

Flash memory has proven to be the most disruptive storage technology of the past few years. It is significantly faster, with lower latencies than mechanical spinning disk drives. This supports an assumption that flash will soon be everywhere and supplant all other forms of persistent storage. However, while many experts think highly of flash, this assumption of datacenter ubiquity is a stretch.
Let’s review the performance and latency landscape at a high level. On one end of the spectrum, memory access on the server side is in the nanosecond (ns) range, with great consistency and predictability. At the opposite end, traditional mechanical storage spindles in storage arrays clock in at 4 to 10 milliseconds (ms) and, under loads with poor locality of reference, can be much higher. To put that in perspective, a single millisecond equals 1 million nanoseconds, so this latency difference covers an extremely wide range.
Flash is much faster than mechanical disks, but it also spans a notable latency variance primarily dependent on the bus access method in place; anywhere from 20 microseconds (μs) to more than 1 ms. However, these numbers are still nowhere near memory speeds and, as a result, some mobile and cloud architectures are now using memory as their primary tier for data processing. Remote memory shouldn’t be overlooked, as it is a critical building block for scale-out architectures. Remote access over the network is similarly speedy as flash, with today’s 10 Gb/sec Ethernet clocking in with a range of 4 to 20 μs, including protocol overhead. This low latency is critically important when discussing scale-out, cloud, and mobile application architectures.
Despite its benefits, flash has various quirks that need to be accounted for to achieve predictable and optimal results. Read versus write performance rates differ substantially, and, even within write operations, there is a lot of variability. Flash’s unpredictability is due to the way write operations are handled and the way various mitigation techniques are used to address them. Flash is divided into blocks and further divided into pages. While empty, pages can be written directly, but if not they can’t be rewritten directly – they need to be erased first. This is due to the electrical properties of flash; it can only write 0 bits, while its empty state is a 1. This means a page of content can’t simply be loaded to flash. The page of flash that will hold this new content must first be erased, setting it to all 1s and then subsequently resetting some of the bits to a 0.
Furthermore, erase granularity is at the block level, not the page level, which results in pages and blocks requiring multiple operations performed somewhat serially, such as moving the content of pages around to prepare to erase an entire block to perform a simple overwrite with new content. This process is called “write amplification,” and is a key contributing factor to writes being much slower than reads on a flash device and the variability.
Another factor that makes flash unpredictable is that it has a cycle lifetime – flash memory can only be erased and rewritten a limited number of times before it fails. To maximize the life of a flash-based device, software must perform “load-leveling” to make sure that all blocks and pages on the device are cycled through and written to equally. Many forms of traditional RAID are poorly suited for these flash mechanics. Fortunately, this level of complexity is usually handled by storage software, not application developers.
Another dimension of flash is the choice between consumer-grade, or multi-level cell (MLC) flash, versus enterprise-grade or single-level cell (SLC) flash. Enterprise-grade flash is more expensive, has better wear characteristics and can handle more input/output (I/O) in parallel than the less expensive consumer-grade flash. These attributes are directly related to the power consumption and form factor of each technology, and a variety of commercial solutions are available with each type.
Overlooked in many flash discussions is the access bus or interconnect, which can have a big impact on performance. A SAS-connected SSD access will average from a few hundred microseconds to more than one millisecond per I/O, while NVMe over PCI-Express flash will take 20 to 50 microseconds. Next-generation Memory Channel Storage flash via DIMM slots should be single digit microseconds, and looming on the horizon are DRAM/NVDIMM with memory-like access speeds in the tens of nanoseconds.
This brings up an important issue. To really leverage flash technology performance, and its likely evolution, one must move the flash closer to the application, meaning in the server and not on a storage array where it needs to communicate over a relatively slower network. This is one of my key takeaways about flash in the datacenter: flash is a critical driver of a storage architecture revolution, where centralized, dedicated storage arrays, including all-flash-arrays, will be replaced in the future by loosely coupled, distributed storage stacks co-located with the applications on the server and making judicious use of relatively inexpensive server resources.
Storage performance is not the only area in which demands are increasing dramatically; capacity requirements are exploding as well. It’s a world driven by big data and multimedia, a world that demands exponentially increasing storage requirements. Flash has quickly been decreasing in price, driven by the dual demands of enterprise and consumer devices. However, mechanical devices and cloud storage prices are decreasing as well and will continue to be orders of magnitude cheaper than flash for the foreseeable future (dollars per GB for flash, cents per GB for mechanical). Aggressive data deduplication and compression techniques are frequently cited as drivers for decreasing flash costs, but these software technologies are equally applicable to mechanical drives. Mechanical drives are also advancing with increasing density techniques including shingled/SMR drives. While flash is clearly a storage medium for latency-sensitive workloads, it’s not economical or optimal for all use cases, especially high-capacity uses, such as infrequently accessed data sets or multimedia files, or other data that is processed in big chunks.
Application architectures are also changing dramatically in the mobile/cloud world and have different demands of storage and persistence layers. For example:
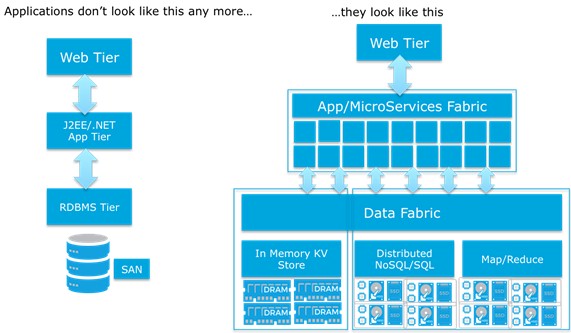
Storage persistence in this new era of application architecture needs to be optimized for both cost per GB (capacity) and cost per IOP (performance), while factoring bandwidth, scale, manageability and automation into the equation. These demands push storage persistence away from centralized, dedicated arrays and toward innovative distributed architectures.
Flash is an exciting component of storage architectures. It’s a major disruption, and it will be pervasive in many enterprise data center and cloud architectures moving forward. However, it is not a panacea for all persistence needs and its cost and complexity prevent it from being the only storage persistence option on the market. All-flash arrays will not be the only form factor, due to network interconnect latencies and scale-out application architectures. Server-side flash is already playing a major role as an important ingredient in hyperconverged and software-defined storage solutions, as well as decoupled architectures that make use of server-side memory and flash as a performance tier coupled to dense, capacity-oriented storage.
Scott Davis is the chief technology officer at Infinio, where he drives product and technology strategy, while also acting as a key public-facing company evangelist. Davis joined Infinio following seven years at VMware, where he was CTO for VMware’s End User Computing business unit.

HBM Can Keep Micron Out Of The Next Memory Bust Cycle
An interesting thought experiment to do in 2025 when looking at the financial results of just about any of the key compute, storage, and networking component and system suppliers is to imagine how any given company’s numbers would look if you backed out the AI portions of its business. In …
Hyperscalers Start Taking Pure Storage Flash For A Spin
Usually, innovation starts with the hyperscalers, HPC centers, and cloud builders of the world and spreads to the enterprise. But every once in a while, a technology establishes itself in large enterprises and the migrates upwards. This may be finally happening to Pure Storage, which was founded in 2009 and …
Putting More Flex Into Flash Storage Arrays
In a cloud-based, highly distributed, and data-centric world, flexibility in what a piece of hardware and its systems software can do, where it can run, and how it can be configured is a critical differentiator for picky enterprises. For several years, Pure Storage has been talking about flexibility and choice …
Be the first to comment