
Part II is published: The Nitty Gritty of In-Memory Computing can be found here
Not really very long ago the terms In-Memory Computing (IMC) and In-Memory Database (IMDB) seemed to start showing up big time. Although the authors of so many pieces were using the term with authority, I’ll admit being annoyed that I often did not know what they meant. Were we dealing with some company’s new marketing buzzwords or was there some real basis for its use?
With all due respect to you folks and to my editors, I figured if I didn’t know some of you might not know either. So this article represents what I’ve learned in the meantime, not as a guru, but as a techie on a quest.
Even now, while doing the research for this article, I am finding that the term is way too broadly used. Some web sites read something like the following:
- Hey, computing is fast when all of your data is in memory. With In-Memory Computing, you can get all of that work done that used to take hours in a matter of minutes. And, sure, we’ll be glad to sell you more memory to make that happen. We’ll even gladly throw in your favorite buzzwords like Analytics or Big Data.
Or
- Your data is so big that you need scads of commodity systems just to get enough memory. Managing such a massive system takes real skill. Use our In-Memory Computing product and we’ll make this high-performance environment easy to use.
Tongue-in-cheek, sure, but I think I am finding that there is some real technical basis to both of these uses and many more. So this article’s purpose is to try to explain the underlying, often pre-existing concepts – many of them quite diverse – that seem to make up this notion of In-Memory Computing.
Some History First
Any time that some author starts a section titled Some History First, you automatically ought to know that the concepts being discussed are really not all that new. At some level, as you will be seeing, IMC is like a whole bunch of old but good ideas thrown into a single box. IMC as a whole, though, is relatively new and that resulting box does seem like more than the sum of its pieces.
For example, while researching for this article, I stumbled upon a paper from 1984; “Implementation Techniques for Main Memory Database Systems.“ Even at that time, it made the point that memory was becoming both cheaper and large enough that – the paper spoke in terms of many megabytes – an entire database could now fit in memory. They even went so far as to correctly observe that database indexes normally kept in memory should be organized differently than ones which are normally accessed from disk. We’ll discuss this point more later, but both points are part of the essence of IMC.
Even from my own background, if a customer was having a performance problem and we found that they were suffering from a high paging rate, we would often first ask whether they could adjust memory pool sizes upward to keep frequently accessed data in memory. That, too, is performance through in-memory computing.
Or consider customers wanting near millisecond transactions. The first question that gets asked is “How large is your database?” The essence of that question is nothing more than observing that you can’t suffer the latency of accessing something from disk if the desired transaction time is less than normal disk access time. The database must reside in memory. This, too, is in-memory computing.
At some level, IMC is old news. But, really, not too long ago, who would have thought it even reasonable to ask for sub-millisecond response times? Now it is getting asked, and often there is a need.
… and, of course, let’s take a look at historical costs [1][2]. Precisely accurate or not, these rather speak for themselves as to why In-Memory Computing has become increasingly popular.
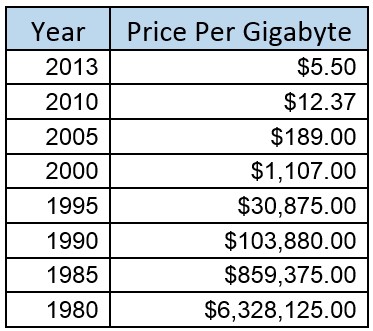
With pricing like this, the question then becomes one of how to physically package and programmatically address the amount of memory which seems to be increasingly in need. More on that later.
A Bit of Background To Get Started
Many of the papers/articles on IMC try to make the point that IMC has all of its data in memory and the alternative has all of its data on disk. OK, yes, I see the point, but, umm, no, not really.
Since you folks are avid The Next Platform readers, you already know the basic architecture of most computer systems. Just so we are all on the same page, I’ll again outline it here:
- One to N processor cores, on one to M chips,
- Each core with some amount of cache,
- The cache(s) fed from Dynamic RAM, typically some attached to each processor chip, and
- This processor complex is connected to IO-based devices, these representing much slower but persistent storage like hard disk or solid state drives.
For, well, like forever, processors have accessed data and program instructions from the DRAM, not directly from spinning disks. Sure, with the DRAM’s power off, the data need(ed) to reside out in some form of IO-based persistent storage. But once turned on and booted up, the OS pulls both data and program instructions into the DRAM where the processor requires them to reside.
The OSes and the likes of Database Managers have also known about the relative difference in access latencies between DRAM and disk for about as long. As a result, they have also had the time to develop some sophisticated algorithms for keeping the more frequently used data in the DRAM, no matter the DRAM’s relative size. Bottom line … Efforts to have some form of “In-Memory” have been a normal operating procedure.
Picture it like this. Suppose that you have arranged for a very sizeable amount of DRAM in your system. Today even sizes around a terabyte of DRAM per processor chip are reasonable. Still, suppose that your database is slightly larger. So let’s have most of that database be frequently accessed by – say – thousands of web users. This data gets brought into the DRAM as needed – again, because that’s where the processors need it to be – and it tends to stay there, because it is being soon enough (re)accessed. It’s “as needed”, yes, but the DB Managers are smart enough to concurrently kick off multiple disk accesses. Even so, the access patterns are such that the OS still needs to get some of the data from disk, but let’s say such disk accesses are infrequent enough for us to largely ignore this occasionally longer latency.
Is this In-Memory Computing? Well, it is a start, and you have had the opportunity for variations of this for quite a while.
It is also, though, clearly not the alternative called “accessing the data from disk”. What makes IMC IMC is a bit more subtle than that.
Let’s, next, move a step closer to IMC. One of the attributes being claimed as part of IMC is that the DRAM is large enough to be primed with the objects – for examples, DB tables and indexes – before any real work gets done. In our preceding paragraph, the data was loaded into memory as needed; often this meant randomly accessing blocks of data of various sizes throughout the disk subsystem. The notion of “priming” here suggests instead that we are going to kick off a large set of disk reads first and in parallel from many of the disk drives. The intent is to get that bit of waiting out of the way first. Good idea.
So compare those two cases, reading as needed – during processing – and read first – before processing. The latter does have its advantages, given that there was enough bandwidth available to feed the DRAM with such concurrent accesses. But later, once the needed data really is in memory, the performance results would seem to become similar. So, good idea, but IMC can’t seem to end there.
If It Ain’t 64, You’re On The Floor
Although typically unstated, it happens that when folks refer to In-Memory Computing, they are also talking about 64-bit addressing, and so 64-bit processors, 64-bit OSes, and database management systems and applications/environments supporting 64-bit addressing.
Articles and white papers will say that it is important to pull and have the data in memory, in DRAM. But what they don’t tell you is that the processor executing applications can’t access it if we stopped there.
Aside from the lowest level of an OS – or in virtualized systems, the system’s hypervisor – no code uses real/physical addressing to access memory. It follows that your application can not directly address or access physical memory; most code and most applications use some form of virtual addressing. So, yes, a database index or table or some such could be brought into the DRAM, but in order for your application to access it, that data needs to be first mapped under something that the programs can use, virtual addresses.
Why is this important? Let’s look at a 32-bit virtual address on a 32-bit system, something pretty much standard not too long ago. These 32 bits are only enough to address 4 GB (232) of data at any moment in time, far less than your hundreds of gigabytes or terabytes of DRAM. So suppose your database is – say – one terabyte in size. Because the processor can only access the data using a 32-bit virtual address, it means that only up to 4 GB of this one terabyte are concurrently accessible. If your program wants to access another portion, some data needs to be removed from the virtual address space and another newly needed portion needs to be mapped into it. The larger data may or may not happen to reside in physical memory, but unless it is mapped via such a virtual address, no application-level program can access it until it is. Perhaps obvious enough, this address mapping, remapping, and unmapping takes time, not hard disk latency time, but it’s frequent enough that the time really adds up.
Or consider your DBMS (Database Management System). There you are with this really huge database resource on disk, 64-bit processors, but a 32-bit DBMS. The DBMS is running a query on your behalf and needs to read and process some more records. To do so, given a DBMS Process’ 32-bit virtual address is already fully used, records currently in memory need to be removed from the address space – perhaps first also writing their state out to disk – more records are read into memory, mapped into the DBMS’ virtual address space, and then accessed. This is going on over and over, perhaps within the period of this single query. It works. It’s functional, it’s been done for years, but it takes measurable time and it consumes processor capacity while it is doing it.
So we’ve moved up to 64-bit systems and 64-bit OSes [3]. That would be enough to virtually address 16 Exbibytes; I make this out to be well over 16 mega-terabytes; certainly enough for your multi-terabyte database. Your terabyte database, tables, indexes, all of it, can be mapped under this 64-bit address and left there. A one-time expense.
For some processor architectures I have been using the term virtual rather generically. For example, the Power processor architecture [4, see Virtual Address Generation] defines the 64-bit address that your programs use as an effective address. This happens to be an address type scoped to each process, making it typically a Process-local address. The Power architecture goes on and defines a OS-global virtual address; although each Power processor implementation is free to implement something less, the Power architecture defines virtual addresses as being up to 78 bits in size. As part of the normal process of accessing memory, which has to be really fast, effective address segments are translated to virtual address segments, these in turn are translated to real address pages. An object being “in-memory” is mapped under both of these types of address (as well as in physical memory’s real address) and, of course, is also in the DRAM.
I am going to say more on it later, but I’ll quickly mention a related concept here. There is a well-respected business OS named IBM i (and previously, among other names, OS/400) for which the virtual address mapping is done at the time that the data objects are created, not at the time that it is “loaded”. It follows that its database tables are already persistently tied to a virtual address even when the data is on disk, and when the power is off, and so certainly when its data needs to be accessed by a processor. For much of its data, there is no such overhead associated with virtual address mapping; again, the address is provided at object creation time. As a result, physical memory – DRAM – in such a system can be thought of as essentially just a cache of the objects residing in slower persistent storage. At some level, then, this OS has been well on its way to supporting In-Memory Computing since its inception.
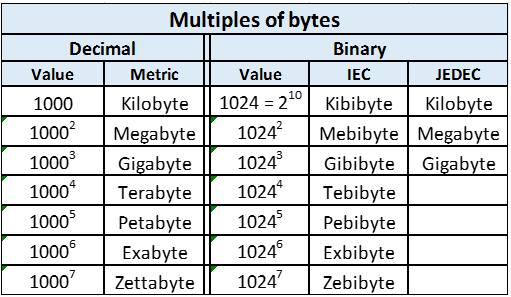
As an aside, we throw around these terms like terabyte around as though everybody uses them in normal conversation. To help get your head around just how large these system are becoming, consider this table here, effectively copied from Wikipedia:
Does It Stand Up To ACID?
Every computer science student knows down deep what it stands for and practically every user of a database system assumes it, perhaps without knowing it; it’s ACID … (Atomicity, Consistency, Isolation, Durability), the properties of database systems that ensure that database transactions are executed reliably. ACID also means that if the DRAM fails – losing the data due to, say, a simple power failure – data known to have changed remains available. On more traditional systems, that requirement typically means that either the changed data itself or descriptions of the changes have been recorded into files or persistent objects in IO-based persistent storage like HDDs or SSDs. The transactions wait until the writes there are complete. As a result, minimum transaction times are limited by the time it takes to do these writes. When the system comes back on-line, data perceived externally to have changed before the failure – for example, your customer was told that their on-line purchase is complete – will be available as expected afterward.
This article is at least partly about In-Memory Databases (IMDB). As of this writing, the memory that we are using for IMDB systems is not persistent; it is DRAM (Dynamic RAM), which loses its contents upon loss of power. Power fails, the data’s gone. At some level, this would seem contradictory; a database can’t seem to be In-Memory AND be assured to always be available. Fortunately, there are solutions, some which have existed for a while.
ACID’s Durability requirement does not say that the change itself must reside in persistent storage. ACID does say that a change perceived as made remains perceive-able that way later. The requirement is that the next time a transaction can look at the data – like after a system’s failure – enough has been restored or remains available for a subsequent transaction to see the change. A transparent switch-over to another system, one with the same data also in its memory (or even on disk), can meet this requirement.
Easy to say, of course, but durability via switching to another systems implies that the DB Manager is handling synchronous data replication to one or more other systems, some potentially far away. Such replication also implies that the DB manager is aware that the remote update was successful, before a transaction can be perceived as complete; this too can take time. Still, it’s all memory and intersystem communications can be rapid. Of course, we need to trust that the other system(s) won’t also fail – even due to potentially the same power failure – in the meantime. Still if power remains available long enough for the remote system(s) to quiesce and force DB changes to persistent storage, ACID is still being maintained.
I’ll add for completeness that one solution, one done for forever, is to maintain logs or journals of the changes on persistent storage. As long as we persistently record the change to be made within the bounds of a transaction, in the event of a failure, the log can be used to reproduce the changes. It might take a while to subsequently restore the data to its expected state, but it can be done. Observe, though, that this form of “In-Memory” requires writes to persistent storage within the bounds of a transaction; the transaction cannot be allowed to complete until it knows that the write of the log – a log on disk – is complete.
So, yes, this is an attribute of an In-Memory Database, but is that what you had as your mental image?
We should add that, as with most implementations supporting ACID, not only are log records written to persistent storage, periodically the changed records are subsequently written there as well. The intent of such asynchronous writes is to minimize the amount of time required to restore the database using log records after some sort of failure.
Still, a lot of what In-Memory computing is used for either has nothing at all to do with database transactions or it is not changing the database or objects. If an application does not change the key data in this system or a replicate system’s memory, does it matter if it fails and can recover quickly? It might even be that the database is a temporary copy of another; a system fails and a copy gets brought into that system’s memory again. Life is good, and it is fast, fast because what my system needs to work on fits into my system’s memory.
What Are Files
At some level, you don’t care how the data is organized, you just want to define what’s there and to have it available when you want it. You also give that data collection a name so that you can find and refer to it later. You certainly want it protected from those who you don’t want to see it. That’s about the essence of it, right? Some of you are correctly saying, well, I do know that I want some form of structure for that data so that I can work my way through it in some organized fashion. Yes, true, but that structure might be just an abstraction, a perceived organization rather than reality.
The point I’m leading to is that your data takes on a lot of different forms in reality, everything from the states of organized tiny magnetic domains on tracks of spinning disks, to little buckets of electronic charge, to current states in transistors, and many more. And it also depends on who’s looking at it; what you think of as a database table with rows and columns, each column being a set of names, or counts, or prices, is instead to a database manager an organized set of various types of data strings, integers, and floating-point number. Unless you are the file systems manager, the database table manager, and the disk subsystem manager, what you think is on disk, well, just isn’t. There a scads of ways to represent data and still maintain the abstraction that you have in mind.
So why that long lecture? Every component of a system is very familiar with the constraints and advantages of that component. As a result, there is a “right way” of doing things within that component. There is also, by the way, a lot of overhead – overhead as you perceive it – if doing it that “right way” is not what you need to have done. And as you work your way up and down the software stack, that overhead adds up, sometimes a lot.
So, getting back to In-Memory Computing – or rather the inverse of it here – suppose that a database or file manager is optimized to assume that the amount of memory is small compared the amount of data ultimately being accessed. For a database manager under that assumption, let’s add that we want it to execute a complex query. Knowing that it takes a while to get each individual item of data into memory and then work with it, the database manager might figure out ahead of time what data is needed, and kick off parallel reads from disk of all of that data. Of course, it had to first free up physical memory and address space for this incoming data. Given these constraints, given that the data really did need to be accessed from disk and memory space is at a premium, this process gets done very well, and has for years. But now change the memory trade-off rules; the memory is big. Now, is this database manager design the right approach?
Or let’s consider your abstraction of a relational database table; that table from your point of view may be a large set of rows of data organized as a set of columns of various types. It might even be organized along those lines in the way that it is laid out on disk. Under some set of constraints or under some long ago design, that might be the most efficient and general way to do it. But given it can all reside and stay in memory, does that remain the most efficient data organization?
As with most technology, the rules, the constraints, the trade-offs, all change.
If, instead, the memory and address space is large enough that much slower IO-based persistent storage is infrequently accessed, perhaps it is better to organize the same data in a way which is more efficient for accessing it from there. Instead, with IMC you have fast memory, and still faster processor cache, and processor-based addressing available to you. Shouldn’t the organization of the data change? And where and when should it be reorganized? Or if you know how you are typically accessing that data, are you better off having that data organized based on that knowledge or, instead, in some general way which works – umm – “acceptably” for all.
So, in part two of this story we will take a look at a few cases in point.

HP’s “The Machine”
Reading between your lines, I think I understand what you are getting at. I, too, am very interested in getting a deep dive on where they are heading with that system. The hints are intriguing; massive memory, a lot of it persistent and apparently close to the processors, and likely a lot of processors (with a different processor architecture?), along with claims of energy efficiency and better security. The recent announcement from Intel/Micron on their 3D XPoint persistent memory only adds to my interest. And then there is the related significant software architecture/design effort to enable the whole thing.
Still, patience seems prudent.
Also following the machine closely.
Note, HP have given up on memristors:
http://www.hpcwire.com/2015/06/11/hp-removes-memristors-from-its-machine-roadmap-until-further-notice/
Interesting to see what tech replaces that idea.