

Hyperscale datacenters and supercomputing centers have some of the same limits when it comes to budgets, electricity consumption, cooling, and space, so it is not much of a surprise that HPC customers are taking a hard look at some of the custom server designs created for hyperscalers. Such is the case with the new PowerEdge C6320 server, which is inspired by hyperscaler customers and which has found a home at the San Diego Supercomputer Center as the compute node for its “Comet” petascale-class system.
The big server makers have been selling stripped-down rack servers and putting together pre-clustered systems for HPC shops for more than a decade, so targeting this fast-growing part of the market is by no means a new thing. But what is new, says Brian Payne, executive director of server solutions at Dell, is that some of the largest supercomputing centers are not just looking at HPC-tuned versions of commercial server product lines, but also at the kind of gear their hyperscale cousins are using as possible alternatives.
“We see a lot of growth potential in HPC,” says Payne. “And in fact, HPC customers are pushing the envelope in terms of the amount of power available at a rack and ways to adapt the cooling infrastructure to push more work though the systems. Pushing means faster time to results.”
That said, HPC shops have a bunch of different ways they can build their clusters and it is no surprise that the University of California decided two years ago when it was commissioning the Comet supercomputer to do an engagement with Dell’s Data Center Solutions custom server group, which accounts for over $1 billion a year in revenues for the company, as The Next Platform recently reported. But the DCS machines are not for everyone, and more importantly, as Tracy Davis, general manager of the DCS group explained, the custom engineering and manufacturing does not scale down efficiently and requires a certain amount of volume to make sense for both Dell and the customer.
The PowerEdge-C line was created to span that gap, making DCS-inspired machines at slightly higher volumes across a larger number of customers with somewhat more limited custom engineering. The plain vanilla PowerEdge machines are loaded up with all kinds of features, such as heavy duty baseboard management controllers and RAID disk controllers because the assumption in the enterprise is that every server needs to be kept running. With hyperscalers, data is kept in triplicates for durability and an application spans hundreds to thousands to tens of thousands of nodes and the assumption is that a node will be lost; application availability is done at the software layer, not in the hardware. HPC shops are somewhat in the middle. They have parallel workloads and they do a lot of checkpointing so that if there is a loss of a machine the data for a simulation is saved at that point and can resume.
The PowerEdge C6320 is the seventh generation of hyperscale machines to come out of DCS that put four whole Xeon server nodes, each with two processors, into a standard 2U server chassis. DCS was the first developer of such a machine, and Supermicro and a number of original design manufacturers (ODMs) like Quanta Cloud Technology have also adopted this form factor and had great success with it. Payne tells us that Dell has shipped hundreds of thousands of the four node-2U systems (including custom DCS gear and the semi-custom PowerEdge-C line) since their inception a few years back.
By the way, the PowerEdge C6320 does not offer the most CPU compute density in the Dell product lineup, so don’t get the wrong impression there. The PowerEdge FX2 enterprise chassis, which was announced last fall, can cram up to eight of its FC430 quarter-width server nodes, each with two Xeon E5 processors from Intel, into a 2U chassis. (More on this comparison in a moment.)

The PowerEdge C6320 sports the “Haswell” Xeon E5 v3 processors from Intel, and delivers twice the floating point performance compared to prior generation the PowerEdge C6220s, which were based on the “Ivy Bridge” Xeon E5 processors. (The speed bump on Linpack and other floating point work is due to the much-improved AVX2 instructions in the Haswell cores.) By moving to the Haswell chips, Dell can also put 50 percent more cores into an enclosure (a total of 18 cores per socket and up to 144 cores in a 2U enclosure). For memory, the system tops out at 512 GB of DDR4 main memory per node, or 2 TB across the chassis, and the enclosure offers up to 72 TB of local storage that is shared by those four nodes; the machine supports two dozen 2.5-inch drives or a dozen 3.5-inch drives. Based on the SPEC_Power thermal efficiency benchmark, the PowerEdge C6320 delivers 28 percent better performance per watt than the C6220 machine it replaces, and this is probably just as important to some customers as the raw core count or raw floating point oomph.
Interestingly, with the PowerEdge C6320 system, Dell is installing its iDRAC8 baseboard management controller into each of the nodes in the system, and while Payne says that he does not expect HPC shops to use all of the OpenManage functions in the controller, it is something that some HPC customers and most enterprise customers are interested in having. (Unlike many hyperscalers, who have created their own external system controllers and in many cases their own management protocols.) Payne says that some DCS engagements include the iDRAC BMC, so this is not as unusual as it sounds.
For those customers who are looking to use hybrid CPU-GPU architectures in HPC environments, Dell is pitching the combination of the C6320 server enclosure coupled to the existing C4130 enclosure, which pits two Haswell Xeon E5 processors and up to four accelerators of 300 watts or under in a 1U form factor. (Dell used to have an enclosure that had PCI-Express switching and that just housed GPUs, which then hooked back to the hyperscale machines.) With two Xeon E5-2690 v3 processors and four Nvidia Tesla K80 dual-GPU accelerators, the C4130 delivers 8.36 teraflops of raw double-precision floating point math. (Many customers would use a mix of C6320s and C4130s because they tend to not deploy GPUs on all of their nodes, and Payne says Dell just deployed a large size hybrid cluster from these two components at an oil and gas exploration company for its seismic processing and reservoir modeling.)
In addition to targeting financial services, oil and gas, and scientific simulation and modeling workloads with the C6320s, Dell is will also be using the system as the foundation of a future XC series of systems for running the hyperconverged server-storage software stack from Nutanix; this will be delivered in the second half of this year. Next month, the C6320 will also be the basis a new hyperconverged EVO:RAIL appliance running VMware’s latest vSphere server virtualization and vSAN virtual storage software that competes against Nutanix. Looking further ahead, Payne confirms to The Next Platform that Intel’s impending “Broadwell” Xeon E5 v4 processors will be available in the C6320, and we would guess that there might even be a few customers who are already using such a system, since hyperscalers and HPC customers tend to get moved to the front of the line.
That brings us back to the FC430 nodes in the PowerEdge FX2 modular system. The C6320 system can use the full-on 18-core Haswell Xeon E5 v3 processors, but the FX2 quarter-width FC430 node tops out at either one or two 14-core Haswell Xeon E5s. Rather than distributed disks across the front of the chassis and allowing them to be accessed in blocks, the FC430 nodes have two dedicated 1.8-inch drives. (If you want a front-access InfiniBand mezzanine card from Mellanox Technologies, then you lose one of the disk drives in each node.) The FC430 nodes have eight memory slots each, which is half that of the nodes on the C6320. So maxxed out, each FC430 node has 28 cores, 256 GB of memory, and two relatively tiny disks, and an FX2 enclosure stuffed with eight of these has 224 cores and 2 TB of main memory; the SSDs scale from 60 GB to 2 TB capacities, so a max configuration would have 32 TB of flash capacity (a little less than half the disk capacity in the C6220).
The PowerEdge C6320 will be available in July. The C6300 chassis plus four FC630 nodes using two Xeon E5-2603 processors (these have six cores running at 1.6 GHz and are the lowest SKUs in the Haswell Xeon E5 line), with 16 GB of memory, one 2.5-inch 7.2K RPM disk drive, and the iDRAC8 Express controller will cost roughly $16,600.
The interesting bit is that the price difference between the PowerEdge C6320 and the PowerEdge FX2 modular systems is not as large as you might expect. Here is how Payne broke down the differences for us by system size and intended workloads with real, rather than base, configurations:
- Comparing the PowerEdge FX2 with FC430s to PowerEdge C6320: Both configurations have eight nodes and 128 GB memory or less), and the PowerEdge FX2 with FC430 provides the best density (2U for the FX versus 4U for the C6320) and is about 5 percent to 10 percent lower cost on a per node basis. The variance in the range depends on the choices of hard drives, network controllers, and top of rack port costs.
- Comparing the PowerEdge FX2 with FC630s to the PowerEdge C6320: In this case, both configurations have four nodes with memory capacities between 128 GB and 256 GB. The PowerEdge C6320 is 5 percent to 10 percent less expensive. Again, the variance depends on the choice of network and storage.
- Comparing the PowerEdge FX2 with FC630s to the PowerEdge C6320 with fatter memory nodes: Both with four nodes per chassis and with memory capacities greater than 256 GB, the PowerEdge FX2 with FC630 is about 5 percent less expensive on a per node basis. Payne says Dell sees many customers running workloads such as database serving or raw virtualization pick more than 256 GB of main memory on a two-socket system, and they typically value the redundancy features also available in the FX2, too.
Knowing this, and knowing that the San Diego Supercomputing Center was going with four-node enclosures with modest memory configurations, you can see now why SDSC chose the PowerEdge C6320 instead of normal rack servers or even the FX2 modular machines.
Rick Wagner, the high performance computing systems manager at SDSC, gave us a walk through the design of the Comet supercomputer, why the center made the choices it did, and who the target users are for the machine. The latter item is probably the most important part. SDSC is funded through the National Science Foundation – specifically the Extreme Science and Engineering Discovery Environment program, or XSEDE – and Wagner says that mandate that the center got back in 2013 when Comet was funded with $21.6 million for hardware and operating funds was to get HPC into the hands of many more users and particularly those who have workloads that don’t scale as well as many might think. This is what Wagner calls the long tail of science.
“There are very few applications that run at the scale of Blue Waters or Kraken or Titan that can use the full capability of those systems,” Wagner says, referring to some of the biggest HPC iron deployed in the United States. Half of the applications run on NSF systems peak out at maybe 1,000 or 2,000 cores, which is somewhere around 64 to 128 nodes using midrange Xeon E5 processors that are less expensive than the top-bin parts with 18 cores.
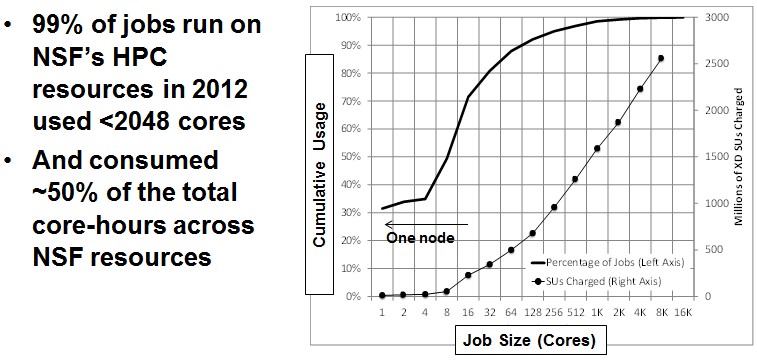
“The long tail represents two things,” Wagner explains. “One, the applications that don’t scale, and two, new communities with new users where the applications have not become parallelized – they are server codes or they might be running in multi-core mode on their laptops and they are moving them into the HPC realm. Instead of covering one or two science groups, we want to build a platform that can support thousands and thousands of users. The work doesn’t really scale with the number of jobs or the number of projects but rather with the number of users. This is how Amazon Web Services gets away with creating S3 without having to hold everyone’s hand – it is a long tail problem. And for us, we are concerned with building something that can support ten thousand users without having a hundred support staff.”
To accomplish this, SDSC is using gateways and portals to give users access to compute resources on Comet as well as sophisticated job scheduling software. But another thing that Comet is doing is offering very fast connectivity within a rack of PowerEdge machines and then limiting the size of a job, though a kind of virtual private cluster, to a rack of machines. Comet will have standard compute nodes as well as some that have fat memory and others that are accelerated by GPUs.
To be specific, Comet is comprised of 1,944 standard nodes that are based on the C6320 chassis. SDSC has chosen the twelve-core Haswell Xeon E5-2680 v3 chips, which run at 2.5 GHz and which deliver around 960 gigaflops of double-precision floating point oomph per node. These nodes are configured with 128 GB of memory and have 320 GB of flash SSDs for local scratch storage. The peak memory bandwidth on a node is 120 GB/sec and has been tested pushing the STREAM memory benchmark at 104 GB/sec. There are four large memory nodes that have four Xeon E5-4600 v3 sockets with 1.5 TB of memory in the Comet cluster. Another 36 nodes are based on the same two-socket Xeon E5 processors and memory, but have a pair of Nvidia Tesla K80 GPU accelerators on them.
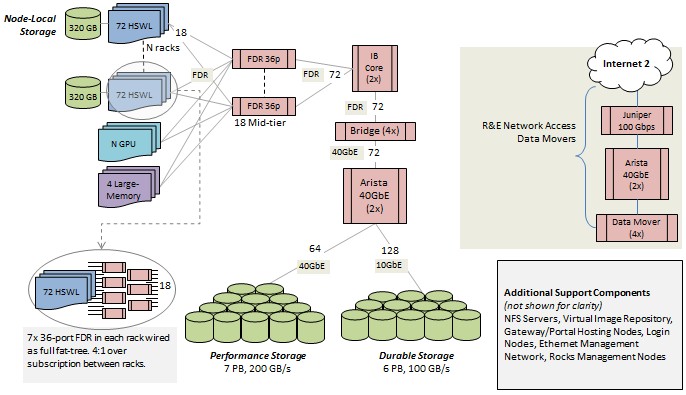
The compute portion of the cluster is linked together using 56 Gb/sec InfiniBand switching from Mellanox in a hybrid fat tree configuration and delivers around 2 petaflops of aggregate performance across its 46,656 Xeon cores plus a tiny bit from the GPUs. The machine has 7 PB of performance Lustre storage with 200 GB/sec of aggregate bandwidth and durable storage for keeping datasets around that weighs in at 6 PB and delivers 100 GB/sec of bandwidth, also based on Lustre. We will be looking deeper into the Comet system and how it works and will manage so many users.
The important thing to know is that back when the NSF awarded SDSC the funds to build Comet, it shopped the deal around to Dell, Hewlett-Packard, and Cray and Dell came in with a bid for a machine that looked something like a DCS box. At the last minute, as Comet was being prepared for manufacturing, Dell switched to the C6320 nodes, presumably making life a bit easier for both Dell and SDSC.


Dell Wants To Help You Build Your AI Factory
No surprises here: Reviewing first quarter earnings calls of S&P 500 companies, London-based analytics firm GlobalData found that generative AI was a key point of discussion among a growing number of the public companies. Business fundamentals analyst Misa Singh saying that “companies are looking at GenAI tools for better productivity, …

Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …
Fat Server Spending Props Up Slowing AI Servers At Dell
Just because you are the number one supplier of servers, storage, and PCs in the world does not mean the job of building those machines and making money is easy. It is not, and the financials of Dell Technologies shows just how tough it can be even when things are …
Be the first to comment