

Not all upstarts are founded in the tech industry, and not all of them within the last decade, either. The banking industry has its share of mighty titans, many of whom have been merged together in the wakes of financial crises, but there is still plenty of room for upstarts and innovation. Capital One is one of these upstarts.
Born two decades ago when information technology was changing fast, Capital One not only survived in the rough-and-tumble consumer credit card business, but has used that base to expand into commercial banking and consumer lending to become one of the largest banks in the United States. The company was founded on data analytics, although no one called it that at the time back in 1994, and today Capital One is embracing key new technologies, such as Hadoop analytics, Docker containers, and Mesos cluster management, to make it easier for its data scientists to deploy new algorithms for fine-tuning its lending practices.
Capital One was spun out of Signet Financial (which is now part of Wells Fargo) more than two decades ago, and had the twin benefits of being young and starting with a relatively clean slate. “Compared to other large banks and financial institutions, we don’t have as much baggage, if you will, as longer tenured institutions do when it comes to technology infrastructure,” George Brady, executive vice president of technology at the bank, tells The Next Platform. “We have a mainframe environment, for instance, but it is a relatively small mainframe footprint for running some aspects of our core commercial banking business. We predominantly do our processing on distributed platforms. We have been on a journey for the past seven years to hire much more engineering talent into the company and investing to move to much more towards microservices and open source and restful APIs.”
Brady has seen a lot of changes in the IT at financial institutions in his three decade career, having started out at Morgan Stanley, them moving to management roles at JP Morgan (before it merged with Chase Manhattan), ING, Deutsche Bank, Goldman Sachs, and Fidelity Investments, eventually landing his current position at Capital One in April 2014. He may be new to Capital One, but Brady knows a bit about its history of platform and application changes. Like many companies formed in the 1990s, Capital One was a big user of Unix systems from Sun Microsystems and IBM, and in the early 2000s it started shifting to X86 systems supporting Linux. This shift in platforms coincided with a desire to build more of its own applications rather than buy and tweak those made by banking application specialists.
This may seem counterintuitive in a world where application software companies try to convince the Global 2000 to focus only on their business and let them do the coding, but like hyperscale application providers out there on the Internet, Capital One has come to realize that software engineering talent is a key differentiator and that to attract such people, which creates new applications and maintains and extends existing ones, it has to be a much bigger participant in the open source community. (More on that in a moment.)
Brady is not at liberty to say how many servers Capital One has deployed in its datacenters – it has two in central Virginia near its McClean headquarters and another remote site in Chicago – but the infrastructure has tens of thousands of cores and nearly 30,000 virtual machines running across its X86 clusters.
As you can see, it takes a fair amount of iron to support Capital One’s 45,000 employees and 65 million customers. Capital One is the largest direct bank in the US (thanks to its $9 billion acquisition of ING Direct in 2011), and is the third largest independent auto loan provider in the country and, thanks to its $31.3 billion acquisition of the credit card business of HSBC that same year, it is the fourth largest credit card provider in the country. At $22.4 billion in revenues and with $210 billion in deposits and $306 billion in assets, Capital One is the seventh largest bank in America.
“I think to put too much emphasis on common standards at this early stage is quite a big challenge, and quite frankly, given the head start that AWS has, they sort of define the standard for the public cloud and it is everybody else’s to copy and interoperate with.”
Capital One uses Red Hat Enterprise Linux as its main operating system for supporting its banking applications, and has Microsoft Windows Server supporting core infrastructure such as Exchange Server, SharePoint Server, and SQL Server. Capital One uses VMware’s ESXi hypervisor to dice and slice its compute capacity on those Linux and Windows clusters.
The company has historically relied on tier one system makers (which Brady cannot name) for its Xeon-based server platforms, but like his prior employers Fidelity Investments and Goldman Sachs, Capital One has been actively involved with the Open Compute Project launched by Facebook and its relatively new Hadoop cluster, which weighs in at 2 PB and which is growing fast, is based on OCP-inspired servers, storage, and racks. Capital One uses the Cloudera Enterprise Hadoop distribution at the core of its new data analytics platform.
The company has “in the high hundreds” of applications that comprise its core banking systems, retail banking, auto loans, and other business lines and it is currently deploying most of these applications on its own infrastructure. Capital One uses Chef to automate the deployment of those applications in house and native features on the Amazon Web Services cloud to deploy and manage those applications that run in the cloud rather than on its own infrastructure. At the moment, a relatively small percentage of production applications at Capital One are running on AWS, but about half of non-production workloads such as test and development are deployed on the cloud.
And don’t get the wrong idea, thinking AWS will be getting Capital One’s business by default, or that the company thinks hybrid cloud means only picking one public cloud and marrying it to its own datacenters.
“We are a strong partner with Amazon, but we are equally interested in what Microsoft and Google have to offer,” says Brady, and he is not expecting common standards across these clouds any time soon. “I have maybe a unique view on this. Over time, this will sort itself out, but in the short term, if you look for greatest commonality, you are going to settle for the least set of features. So we are careful about where we are leveraging a unique capability of a product or provider. But we also don’t want to disadvantage what we are trying to do at scale, and given the fact that we are automating and making API calls and using certain constructs in one service such as Amazon Web Services or Google Cloud Platform, it should be easy enough to deconstruct and reconstruct in another service in the future while we work with a number of large institutions to drive more common standards over time. I think to put too much emphasis on common standards at this early stage is quite a big challenge, and quite frankly, given the head start that AWS has, they sort of define the standard for the public cloud and it is everybody else’s to copy and interoperate with.”
Building Microservices In A Software Factory
Capital One has around 1,000 physical branches located in New York, New Jersey, Texas, Louisiana, Maryland, Virginia, and Washington DC, which is not nearly as large as the physical presence of the big four banks in the states, but that direct banking business that Capital One got through the ING Direct deal “is The Next Platform for the future” as Brady put it and the way that the company is expanding to become a nationwide bank.
“More and more of the development we are doing is for homegrown applications,” says Brady. “Back in the early 2000s, it was really a mix of commercial software and built, and for the past seven years, there has been a pivot to more homegrown software where we think it makes sense and provides some differentiation.”
Brady says that Capital One is about a year into its efforts of converting towards more microservices-style software development, an effort it calls the Software Factory. The technology team measures in the thousands at Capital One, and the developers work in small teams that are going to be responsible for smaller and smaller chunks of code over time as they make this transition. Keeping track of all of these smaller chunks of code as it moves from development to test to production was a big hassle, and the bank could not find a tool that could let programmers and administrators see where all the code is at what stages in its agile programming pipeline.
To that end, Capital One created a dashboard called Hygieia to keep track of its code pipeline, which also happens to be the first piece of software that the bank is donating to the open source community. This dashboard integrates with many popular version control systems, including VersionOne, Jira, Subversion, Github, Hudson/Jenkins, Sonar, HP Fortify, Cucumber/Selenium and IBM Urbancode Deploy.
“Docker figures very prominently in our journey into microservices,” says Brady, echoing comments that we have heard from many customers over the past year and a half as Docker specifically and the idea of containerizing software generally has taken off.
“It is going to take time to get there,” Brady says when asked about the roadmap to move from virtualized monolithic apps to containerized microservices. “It will take many years, but it is inevitable because containers will be pervasive in everything we do. But we start from a base, and we started embracing VMware in the early 2000s. Docker is more easy to embrace in the public cloud right now, but we have the ability to deploy Docker in our own datacenters. But we are not trying to get rid of the hypervisor or getting VMware out of the equation in the foreseeable future. We are big supporters of Docker, but you have to look at where it is in terms of its evolution. I don’t know a single enterprise that would completely bet their future in 2015 on Docker. For instance, there are security enhancements that are needed, and we are working very closely with the Docker community to make sure that happens.”
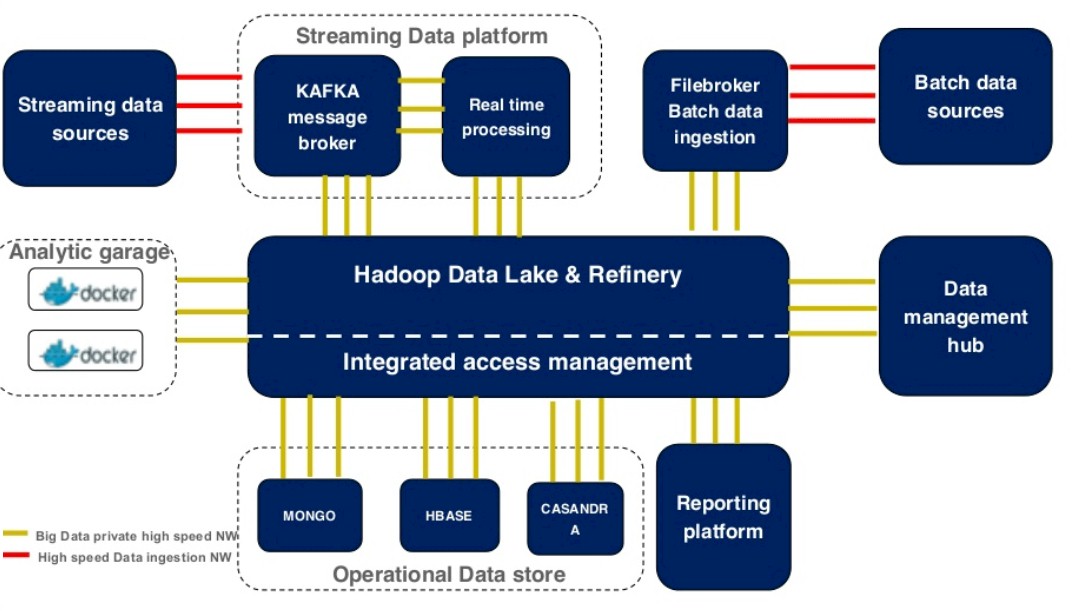
The microservices push using open source technologies meshes with the shift to open source for analytics at the bank. Data analytics at Capital One was built on what Brady refers to as “proprietary technologies” in the past, without being specific because Fortune 500 companies are often hesitant to talk specifics when it comes to suppliers. “We are focused on Hadoop and Spark and we are a couple of years into that journey,” says Brady.
The interplay of Docker containers and open source tools such as R and Mesos were demonstrated last month by Santosh Bardwaj, senior director of technology at Capital One, at the DockerCon 15 conference. Bardwaj showed off a system called the Analytic Garage, which is a system that is used by data scientists to automatically deploy containerized statistical analytics tools that can chew on data stored in that Hadoop-based data lake.
The analytics tool stack at Capital One has evolved fairly rapidly. It was initially created on a bare server cluster running Red Hat Enterprise Linux because, at the time, as Bardwaj put it, the bank “didn’t know anything about Docker.” Very quickly, users started installing multiple tools on the same physical platforms, and were impacting the stability and performance of the analytics jobs.

So Capital One took a second pass at the Analytic Garage, and the software engineers added some policies and other features to container groups, or cgroups, inside of the Linux kernel and adopted LXC Linux containers to isolate workloads. (This is akin to the kind of containerization that Google itself started developing a decade ago and was the initial basis of Docker containers.) But even with this improvement, Capital One had very powerful machines that were underutilized, and the other was that installing specific software stacks for data scientists was still being done by hand. So this is what Capital One cooked up to automate the packaging and provisioning of various analytical stacks for its data scientists:
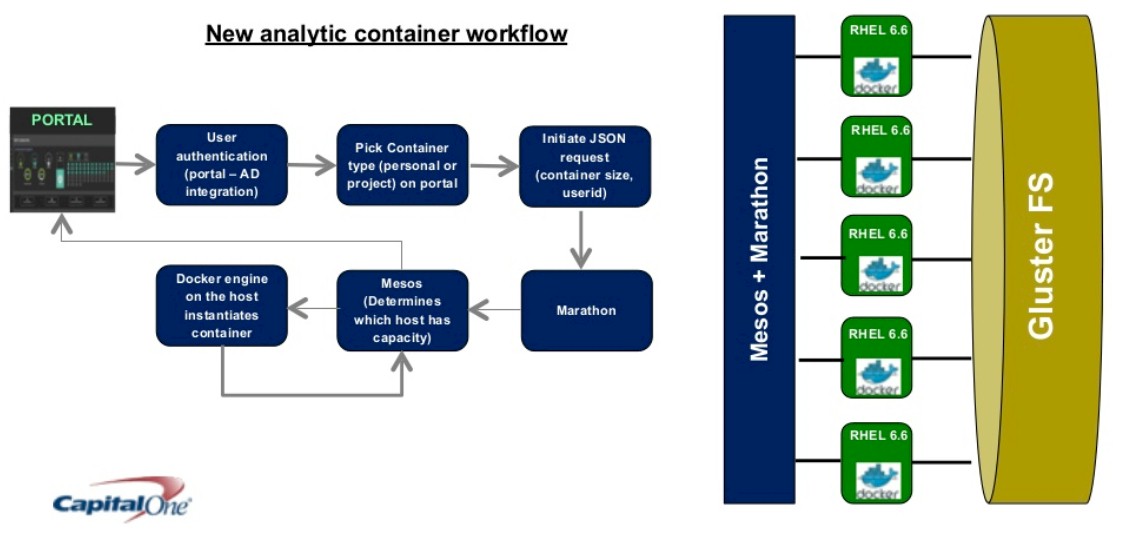
As you can see, the Analytic Garage runs on a Red Hat GlusterFS clustered file system that interfaces with servers that are running Red Hat’s Linux and Docker containers. The Docker containers are running atop the Marathon framework created by Mesosphere, the commercializer of the Mesos cluster management tool inspired by Google’s Borg cluster controller and perfected by software engineers at Airbnb and Twitter. By front-ending the analytics stack with Mesos, resource allocation can be automated across jobs as Docker containers can be used to restrict or grant resources for specific jobs on the Capital One clusters. The trick to making this all work well together is to have a high-speed network with lots of bandwidth between the Hadoop and Spark cluster nodes and the Analytic Garage, so it looks like the R and Python and other tools in the analytics sandbox are running locally on the data nodes in that Hadoop/Spark stack. Once the tool took off, Capital One created a self-service portal for the analytics tools and set everyone loose.
None of this was as smooth to integrate as it sounds, warns Bardwaj. Some of the software in its open source state is fragile (Capital One moved from open source Gluster to the supported version for this reason), and Docker is not fully supported in the Linux 2.X kernels, he adds. And networking for the containers was a big issue because the bank wanted to be able to manage this not just across multiple hosts machine, but across its datacenters. It took the company months to integrate these tools and get them working together, and the networking stack for Docker still needs work as far as Bardwaj is concerned.
Another interesting thing that Capital One did with containers was a bit counter-intuitive. It had 30 different analytics tools that it wanted to put at the disposal of its data scientists, and rather than putting them all into individual microservices containers, it created one macroservice container with all of the tools in it, ready to do. This cut down on the complexity of container management, even if it did make for fatter containers, and it did not adversely affect performance. “We are able to instantiate containers in seconds,” says Bardwaj.
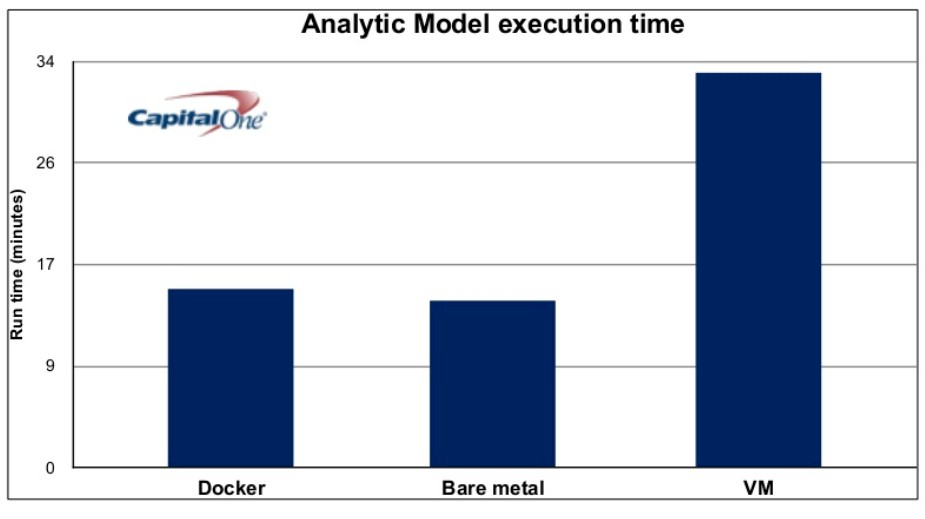
Performance is also a big issue in any virtualized environment, and as you can see from the chart above, on benchmarks for analytics tools running inside of Docker containers, the performance is close to bare metal, which you cannot say for the same tools running inside of a virtual machine. (This particular test is for a machine learning algorithm.) “This has given us the confidence to stress Docker even more, to run more intensive programs,” Bardwaj says.
Looking ahead, Capital One is looking at better ways to make use of its Hadoop environment, which is split into two halves in an active-active configuration across two of its datacenters. “Evaluation of analytics tools is just the first phase,” says Bardwaj. “Eventually, we want to be able to progress these things across different clusters in an active-active environment and do workload balancing, and this is where I am really looking forward to some enhancements in the networking space. I think that is one of the things that is stopping us right now. Hopefully that is an area that Docker will continue to invest in.”

Be the first to comment