
When you have tackled some of the biggest database and storage problems in hyperscale computing, what do you do as an encore? In the case of Avinash Lakshman, the founder and CEO of stealthy storage startup Hedvig, you move out to the broader enterprise, where fast and scalable storage to serve all kinds of applications is still largely a pipedream.
Lakshman knows a thing or two about scaling up storage, although from a slightly different angle than you might be thinking. Google invented Bigtable as a database layer behind its search engine and advertising applications, and this system inspired online retailer Amazon to create Dynamo, its own homegrown NoSQL datastore that would allow the company to scale up its operations better than traditional relational databases could. Lakshman was one of the creators of the Dynamo database at Amazon, where he worked from 2004 through 2007, and this datastore has been underpinning Amazon’s shopping carts for nearly a decade. Amazon Web Services exposed this datastore as the DynamoDB service in January 2012, and Google just commercialized Bigtable as a service last month after it has been in production for about a decade. Lakshman moved to Facebook in 2007 and created a NoSQL datastore for the social network that was eventually open sourced as Cassandra, which is commercialized by DataStax and which is carving out a niche for itself in modern, distributed applications. He left Facebook in 2011 and kicked around ideas for his next big project.
“As my time at Facebook was winding down, I was trying to figure out what I wanted to build next, and I did not want to do anything that was just an extension of what I had done in the past,” Lakshman tells The Next Platform. “The problem set is not interesting enough, or big enough, for me to give it my attention to take a crack at it. I looked at what was happening on the cloud with virtualization, at server commoditization, at what was happening with flash in the datacenter. I felt like innovation had not really happened in the storage space for the last decade, and given the opportunity that I was privileged to have with the Dynamo and Cassandra projects, I thought some guiding principles could be put to good use to fundamentally disrupt the storage industry.”
Like everyone else, Hedvig is a proponent of what is called software-defined storage, which is about as amorphous a term as cloud computing and about as useful. What this generally means is taking a page out of the playbook of the hyperscalers and using commodity servers with cheap disks and flash as well as a slew of software to replace expensive disk arrays with various storage functions etched into chips and microcode. Lakshman is well aware that there are plenty of startups peddling “yet another storage solution” and that Hedvig is going to have to differentiate to rise above the cacophony.

One way to think of the impending Hedvig storage platform is a mashup of a distributed file system like Ceph, which in theory can deliver object, block, and file services to applications, and VMware’s Virtual Volumes, or VVols, which presents a virtual volume to virtual machines, pinning storage slices and their object, block, and file services directly to those virtual machines. (It is more complicated than that, and Hedvig is not using either Ceph or VVol technology in its stack.) The Hedvig system will support NFS file system access methods as well as iSCSI block access when it launches in the next month or so, and it will eventually support the SMB/CIFS protocol commonly used in Windows environments and often grafted onto Linux systems. (If enough customers ask for it, Hedvig will allow Fibre Channel links into its storage system, too.)
Hedvig is being a bit cagey about the secret sauces in its storage system ahead of its launch, but Lakshman is providing some hints about its architecture.
“This is more NFS catered to virtualized environments,” he explains.” In virtualized environments, when you use NFS, what you are actually dropping on your NFS endpoint is a VMDK that acts as the backend datastore for the VMs. The semantics change pretty significantly once you take that perspective, and that is why we are very good at what we do. We restricted our file-based capabilities to just virtual environments, and that opens up a world of possibilities.”
This is not an approach that the open source Ceph project, commercialized by Inktank and now controlled by Red Hat, took in Lakshman’s estimation.
“The comparison between Hedvig and Ceph, it depends on which side of the bed you wake up on,” Lakshman says with a laugh. “If you look at Ceph, it was fundamentally built to be, I guess, an object store, and on top of which block-based semantics were slapped. And then they tried to slap file-based semantics on top of it. And the lack of Ceph to be able to do their metadata management in a scalable fashion, I think, causes them to run into problems. We did not take that approach.”
The way to look at the underlying Hedvig system is to think of it more like a variant of the Elastic Block Storage, or EBS, service at Amazon Web Services – but a version of it on steroids because the Hedvig system can do block storage (commonly underpinning virtual machines and databases) as well as being compatible with the S3 object storage used on AWS and the Swift analog for the OpenStack cloud controller (commonly used to store media files and telemetry data from applications).
The way Hedvig and its investors – Redpoint Ventures, True Ventures, Atlantic Bridge, and Vertex Ventures, who have collectively kicked in $30.5 million to the startup in three rounds of funding in the past three years – see the market, enterprise and cloud storage are at several inflection points. The shift away from hardware-driven functions to software running on commodity platforms is one, and another is bringing together hyperconverged architectures with scale-out architectures. (Mashing up storage and servers is interesting and useful, but it also has to scale to be appropriate to cloud builders.) There is another trend towards replicating data across distributed storage platforms and moving away from high availability clusters or RAID arrays, but in addition to replication, the Hedvig Distributed Data Platform includes its own implementation of software-based RAID (much like PanFS from Panasas and GPFS from IBM do). The central feature of these distributed software RAID feature is that the bigger the cluster, the faster the repair when a drive fails, which is important in a world where disks are weighing in at 8 TB or 10 TB and flash is pushing up to 4 TB per unit.
Hedvig does not yet support the erasure coding techniques commonly used to protect object stores at hyperscale, like Facebook and Yahoo have talked about, but it is in the works, according to Lakshman.
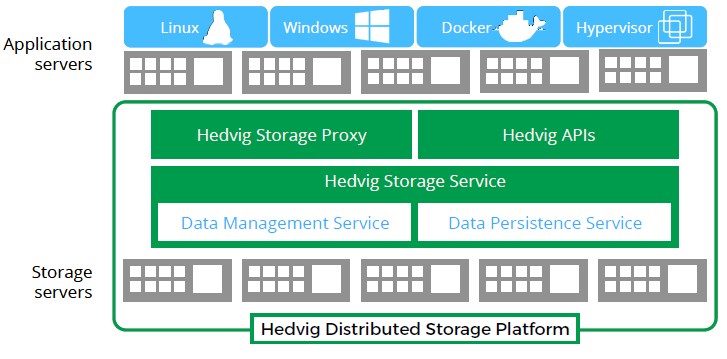
The Hedvig Distributed Storage Platform runs on commodity servers, pick your own poison. Hedvig is not, unlike many of the hyperconverged system vendors, starting out with an appliance model to restrict hardware choice and therefore simplify its support matrix. The data persistent service tracks the health of the underlying storage cluster, and the data management service manages the storage clustering, self-healing, and other functions of the setup, including disaster recovery between private clusters and those running on public clouds using the Hedvig software. The Hedvig storage proxy is what encapsulates the storage access in a VM or container and presents it as a block, file, or object service to a VM or container. Right now, Docker containers are supported by Hedvig, but others are likely as they gain in popularity, including LXC Linux containers and rkt from CoreOS. Hedvig has also come up with its own virtual disk format that provides the abstraction layer between VMs and containers and the storage system.
Here’s the flow chart of how the whole thing works:
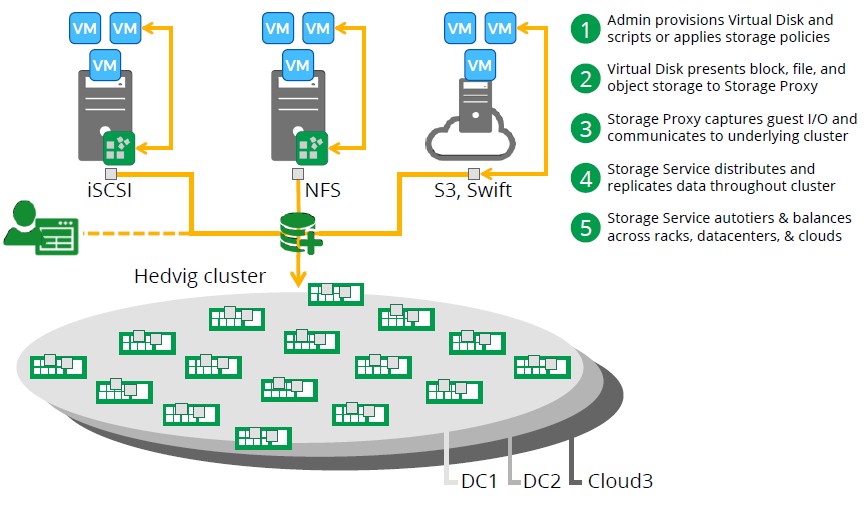
Hedvig is positioning its storage for three key workloads inside of the enterprise datacenter. The two are obvious, and that is as the backend storage for server virtualization clusters and private clouds (which is just a way of saying virtualized clusters with orchestration woven in). Hedvig also thinks that there will be a market for virtualized Hadoop data analytics clusters and virtualized NoSQL datastores in the enterprise, which kind of cuts against the grain of bare metal deployments of these wares in hyperscale settings.
It would be wrong to think of the Hedvig storage platform as a kind of distributed version of a traditional network-attached storage system. “Let me be perfectly clear. When I say we support NFS, we are not saying that we will be the next-generation of NetApp,” says Lakshman. “That is not what I am claiming. We do not want to be in the business of the management of small files. We are very good at managing a large number of large files.”
This is how Hedvig is bringing file system support to the stack – something that the Ceph project is still working on.
Whenever we hear large number of large files, we immediately think of traditional HPC workloads, and wonder how the Hedvig system might play. While Hedvig is a storage cluster, using Ethernet to link nodes together in a moderately coupled system, it is not running a clustered file system – and that is an important distinction.
“Think about something like HDFS,” Lakshman says as we led him down the HPC path a ways. “The fundamental stand they took something that would be very could at large, streaming writes and reads and at persisting large files. They do not want to be in the business of handling small files, and I presume that HPC environments fall into the same category. GPFS is a clustered file system, and when you go into the business of clustering a file system, it is a very hard problem to solve and thereby you run into scalability limitations. They don’t scale well beyond – I don’t know what the exact number is – beyond 32 or 64 nodes or whatever before the system would probably start becoming unusable. That is because of the clustering aspects of the file system. If you want to run a clustered file system on the Hedvig environment, we can scale, but we will provide you a block device on which you can format a clustered file system, and you will still be hit by the limitations of whatever the clustered file system has. But we can scale at our end – we don’t want to be in the business of solving the clustered file system problem.”
It is interesting to contemplate a Hedvig system with GPFS or Lustre partitions on it, just the same. But the focus is clearly on being the storage backend for virtual infrastructure, as you can see from the feature set in the Hedvig software stack:
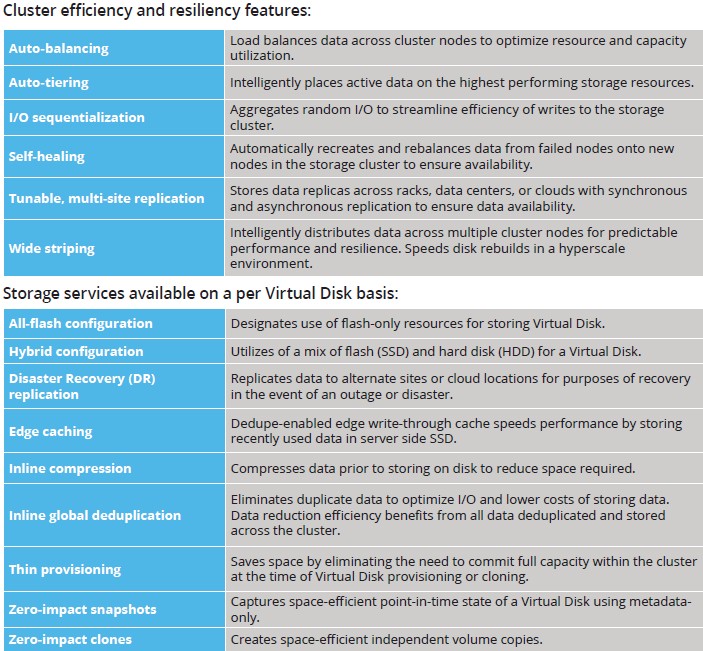
The base Hedvig system needs three nodes for data replication and resiliency purposes, and Lakshman says that it has been tested to scale at up to 1,000 nodes thus far. The software stack runs on CentOS Linux, and the basic building block for a storage cluster is a standard two-socket Xeon server, and the way the reference architectures are set up, the usable combined disk and flash capacity of the node is 24 TB. That means the Hedvig system can scale to at least 24 PB from the get-go. The software is not tied to the X86 architecture and when 64-bit ARM processors are ready for primetime, Hedvig will be able to support storage clusters based on ARM iron. The underlying iron does not include NVM-Express links to flash, which is just coming to market, but Lakshman says it will be easy enough to leverage when SSDs and PCI flash cards become more widely available. Hedvig is not snobby about disks and while customers will be able to create all-flash arrays, it is far more likely that they will use a mix of flash and disk with auto-tiering or in the case where a VM or container needs high I/O throughput, pinning of that VM or container to flash-only storage inside the array.
The Hedvig Distributed Storage Platform is in limited availability right now. Pricing is being worked out right now ahead of launch.
“At the stage that the company is in, the price is always going to be what the customer wants it to be,” Lakshman concedes with another laugh. “But from a pricing perspective, we are going to keep things very simple. We will have a perpetual license on a per-terabyte model, but we do have all of the building blocks in place for a subscription model. I am not really sure if we are ready for subscription-based models, so we will just have to see how this whole thing plays out. The one thing I can tell you is that we do believe that pricing should be as simple as the system is. We put a lot of effort into making this system very cloud friendly. When you go to AWS, you are not putting in tickets and waiting for someone to service your requests. We are bringing simplicity to our product, and you can literally provision storage from your iPhone.”

Meta Platforms Crafts Homegrown AI Inference Chip, AI Training Next
As we pointed out a year ago when some key silicon experts were hired from Intel and Broadcom to come work for Meta Platforms, the company formerly known as Facebook was always the most obvious place to do custom silicon. Of the largest eight Internet companies in the world, who …

The Growing Dependence Of VMware On AWS
Four years ago, VMware and Amazon Web Services announced a partnership in which VMware customers would be able to run their virtualized data center environments on AWS instances. That includes everything from vSphere cloud virtualization platform, vSAN software-defined storage and NSX software-defined networking (SDN) on AWS Nitro EC2 bare-metal instances. …

AWS Weathers The Coronavirus Storm
With much of the world in lockdown because of the coronavirus pandemic, it is not a surprise that much of the attention that is being paid to Amazon’s financial results for the first quarter of 2020 focused on its online retail operation, which is literally a lifeline to many in …
I tried Hedvig a few months ago.
My first thought was this is a good idea… my second thought is can I have it open source please?
I think looking at the Hedvig product there is an exposed gap in the market for someone to “Hortonworks” this type of product ie. do it all open source, preferably in the Apache Foundation so it’s all guaranteed to stay open source forever, at which point everybody would jump on it.