregation Control Protocol, allowing for up to a dozen of the ports coming out of the back of the Pismo chassis to be lashed together into a virtual pipe delivering 120 Gb/sec of bandwidth.
Here is one way to link the servers in a single chassis together, which is a 2D mesh fabric configuration:
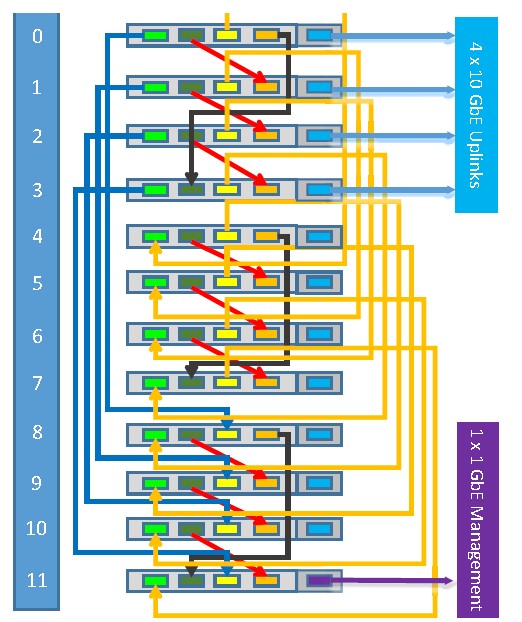
Sources at Silver Lining Systems tell The Next Platform that the resulting cluster with the integrated distributed Layer 2 Ethernet network can reduce networking costs by 55 percent compared to using modern Nexus switches from Cisco Systems and ConnectX adapters from Mellanox Technologies, and can reduce the network power consumption by around 55 percent, too.
Silver Lining is selling a free-standard adapter card with the ARM cores and memory slots deactivated and configured as a fabric interconnect adapter, with the development code-name “Newport” sold as the FIA-2100.

This card costs $250 and has four SFP ports for linking nodes across and within racks and one SFP+ port for an uplink, just like the implementation that is native on the compute boards of the Pismo server. As with the integrated networking, the uplinks are used to hook into the aggregation layer of the network, where multiple racks or rows are hooked to each other. The Fleet Services fabric tops out at 4,096 nodes, remember, which is only four racks at the density that the Pismo servers deliver. It could be the same or more racks, depending on the density of the ARM, Atom, Xeon D, or Xeon servers linked to each other using the fabric.
The FIA-2100 adapter card supports Red Hat Enterprise Linux and its CentOS clone, SUSE Linux Enterprise Server, Canonical Ubuntu Server, Oracle Linux, Microsoft Windows Server, FreeBSD, and VMware ESXi (which is a hypervisor that acts sort of like an operating system as far as network adapters are concerned).
There are a few interesting things about using the former Calxeda Fleet Services fabric – which has not been given a catchy name by Silver Lining – as an adapter card. First, it breaks the network free of the compute where this makes sense. But equally importantly, those Cortex-A15 ARM cores on the network adapter can be activated and used to do in-line processing of data as it flits around the network, lightening the load on the compute in the servers, whatever it might be based on. The latency is a bit higher on a port hop, at 218 nanoseconds, compared to the integrated Layer 2 switching used on the EXC-2000 as compute, but that additional 18 nanoseconds because of the time over the PCI-Express bus seems acceptable.
Microsoft has used FPGA accelerators on network interface cards to create what are called “smart NICs” for the servers that comprise its Azure cloud, and the rumor is that Amazon bought Annapurna Labs, another upstart ARM chip maker, about a year ago specifically to create its own smart NIC for the Amazon Web Services cloud. Amazon has just launched since used the Annapurna ARM chips in a variety of Wi-Fi gateways and home storage arrays that feed into its various AWS services for storage. Solarflare and Mellanox Technology have their own smart NICs that employ FPGAs, too, which we will cover in a future story.
For those who want to use the former Fleet Services distributed Layer 2 switching in their own system designs and more tightly integrate it with the backplanes of those systems, Silver Lining plans to make a freestanding version of the switch portion of the ECX-2000 chip available. This chip, code-named “Cashmere,” will be used to implement the same networking setups as the integrated network on the ECX-2000 chips, and is expected to be part of future proprietary and Open Compute hyperscale system designs. Here is the Cashmere block diagram:

The word we hear is that there are a number of designs being done in China right now that are being cooked up to use this ASIC, which will start sampling in May this year. No word on who is looking at it, and we have no idea what this standalone fabric chip might cost. But it should be well under the cost of a full adapter card, and being implemented in the 40 nanometer TSMC processes, it should not be terribly expensive.
As far as we know, Silver Lining is amenable to any of the ARM server chip makers licensing the Calxeda technology and either integrate it on their chips or put it on their SoC packages with PCI-Express links or embed it in the system backplanes. Server makers will be able to buy the freestanding fabric chip, too, if they want. So this could be another networking fabric adopted by portions of the datacenter where 10 Gb/sec ports are plenty fast enough.
Moreover, Calxeda had some pretty bold claims that it could extend that Fleet Services distributed Ethernet fabric, stretching it to span over 100,000 nodes. This would require some interesting engineering, we think, but none more than what Google, Facebook, and Amazon have all done to create their datacenter-spanning Clos fabrics. With the hyperscalers having shown the way, Silver Lining could pick up where Calxeda left off and try to create a scalable Ethernet fabric that rivals anything that the network giants and hyperscalers have put together. Or, it could boost the speeds of that future – and never delivered – Fleet Services 3.0 fabric to 25 Gb/sec and maybe only span 40,000 nodes or 50 Gb/sec and only do 20,000 nodes or 100 Gb/sec and only do 10,000 nodes. Any way you slice it, that is still a lot of nodes, and it is about as big as the average cluster size at Google, for instance, and Silver Lining could get some traction if it opens up the software stack – which hyperscalers and HPC shops will demand and which many enterprises will want.
There is no indication that Silver Lining is being this aggressive in its business plans, but it would be fun to see it try to do more and push the switching envelope in the datacenter as Calxeda once was trying to do.

Be the first to comment