

There was something ironic about meeting Mike Curtis, the vice president of engineering at Airbnb, in a hotel in lower Manhattan. It was like being on enemy territory, and Curtis did so because he was attending a conference where he was talking about a bunch of open source projects that the company had recently initiated.
As one of the standard bearers for the new sharing economy – along with Uber, Lyft, HomeAway, TaskRabbit, and others – Airbnb is expected to share. Curtis spent a little extra time with The Next Platform to explain the philosophy behind Airbnb’s IT infrastructure.
Like many startups, Airbnb benefits from the experience of others even as it has come up with a service that people love and some companies – namely those that sell hotel rooms or book them – loathe. While renting out an apartment or a house when it is empty is certainly not a new idea, Airbnb has taken it all to a new level and has built the idea of trust – of the people you are renting from as well as the people you are renting to – into its system, which has no doubt been a catalyst that has propelled its business.
Airbnb was founded in 2008 in San Francisco, just as the Great Recession was getting momentum, and the idea behind the company was the same reason that people put their spare rooms or whole houses on the site for rental: co-founders Joe Gebbie and Brian Chesky had a loft in San Francisco and they could not afford to pay for it, so they turned it into a bed and breakfast and rented it out. Two years later, after much work, Airbnb closed its first round of funding for $7.2 million in November 2010 and hit the hockey stick curve of explosive growth. In June 2015, in its seventh round of funding, Airbnb raised $1.5 billion in venture funds, bringing its total haul to a stunning $2.3 billion and giving it valuation of over $25 billion. And it is not even public yet.
But here’s one of the secrets to that success: According to Curtis, 70 percent of the people who put space up for rent on Airbnb in New York City say they do so because if they didn’t, they would lose their apartments or homes – just like the situation that Airbnb’s founders were facing seven years ago. We reckon the same story is being told in other cities and for vacation homes in the country that are available for rent. The need to make money on properties is not the only reason why Airbnb has expanded to have over 1.2 million bookings in 40,000 cites (and rural areas, of course) in 190 countries worldwide, but the economics of the sharing economy play a big role in Airbnb’s popularity. So does creating experiences for people, who sometimes want more than a hotel room in the center of town where the WiFi is iffy. They want to live somewhere else for a while and see what that is like.
Learning From The Dot-Coms
Curtis cut his teeth in the dot-com era at the AltaVista search engine – the one that everyone used before Google came along, you remember. After a few years, Curtis was a software engineer at AOL, designing web crawling code, and spent nearly eight years at Yahoo in charge of its mail and messenger platforms and then did a few years at Facebook as director of engineering for its user growth and engagement teams. Since early 2013, Curtis has been the vice president of engineering at Airbnb.
When Curtis came to Airbnb, one of the things he did not have to cope with was a datacenter crammed with servers, storage, and networking. Given the business it is in and the time that it was founded – two years after Amazon Web Services launched – it is probably not a surprise that Airbnb does not own any of its own IT gear.

“We started entirely on AWS, and those companies that just missed the mark have hundreds or thousands of engineers managing their datacenters,” says Curtis. “The companies that launched after AWS got to sidestep a lot of that, which I really appreciate. I think it is important for our engineers to focus as much as possible on the things that are unique to our business, not running a ton of infrastructure.”
This was not possible before AWS had matured in 2008 or so, of course, and the largest hyperscalers and cloud builders – whose scale and scope utterly dwarf Airbnb – not only have their own infrastructure, but they design it, have it custom built, and store it in their own datacenters tuned to their gear. So there is not only a dividing line around 2008 for those who can live in the cloud or not, but also a dividing line – probably somewhere north of 100,000 servers – where it makes more sense to manage your own infrastructure and build those skills needed to do it better than a public cloud.
The infrastructure at Airbnb is not anywhere approaching that scale, but it is still large and growing fast. Curtis tells The Next Platform that Airbnb has around 5,000 EC2 instances running on AWS, most of them being reserved instances just to keep things simple. About 1,500 of those EC2 instances are deployed for the web-facing parts of its applications and the remaining 3,500 being used for various kinds of analytics and machine learning algorithms that drive the business. That ratio is interesting in and of itself, and it would not be surprising that as Airbnb grows, the amount of compute capacity dedicated to analytics and machine learning grows relative to the transaction processing portion of the business. The reason is simple: as more places become available on Airbnb and more people start using it, the challenge is not finding a place to rent, but finding the right place, one that satisfies both the renter and the host.
“Everything that we do in engineering is about creating great matches between people,” says Curtis. “Every traveler and every host is unique, and people have different preferences for what they want out of a travel experience. So a lot of the work that we do in engineering is about how do we match the right people together for a real world, offline experience. It is part of everything we do. Part of it is machine learning, part of it is search ranking, part of it is fraud detection and getting bad people off of the site and verifying people’s identity so they are who they say they are. Part of it is about the user interface and how we get explicit signals about your preferences. A lot of the technology that we do is around creating great matches.”
The trick is to use search engines and machine learning to bubble up the best options for both guest and host based on their preferences, which are either explicit in profiles or implicit in the history of transactions and searches on the Airbnb site. So, for example, say you want to go to Paris – the one in France, not Texas – for a few days a few weeks from now. Paris has about 40,000 listings on Airbnb, and maybe 10,000 of those are available. Based on your preferences, there might be something like 1,000 possible places for you to stay. It is just not possible to click through those 1,000 places, and the number remains large after you put on filters for various kinds of preferences – WiFi, no pets, a whole house not a room, and so forth. The idea that Airbnb is developing is to augment search with machine learning such that the five or ten best matches for both guests and hosts will pop up, speeding up the transaction time, which makes people happier and which also reduces frustration and loading on Airbnb’s systems.
“I intuitively believe that we are making the most of our engineers to push the business forward and doing it in a cost effective way on AWS. Part of that intuition is that I used to manage the Yahoo Mail engineering team a long time ago and we spent a huge amount of time on server and cost optimization and figuring out how to squeeze more out of the NetApp filers that we were running. I think about the percentage of time I spent on that versus the percentage of time I spent on making Yahoo Mail a better product, and it might have been 50-50. Maybe it should have been 5-95.”
That deep understanding of guests and hosts also drives a feature that Airbnb introduced about a year ago, called Instant Book, which as the name suggests allows for guests to book a stay instantly. But Curtis says that this requires a deep understanding of host preferences and guest behavior to do, it is not just a matter of running a credit card (which would be easy enough). About a year ago, when it started, about 40,000 Airbnb sites had Instant Book, and now it is at about 200,000 of the 1.2 million sites worldwide.
Like many companies, Airbnb is starting with some open source software but then heavily modifying and extending it to create its machine-learning enhanced search engine. “The core indexing technology that we use is Lucene, but we really only use the inverted text pieces,” Curtis explains. “All of the ranking and machine learning functions that we apply is based on our own code. As far as machine learning training goes, we train on CPUs right now. We have not encountered a computational limit on CPUs, but I know a lot of people are working on GPUs for that reason. We will probably get to that at some point.”
With its first experiment in machine learning, which Airbnb talked about earlier this year, the company’s data scientists juggled the stay preferences of both guests and hosts – some guests like short stays, others long ones; some hosts don’t mind last-minute bookings, others tolerate them and some hosts are more interested in high occupancy rates and others want to rent only occasionally – and drove the booking rate up by 4 percent. This may not seem like a lot, but it is significant.
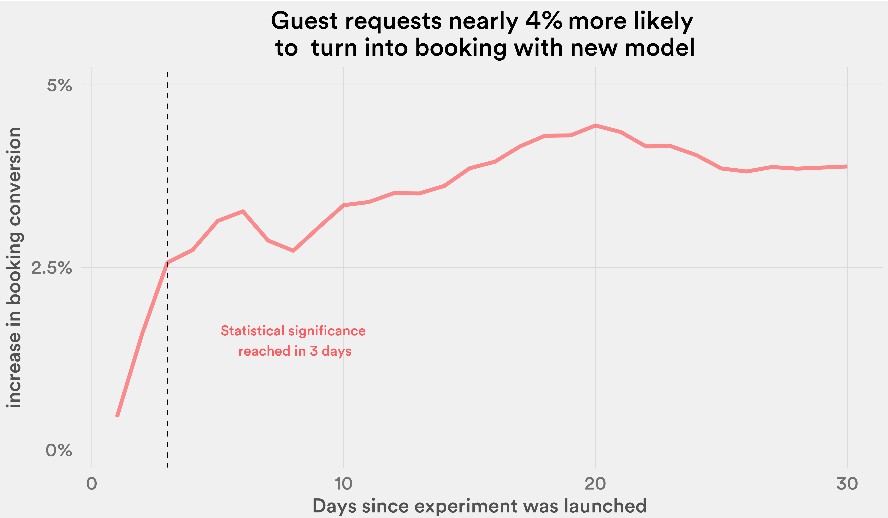
Machine learning algorithms are also behind the dynamic pricing feature of Airbnb, which walks the hosts of the world, creates neighborhoods, and helps set pricing and thereby drive up occupancy rates for places available on Airbnb. Curtis says that in early tests hosts that set their prices within 5 percent of the recommended rental rate that the machine learning algorithms provided were four times as likely to get a booking.
To make embedding machine learning into its applications easier, Airbnb created a tool called Aerosolve, which is available open source on GitHub, that plugs into the Apache Spark in-memory processing engine, which Airbnb runs as a standalone platform for its early experiments in machine learning. Aerosolve does a number of things, but an important one is to give data scientists a sense of what is actually going on inside of a machine learning algorithm that makes a recommendation for a guest or a rental price. This is the black box problem of machine learning, which we discussed earlier this week.
“A lot of times, you will be building a machine learning model and it is evaluating hundreds of variables and thousands of decision paths and it can be really hard to understand why it is giving the recommendations it does,” Curtis explains. “You think the recommendations are good. But you don’t know how good they are. Aerosolve gives developers a great way to iterate on a machine learning algorithm and understand what is happening under the covers and to also be able to apply human intuition as well to yield better results. I think Aerosolve is really promising and I am excited to see what people really do with it.”
The Hadoop Stack Evolves
The core data platform employed by Airbnb that drives the site and its analytics is Hadoop, of course, and everything is stored in the Hadoop Distributed File System. Airbnb used Amazon’s Elastic MapReduce service a while back and rolled its own Hadoop up on the EC2 compute instances on AWS, but in the past year has shifted to the enterprise-grade Hadoop from Cloudera as its platform. Curtis says that Airbnb had to build its own Hadoop clusters on EC2 because it outscaled the EMR service and equally importantly, it wanted to be able to provide mirrored Hadoop clusters and have more fine-grained control over the stack. Airbnb uses S3 to store images for the web site as well as backups of data in the Hadoop clusters and serves out of the US-East region of AWS with backups in the US-West and US-East regions. The company does have some relational databases for certain applications, and runs both Oracle and MySQL databases on the Amazon Relational Database Service, which Airbnb was a private beta tester for several years back.
“We actually had to do a big cluster migration at the end of last year to separate all data infrastructure into two separate mirrored clusters: one to run all of the business critical jobs – things that have to be run and done on time – and another one for ad hoc queries. When we had it all running on one cluster, people were so interested in learning from the data that the ad hoc queries could get in the way of some of the business critical work.”
On top of the HDFS files, Airbnb creates a data warehouse using Hive and also uses the Presto SQL query engine created by and open sourced by Facebook. And incidentally, MapReduce is not at all dead and is useful, says Curtis for long running queries that might have multiple chains and dependencies. Hive doesn’t support sub-queries like SQL does, and this programmatic approach using MapReduce gets a similar kind of result as a sub-query.
“Presto is pretty powerful, and it is SQL compliant to it makes it pretty easy to query the data and it is very fast,” says Curtis. “It is not as full-featured as Hadoop MapReduce or Hive – there are some things that you can’t do with it – but for day-to-day analysis it is very, very powerful, and mostly because it is very fast.”
Airbnb actually teaches classes in SQL to employees so everyone can learn to query the data warehouses it maintains, and it has also created a tool called Airpal to make it easier to design SQL queries and dispatch them to the Presto layer of the data warehouse. (This tool has also been open sourced.) Airpal was launched internally at Airbnb in the spring of 2014, and within the first year, over a third of all employees at the company had launched an SQL query against the data warehouse.
This spike in usage is precisely what happened inside of Google many years back when it launched its Dremel query tool internally, which has inspired the Apache Drill project as well as various other SQL layers on top of HDFS including Impala, HAWQ, and BigSQL. And similar spikes are no doubt driving up the number of Hadoop clusters in commercial settings.
“We actually had to do a big cluster migration at the end of last year to separate all data infrastructure into two separate mirrored clusters: one to run all of the business critical jobs – things that have to be run and done on time – and another one for ad hoc queries. When we had it all running on one cluster, people were so interested in learning from the data that the ad hoc queries could get in the way of some of the business critical work.”
The need to isolate OLTP work from ad hoc queries is what started the whole data warehousing movement and made Teradata famous two decades ago.
The two Hadoop clusters used by Airbnb today are kept in synch using Kafka for log collection and streaming data to both clusters at the same time. Airbnb has created its own workflow and extract-transform-load (ETL) tool called Airflow, which it has also opened up for others to use. Airflow has hooks into HDFS, Hive, Presto, S3, MySQL, and Postgres.
Among other things, Airflow takes in the streams of unstructured data from Airbnb’s site and adds structure to it to dump it into Hive tables atop HDFS. “There are so many weird ways that people cope with this problem, and for us, for a long time, it was a bunch of CRON jobs made up of bunches of scripts, and when you get to hundreds or thousands of those CRON jobs that are all semi-interdependent, things can break down pretty fast,” Curtis explains. “So Airflow provides a very clean, programmatic system to be able to go in and author, monitor, and debug an ETL system.”
To manage its clusters out on AWS, Airbnb uses Chef for configuration management and a bunch of homegrown tools. Interestingly, even though the Mesos cluster controller was commercialized by techies Twitter and Airbnb, who started Mesosphere, Airbnb is not using Mesos very much today.
Curtis explains: “We have it for a little sliver of our data infrastructure and a little bit of scheduling stuff but the majority of our infrastructure does not run on Mesos. The Mesos guys are doing interesting stuff, and when you look at Mesos or YARN, at some point, that is how it will all work. But it wasn’t quite there for us yet, particularly for our use cases, so we backed away a little bit.”
Airbnb was the first company to deploy Hadoop on top of Mesos, and Curtis says it had mixed results from that early experience – and is quick to point out that this was years ago and that Mesos has evolved considerably.
“The good part is that we were breaking new ground but the bad part is that Mesos, by its nature, is a layer of abstraction and it obscures some things from you,” Curtis continues. “It is designed to take a whole bunch of nodes and make it look like one node. What we found, particularly when we were running something novel on Mesos, was that this layer of abstraction was actually hiding some things that made it a little harder to debug. That doesn’t mean it could not be done and done well, but we didn’t necessarily start off on the right foot.”
The one thing that Airbnb has no desire to run its own datacenters, but every six months the IT team does an analysis to peg its compute and storage capacity and costs against what it would cost to bring it all in house. Curtis says that it would probably be on the order of 20 percent to 30 percent more expensive to operate its own datacenters than rent capacity on AWS – and admits that this is “bigtime speculation” because you don’t know all of the costs – particularly system admin and engineer costs – until you actually hire people and build a datacenter. And focusing on a datacenter might mean not focusing on the business.
“I intuitively believe that we are making the most of our engineers to push the business forward and doing it in a cost effective way on AWS,” says Curtis. “Part of that intuition is that I used to manage the Yahoo Mail engineering team a long time ago and we spent a huge amount of time on server and cost optimization and figuring out how to squeeze more out of the NetApp filers that we were running. I think about the percentage of time I spent on that versus the percentage of time I spent on making Yahoo Mail a better product, and it might have been 50-50. Maybe it should have been 5-95.”

Be the first to comment