
The hyperscale datacenter operators of the world take a certain kind of pride in breaking technologies and finding new and better ways to scale compute, networking, and storage. But as many of them have said many times, they would gladly use a commercial product in place of a homegrown one if they could only find one to do the job.
Object storage is one of the areas where hyperscalers were forced by necessity to innovate, and a handful of commercial-grade products, such as Web Object Scaler from DataDirect Networks, Atmos and Centera from EMC, and sdNET from Cleversafe (just acquired by IBM), and the RING from Scality, just to name a few, were developed in parallel. In the open source community, the Swift object storage created by Rackspace Hosting became a core component of the OpenStack cloud controller it created with NASA, and Ceph, now controlled by Red Hat, was another open source alternative and one that will eventually support block and file data access methods atop object storage if the roadmap pans out.
If file systems could scale in terms of their storage capacity and performance, object storage would not have been necessary. Companies would not have sacrificed the ability to amend existing data through a file system for the ability to scale data far and cheaply if they didn’t have to make that choice. But file systems, which top out at millions of files and have locking mechanisms for that amending of data that slows them down and limits their scale, get more expensive as you grow them. Object storage starts with the assumption that data will be immutable and therefore not need locking mechanisms and then creates a giant pool of storage that can contain potentially trillions of unique objects – an element of clickstream data or a cat photo – that can scale linearly in terms of performance, capacity, and cost.
The cost and scale differences between file and object storage are dramatic, and that is what is driving Ceph and Swift from the clouds into the enterprise. Red Hat is the main commercializer of Ceph, after having acquired Inktank for $175 million in April 2014, and its biggest endorsement to date is Yahoo dumping its MObStor homegrown object storage and moving to Ceph earlier this year. On the Swift side, commercial-grade software is being supplied by SwiftStack, which is trying to ride the OpenStack and object storage waves at the same time straight into enterprise and web company datacenters. In fact, Mario Blandini, vice president of marketing at SwiftStack, tells The Next Platform that a top five website (we are not sure which one) is now using SwiftStack in production. That would make two shifts from homegrown to commercial this year among the biggest web companies – more could be on the way. But that, oddly enough, is not the primary focus for SwiftStack.
Embracing Swift And Then S3
The OpenStack cloud controller project was founded by Rackspace Hosting and NASA back in the summer of 2010, with Rackspace contributing the Swift object storage and NASA contributing the Nova compute. SwiftStack was founded by Joe Arnold, the director of engineering at platform cloud provider at EngineYard and a co-founder of the Cloudscaling distribution of OpenStack, and Anders Tjernlund, who also did a stint at Engine Yard as well as a number of other open source startups. The company has raised $23.6 million in three rounds of funding from Mayfield Fund and OpenView Venture Partners and has grown to 45 employees, including John Dickinson, the Swift project technical lead. SwiftStack shipped the first release of its software in July 2013.
SwiftStack now has more than 50 customers, with its biggest customers managing tens of petabytes of storage, including eBay, Cisco Systems, Hewlett-Packard, Mercado Libre, DreamWorks Animation, Ancetry.com, Disney Interactive, and Autodesk. SwiftStack is focusing sales on the media and entertainment, web, life sciences, and tech industries where it expects object storage to take off earliest and fastest.
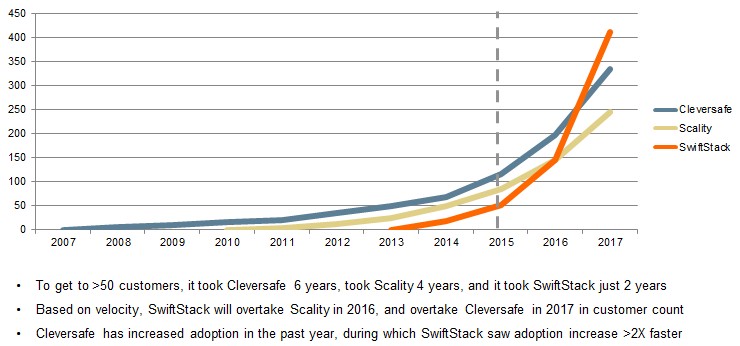
As the chart above shows, the company is projecting that it will overtake Cleversafe and Scality in the coming years, thanks in large part to the S3 support that the company is adding with its SwiftStack 3.0 release that just came out. (SwiftStack did not put Ceph customer counts in its comparisons, which would have been interesting.) We will circle back a few years hence and see how this played out.
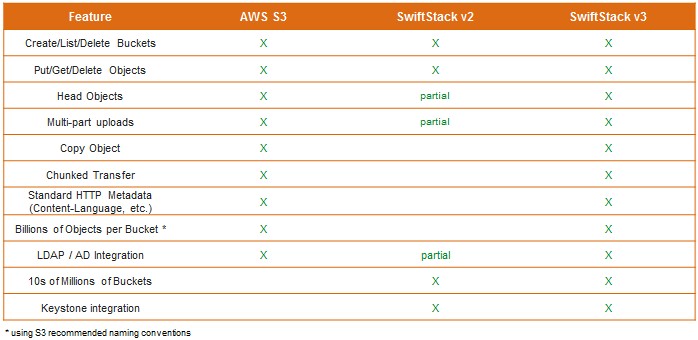
The SwiftStack 3.0 commercial product now speaks the S3 object storage APIs and protocols so well that applications so no know they are not talking to the real Amazon Web Services for storage. This S3 support is much broader and deeper than what has been available in prior SwiftStack releases, and these features are not being contributed back to the Swift community but are part of the commercial-grade SwiftStack product.
“There are no middleware features in the Swift open source project that allow you to speak S3, and the OpenStack folks, who are very religious, will say that you should use Swift,” explains Blandini. “It is kind of like speaking French – they are very specific there. But we realize that the lingua franca for cloud object storage is S3, and while there are some advantages to the Swift APIs, oftentimes if you are doing more basic stuff, the S3 APIs are awesome.”
Swift has some large users on the public cloud, to be sure, but S3 is no slouch either. Blandini says that Rackspace has north of 300 PB of capacity on its Swift storage, and that HP’s Helion cloud, which is in the process of being shut down by the newly free-standing HP Enterprise, has hundreds of petabytes of capacity under management by SwiftStack, as it turns out. Doing the math backwards from the 5.7 cents per GB per month that Amazon has for S3 and some estimates of its revenues, he calculates that S3 has well over 1 EB of storage. But enterprises are somewhat nervous about putting data in the public cloud.
“The inhibition to put data in the public cloud is not just there because of the technology, but because of privacy issues – Edward Snowden and the Patriot Act and all that,” says Blandini. “Enterprises have not really embraced public cloud, but Amazon is making more than $1 billion a year on S3. People are doing it, but certainly not everybody.”
SwiftStack is banking on a few things when it comes to enterprises, and the first is that they will want to store plenty of their data on premises and in formats that are compatible with cloud providers. The other is that object storage is going to grow to dominate the datacenter and the cloud.
Let’s take a look at where the data at rest is today and where it might be a few years from now. If you were to draw a pie chart of all of the data at rest, says Blandini, about 70 percent of all data is unstructured, with 10 percent being in object storage and 60 percent being on traditional storage with file systems. There is no file storage to speak of on the clock, he says, and block storage, which supports the relational databases and other structured data of the world, makes up the remaining 30 percent of the data at rest. There is some block storage on the cloud, of course, representing maybe 20 to 30 percent of the total, but falling as object storage comes to dominate.
The move away from block and file storage is not a new trend, but a persistent one driven by technology and economics. Years ago, as companies started hoarding more data, the business for filers started to outstrip that of block storage. The interesting bit is that the providers of backup and archiving tools only spoke to filers for many years, and now that they are increasingly supporting S3 and Swift object protocols, the amount of capacity dedicated to object storage is growing even faster than it might otherwise thanks to the storing all of our digital lives on consumer-facing hyperscale apps like Facebook and Google.
If you play the current storage trends forward, the mix of unstructured data versus structured data will continue to diverge, and the increasing adoption of NoSQL databases as adjuncts or replacements for relational databases underpinning new-fangled applications will accelerate the unstructured part of the data at rest pie, too. (With NoSQL databases, the data is in an unstructured format while its metadata and its cache provides a structured format for the applications to access the data.)
“The only thing that is going to live in block storage, whether it is all-flash or persistent memory storage, is the parts that help fetch the data from the object store,” Blandini predicts. “My vision of the future – and this is probably ten years out – is that people will need so little block storage that it will fit into persistent memory linked by a fabric, maybe 100 Gb/sec Ethernet linking it all together. This persistent memory will be more than enough to do all of your block storage. In this world, the only type of block storage will be this kind of block storage because it is cost effective and it is the fastest block storage you can possible make, a lot faster than all-flash arrays. And, while I admit that we are a little bit biased since we are an object storage company, I think everything else becomes object storage, which would be good enough if complemented by technologies such as caching and acceleration.”
The economics seem to be in favor of object storage. Blandini says that 1 PB of scale-out NAS filers can run around $2.5 million including three years of support, but putting SwiftStack on some racks of generic storage servers to deliver that same 1 PB will cost around $1 million. About 80 percent of the cost of that SwiftStack object storage is from disk drives, with 5 percent coming from processors, cache memory, and enclosures and about 15 percent coming from SwiftStack software licenses and support. By the way, SwiftStack only charges for the amount of usable data, so if you do what it recommends, which is have two copies of the data locally and two more copies of the data at a remote datacenter that is synchronized, you only pay the software license and support for the first copy. If you want more resiliency and want to add more copies of data, there is no increase in the software license fee, although you will have to buy more hardware obviously.
SwiftStack runs on X86-based storage servers, and can scale up to hundreds of petabytes, which is plenty enough for all but the very largest enterprises, hyperscalers, and service providers. (And maybe even them, too, if they spread their data across multiple storage clusters to reduce the blast area for when something goes wrong.) With the 3.0 release, SwiftStack is supporting erasure coding data protection for the first time, and is implementing Intel’s Intelligent Storage Acceleration Library, or ISA-L, which has circuits to accelerate erasure coding functions in more recent Xeon processors.
The SwiftStack storage has an out-of-band management controller, and the 3.0 release allows for snapshots of the controller to be put out onto the object storage itself and then restored to a different machine in the event that the controller fails. The object storage would run headless for a while, which is fine so long as you don’t need to make configuration changes. Multiple controllers can be used in a failover configuration, too, and as metadata grows, customers can deploy the SwiftStack controller on beefier hardware to provide more performance. As yet, SwiftStack has not delivered a scale-out clustered controller, but it is reasonable to expect one in a future release.

Swiftstack 3.0 features looks interesting – but where’s information about it’s performance (including comparison with S3 peformance) ? At PB scale they do matter at least as much as features.
Quoted pricing (1M$/PB) looks very strange since enterprise-grade SAS3 drives (2-6TB) only cost 55-75K$/PB so even with erasure coding overhead, enclosures, CPUs, RAM, 100GbE switches etc it should cost MUCH less than 1M$/PB – probably under 250K$ and definitely under 400K$.
Or does 1M$/PB assume all-flash storage (in which case 1M$/PB seems plausible)?
What’s the cost of the Swiftstack 3.0 sw and support – per server or per PB or whatever?
Well, looks like SwiftStack’s control plane or controller, constitutes a single point of failure, which would indicate that it is not a true peer-to-peer architecture. Yes, SwiftStack should get busy with implementing a scale-out clustered controller.
The article is informative, but fails to mention how many of the AWS S3 commands SwiftStack v3 actually implements. Hint: there are 51 of them. Also, can SwiftStack tier data from SwiftStack v3 to AWS S3 or Glacier?
You are correct in that both types of storage accounts offer the same reliability, scalability, and performance. The difference lies in access to cool storage. In a general storage account, you do not have access to cool storage.