

Here is a question that all companies – except perhaps startups – wrestle with: Does it make sense to build a datacenter, house IT gear in a co-location facility, or just use raw compute, storage, and networking capacity on a public cloud? Answering that question is not easy, and that is why two engineers with expertise at calculating datacenter costs for Facebook and Google have released their model for calculating these costs into the wild.
Neither Amir Michael, who was a hardware engineer at Google and then a hardware and datacenter engineer at Facebook, nor Jimmy Clidaris, distinguished engineer for datacenter and platforms infrastructure at Google, have a vested interest in trying to push companies in any particular direction when it comes to trying to answer that basic question. (Michael left Facebook last year and is the founder of Coolan, which just came out of stealth mode in February and which is offering a server infrastructure analysis tool that brings machine learning to bear on system telemetry to help companies figure out what server components work best.) Both have taken the wild ride as their companies jumped to hyperscale, moving from co-location facilities and commercial servers to homegrown systems running in custom datacenters, but they know that will not be the answer for every company. The issue is more complex than one of scale, and that is why the two of them knocked together a total cost of ownership (TCO) model in a spreadsheet to help IT planners map out their course.
“Surprisingly, a lot of people are thinking about offboarding from the cloud and trying to figure out when the right time might be to do that,” Michael tells The Next Platform. “Other customers are pretty big in co-location and they are wondering if they should build their own datacenters. What we have found is that people do not have good models to understand the financials behind these decisions.”
To make such a decision as to build a datacenter, use co-los, or just employ clouds means juggling hundreds of variables, and this is precisely the kind of thing that people are apt to use their gut to make a decision on. That is a method, of course, but not very scientific. Michael says that there are some general rules of thumb to start with.
The first rule is scale, and generally speaking, the larger you are, the more it makes sense to have your own infrastructure. “Speaking very generally, if you are spending hundreds of millions of dollars a year on infrastructure, it makes sense for you to start doing it yourself,” says Michael, with the caveat that as soon as you start talking about this generally, there are cases where this does not hold true. “I purposefully did not provide a specific number for this because there is not one number.”
Also, certain industries have their own issues. Both financial services and supercomputing centers have very specific hardware needs to support their applications, which are often not available in the cloud, and financial services and healthcare companies are very sensitive to the location of their data and that can limit their use of public clouds.
“Surprisingly, a lot of people are thinking about offboarding from the cloud and trying to figure out when the right time might be to do that. Other customers are pretty big in co-location and they are wondering if they should build their own datacenters.”
Customers have to weigh other issues before they even start plugging numbers into an infrastructure and datacenter TCO model like the one Michael and Clidaris have created. Public clouds have elasticity of capacity unlike what most companies can afford to build for themselves, and that capacity is fairly instantly available. But, as we point out above, that capacity is also fairly general purpose and usually only available in precise configurations of compute, storage, and networking. The cloud is a general purpose platform, but only up to a certain point. (Companies like Virtustream, which just got acquired by EMC this week, are trying to change that.)
And that elasticity has its limits, too, such that most hyperscale companies cannot deploy on a public cloud, and even some large enterprises are getting to the point that they have to call up their cloud provider months ahead of time to ensure that the capacity they will need will be available when they need it. This is more of a classic hosting model than any of the public clouds want to talk about, but it is happening, says Michael. (Interestingly, the largest hyperscalers have turned around and created public clouds that will give them more elasticity for their own workloads as well as a customer base that subsidizes their IT research and development and helps cover the cost of their datacenters.) The point is, building your own infrastructure has its advantages even if you are not Google, Facebook, or Amazon, such as the continuity of the systems and the predictability of the supply of machinery that is tuned for specific applications.
The place that every company has to start is knowing their applications well. Without an assessment of the applications, how they are connected, and what resources they need to run with acceptable performance, a proper decision cannot be made about where to locate the infrastructure. Benchmarking on bare metal and virtualized servers has to be done and compared to capacity running in the cloud, and you can’t skimp on that. The TCO model that Michael and Clidaris have created can’t do this work, but once you have such data, you can input it into the model to figure out whether it makes sense to build a datacenter or rent co-lo capacity or use a cloud. (A version of the TCO model, which is a Google Docs spreadsheet, with its fields empty can be found at this link, and a version with some sample data in it can be found here.)
Michael provided The Next Platform for some use cases on how the datacenter TCO tool might be used. In one use case, information about power costs was pumped into the model to see what effect the cost of electricity has on datacenter costs. Hyperscalers are able to get low-cost power at 6 cents per kilowatt-hour in many cases, sometimes it is 10 cents per kilowatt-hour. So just for fun, Michael pumped in 50 cents per kilowatt hour (that’s about 2.5X the residential rate in New York City) to see what affect it has on datacenter costs.
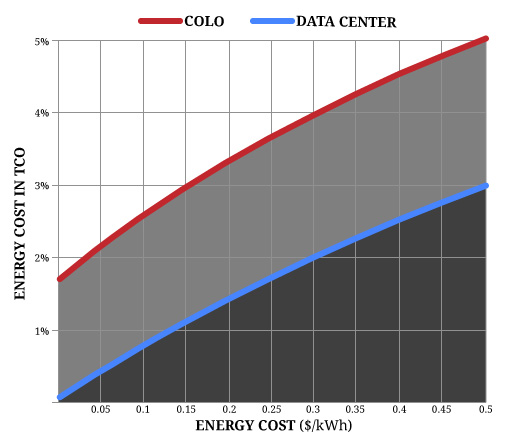
In the example above, Michael compared a co-lo and custom datacenter housing 4,000 compute nodes and 625 storage servers, which consumed about 1.5 megawatts of juice. Because datacenters are built for the long-haul, the costs in this scenario are reckoned over an 18-year horizon. The cost of energy is higher in the co-lo than in the datacenter, but in both scenarios, the cost of energy is small compared to other factors.
“We found that the change in overall datacenter costs was almost negligible, only raising the cost by one or two points for the cost of the overall infrastructure,” says Michael. “A big part of that decision is capacity, and a lot of places simply do not have tens of megawatts of excess. That is why Oregon, which has hydroelectric, and North Carolina, which has electrical infrastructure that used to support the furniture industry, are popular places to build datacenters.”
We would add that while the availability of electricity capacity is the reason that hyperscalers choose such locations, they certainly negotiate hard for long-term power contracts that give them among the lowest energy costs in the world and that savings does, in fact, drop straight to the bottom line. This is one of the many cost advantages of hyperscale.
In another example, Michael pumped in a number of compute and storage servers into the TCO model and scaled them both up to see what the model would predict about costs in a private datacenter, in a co-location facility, and a public cloud (presumably Amazon Web Services). Take a look:
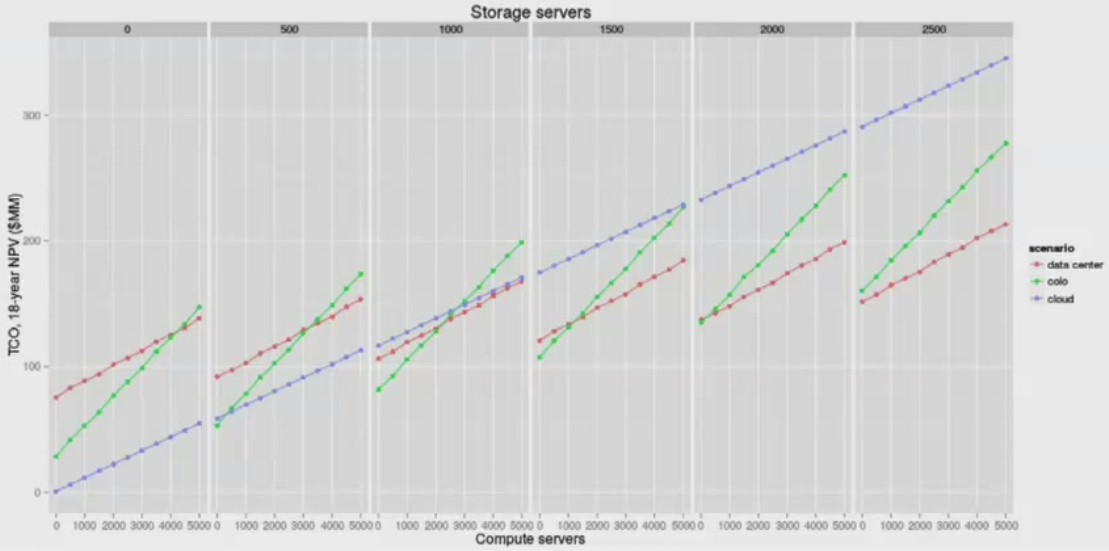
That chart is a bit rough to read, but here is what Michael says it means. If the workload you are running is heavily compute with very little storage, it is almost always cheaper to use the cloud to run that workload. (With the obvious caveats mentioned above.) The margins that AWS and other cloud providers are making on compute are, relatively speaking, pretty slim, and that is because compute is more of a commodity than storage. If you have a workload that is heavy on storage with very little compute, then somewhere around 500 storage servers it makes sense to think about owning your own gear and using a co-location facility and at 1,000 storage servers, it makes economic sense to build your own datacenter.
The reason is that storage is expensive, and not just the underlying capacity, but the hardware and software infrastructure that makes data durable and quickly accessible. If you can, like the hyperscalers, build your own storage hardware, file systems, access methods and formats (block, file, object), and data protection schemes, you can bring the cost of storage down even further. This is precisely why all of the hyperscalers have done this, and why more enterprises will follow suit. The future of storage looks a lot more like Ceph and Cinder or AWS S3 and EBS than it does a bunch of storage array appliances from EMC, NetApp, IBM, Dell, or Hewlett-Packard.

Be the first to comment