
Try as it may, Ethernet cannot kill InfiniBand. For the foreseeable future, the very high-end of the server, storage, and database cluster spaces will need a network interconnect that can deliver the same or better bandwidth at lower latency than can Ethernet gear. That latter bit is the important part, and it is what is driving InfiniBand forward to 100 Gb/sec speeds now and 200 Gb/sec speeds a few years hence.
Mellanox Technologies is already delivering 100 Gb/sec InfiniBand adapters and switches, known as the Enhanced Data Rate or EDR in the InfiniBand industry, and has been showing off the performance of its devices as they come to market. Mellanox is keen on getting to market ahead of rival Intel, which is gearing up to offer its 100 Gb/sec follow-ons to its True Scale InfiniBand switches and adapters in the second half of this year.
Thus far, Intel has been relatively quiet about its plans to enhance the InfiniBand switch and adapters that it bought from QLogic for $125 million in January 2012. Intel’s current 40 Gb/sec True Scale InfiniBand products are the foundation of the its Omni-Path interconnect, which will include Omni-Path ports in the same package as the future “Knights Landing” Xeon Phi massively parallel processor and the “Broadwell” Xeon E5-2600 processors. These CPUs will also ship in the second half of this year, roughly when the Omni-Path interconnect comes to market is what we expect. Intel is being careful not to literally call Omni-Path a variant of InfiniBand but is rather positioning it as a 100 Gb/sec upgrade from InfiniBand. We think there is a pretty good chance that Intel has taken some of the engineering and smarts that it got through its $140 acquisition of the Cray “Gemini” and “Aries” interconnects back in April 2012 and applied them to the future Omni-Path interconnect.
Intel has said that the Omni-Path software stack will offer binary compatibility with applications that run on True Scale gear today, and that it can put a 48-port Omni-Path switch in the field that will allow for a cluster to scale to 27,648 nodes, up from the 11,664 nodes that was possible with a 36-port True Scale switch. The 48 ports is interesting because it allows a kind of parity between server nodes and switch ports in a rack, so companies don’t have to buy two top-of-rackers and half populate one of them.
Recycling The Threads Of The Dream Of A Single Fabric
InfiniBand was supposed to solve all of the connectivity problems between servers and storage, becoming a universal interconnect for both peripherals and networks, but for a lot of complicated reasons, it did not work out that way. Any kind of radical change is hard to absorb in the IT market, and vendors and customers alike decided instead to go with an extended the PCI peripheral bus instead of InfiniBand. Because of its low latency, InfiniBand found a home in high performance computing, and has trickled down to other uses in the past fifteen years. At the same time, the Ethernet protocol has adapted and adopted some of the key features of InfiniBand, such as remote direct memory access (RDMA), to decrease the latency gap between the two different networking technologies. Ethernet has RDMA over Converged Ethernet, or RoCE, which may not be quite as fast as 56 Gb/sec or 100 Gb/sec InfiniBand, but even at 40 Gb/sec, it is good enough for a lot of customers.
You might think that InfiniBand would dominate the networking space because of its low latency advantages. Roughly half of the machines on the Top 500 supercomputer list use an InfiniBand network, which just goes to show you how widely adopted the technology is among the upper echelons of HPC. But it is hard to get conservative financial services firms to move away from Ethernet, and hyperscalers are similarly hesitant to adopt anything other than Ethernet. That is because Ethernet is widely known and in both of these cases has been highly tuned by big banks and hyperscalers.
That said, InfiniBand has seen some adoption in recent years outside of its traditional HPC arena, particularly for clustered databases and storage and for some cloud service providers and hyperscalers where latency is an issue. InfiniBand is at the heart of Oracle’s Exa line of engineered systems. Microsoft has deployed InfiniBand networks for Bing Maps and also has special analytics instances on its Azure public cloud that employ InfiniBand. PayPal has fraud detection systems using InfiniBand, and search engine giant Baidu has machine learning and voice recognition clusters that are lashed together using InfiniBand. But InfiniBand has to fight for every win. Microsoft is using Mellanox 40 Gb/sec Ethernet switches running RoCE in its Azure Storage service on its public cloud, which allows it to move data between storage servers with zero – yes, zero – network overhead on the CPUs inside those storage servers. In this case, 40 Gb/sec Ethernet plus RoCE was better (for whatever reason) than 56 Gb/sec InfiniBand with RDMA, or the prospect of 100 Gb/sec InfiniBand sometime this year.
The Need For Speed
This ever-increasing need higher bandwidth, lower latency, and higher message rates is why Mellanox is not only continuing to invest in InfiniBand, but is backing away from it converged SwitchX switch ASIC strategy. With the SwitchX chips, the ASICs are programmed with multiple personalities and can run either InfiniBand or Ethernet protocols. During the reign of its 40 Gb/sec and 56 Gb/sec products over the past several years, this is how Mellanox did it. The Switch-IB ASIC that the company announced last June does not support the Ethernet protocol, but it does add in InfiniBand routing functions and, more importantly, gets the port-to-port hop latency down where it needs to be for customers who require the lowest latency possible.
Clusters keep getting bigger and bigger and as the fabric stretches, the latencies increase on average across the fabric as nodes speak to each other to share the results of their crunching. Fabric expansion is, in part, one of the driving forces pushing Mellanox to constantly lower latency. In some cases, such as in storage clusters or in very low latency environments with modest node scale, low latency is its own driver, of course.
Here is the evolution of InfiniBand latencies for both the switches and the adapters over the past decade and a half:
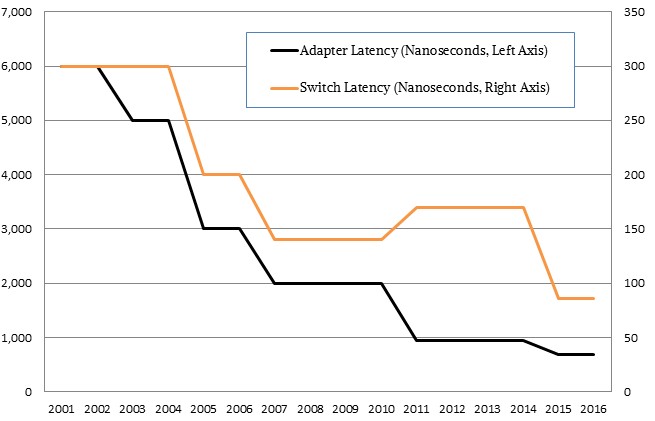
On the InfiniBand adapter side, the latencies have been coming down at a steady clip, but are arguably pushing up against some of the limits of physics. Way back when Single Data Rate (SDR) InfiniBand came out, the adapters had a latency of about 6 microseconds and it took a decade to push down below 1 microsecond into the nanosecond range. With the ConnectX-4 InfiniBand adapters that Mellanox is sampling during the first quarter for deliveries later this year, this EDR InfiniBand card has been tested to have a bi-directional throughput of 195 Gb/sec and an application latency of 610 nanoseconds. (This chart shows application-to-application latency for the adapters, which means the time it takes to communicate from the application through main memory and the CPU, out to the PCI-Express bus and then through the controller, over the InfiniBand cable, and in through the adapter, PCI Express bus, CPU and memory stack in another node in the cluster.)
Mellanox has been boosting the message rates over time for its adapters as well. The SDR adapters from 2001 could handle 1 million messages per second, and were boosted to 2 million messages per second a few years later. With DDR InfiniBand in 2005, the message rates were in the vicinity of 5 million messages per second for the server adapters, and doubled up to around 10 million with QDR InfiniBand in 2008. With FDR InfiniBand in 2011, the message rate went up by a factor of ten to 100 million messages per second, and the new ConnectX-4 adapters that are sampling now have been able to push 149.5 million messages per second.
On the switch front, SDR InfiniBand switches back in 2001 were delivering port-to-port hop latencies of around 300 nanoseconds, Gilad Shainer, vice president of marketing at Mellanox, tells The Next Platform, and with the latest Switch-IB ASICs in its 36-port SB7700 and SB7790 switches, it can get the latency as low as 86 nanoseconds. Officially, these switches are rated at 130 nanoseconds for a port-to-port hop, and the switch has 7.2 Tb/sec of aggregate switching bandwidth.
As you can see from the chart above, while Mellanox was able to converge its switch ASICs for InfiniBand and Ethernet with its prior FDR generation, that convergence actually caused the port-to-port latencies to rise. That is because Ethernet has to support more protocols and has heavier management, which added to latency for both protocols, oddly enough. This Ethernet-InfiniBand convergence is something that Mellanox could not do again with the EDR generation of InfiniBand switches, not with Intel expected to come on strong with Omni-Path later this year and not with some pretty big supercomputing deals a few years out hanging in the balance. (Mellanox will eventually put 100 Gb/sec Ethernet ASICs and adapters into the field, by the way. It is not giving up on expanding into the Ethernet space at all.)
“Many systems that use ‘Haswell’ Xeon E5 processors now and ‘Broadwell’ Xeon E5s in the future will use EDR InfiniBand. EDR allows companies to do more, not just because of the bandwidth and lower latency, but because of the higher message rates and application acceleration.”
One interesting point about performance. Shainer says that during the FDR InfiniBand generation Mellanox offered two different flavors of server adapters, the generic ConnectX-3 and the InfiniBand-specific Connect-IB. They both had the same bandwidth and latency, but the Connect-IB adapters offered between 20 percent and 50 percent more performance on applications running in the datacenter, thanks in part to the skinnier InfiniBand protocol and various offload engines and accelerators in the cards. Storage cluster and database cluster design wins for any InfiniBand technology stay in the field longer than the two-year upgrade cycle for supercomputers.
The ramp for 100 Gb/sec InfiniBand is just getting started, but it has a very proscribed run. “We are still selling FDR InfiniBand, but we have already said that we plan to have 200 Gb/sec InfiniBand out in the 2017 timeframe,” Shainer tells The Next Platform. (Indeed, The Next Platform found out about the OpenPower roadmap for the HPC market that shows the timing for the IBM Power processors, Nvidia Tesla GPU accelerators, and Mellanox switch and adapter technology over the next several years.) This High Data Rate, or HDR, InfiniBand stack is expected in 2017, and it would not be at all surprising to see a bunch of the supercomputers being built for the US Department of Energy using Power processors, Nvidia accelerators, and Mellanox interconnects shift from the EDR in their contracts to HDR if it is available on time.
In the meantime, it will take four or five quarters from the time that EDR switches and adapters are shipping for EDR products to represent more than half of sales at Mellanox for its switches and adapters, if history is any guide. The Minnesota Supercomputing Institute is the first customer to deploy an end-to-end EDR setup from Mellanox on a cluster, and Shainer says that he expects that several systems in the June 2015 Top 500 supercomputer list will sport EDR interconnects.
“Many systems that use ‘Haswell’ Xeon E5 processors now and ‘Broadwell’ Xeon E5s in the future will use EDR InfiniBand,” he explains. “EDR allows companies to do more, not just because of the bandwidth and lower latency, but because of the higher message rates and application acceleration.”
But EDR is not just for those buying new systems. Shainer says that based on early benchmark tests, depending of course on the nature of the cluster and its applications, the shift from FDR to EDR on a cluster, without changing any systems at all, is expected to yield somewhere between 15 percent and 50 percent performance improvements.
“You always go with the fastest switch,” says Shainer. In the case of EDR switches, his advice is to do 2:1 oversubscription, and then customers can still get 50 Gb/sec to the server nodes that are equipped with FDR adapters but still benefit from the lower latency and higher message rates of the EDR switch. Then, when they are ready to change servers and adapters, they can go back to 1:1 subscription and push 100 Gb/sec to the servers and not have to change switches. They will have to buy the other half of the switches they need to support all their server ports, of course. Or buy twice as many switches and half populate them. In any event, this is why Mellanox releases the switch ahead of the adapters, in fact.


For HPC Cloud, The Underlying Hardware Will Always Matter
Decades of cloud collaborations and optimizations have brought solid performance and cost efficiencies to cloud. Those who require high performance computing (HPC) resources tend to set their own rules when it comes to systems. Highly tuned for blazing fast computation and communication with software stacks optimized to match, these users …
Defying Supply Constraints, Nvidia Turns In Its Best Quarter Ever
To one way of thinking about it, this is the best of times among the worst of times for Nvidia. Despite a global pandemic that has caused disruption in IT operations as well as spending among enterprises large and small and that has disrupted supply chains all over the IT …

AI At The Edge Is Different From AI In The Datacenter
Today’s pace of business requires companies to find faster ways to serve customers, gather actionable insights, increase operational efficiency, and reduce costs. Edge-to-cloud solutions running AI workloads at the edge help address this demand. Placing compute power at the network edge, close to the data creation point, makes a vital …
Mellanox Ethernet switches and cards have 56GbE mode (and now it’s apparently a free upgrade for switches and cable price difference between 40GbE and 56GbE is trivial – so it’s almost free) which should give Ethernet performance much closer to (or possibly even faster than) FDR Infiniband – but somehow it’s not mentioned in your very detailed article.
For example, is (and why) Microsoft running it’s Azure cloud storage at 40GbE rather than 56GbE since it’s already using Mellanox switches?
I was aware of that mode to golden screwdriver the 40GE up to 56GE. It could be that Microsoft is not buying all of its 40GE switches from Mellanox, or it didn’t want to pay the upgrade fee.
Wow! An excellent article. You do a good job of not only educating the less informed but also provides good raw meat for those of us that have been riding the IB train for over a decade. My only suggestion is as the anticipated drive toward clustered ARM64 servers becomes a reality, it might also be useful to start to keep an eye on RapidIO.
Great article … it’s funny how HPC ‘gets it’ … while the rest of the computing world is satisfied with ‘good enough’. As fibre cables are being dropped into both oceans it’s obvious dissemination is an ‘issue’ and large data sets enhance the challenge. Suggest checking out Obsidian Strategics’s Longbow, capable of extending InfiniBand on a global scale. The future of Ethernet as ‘the acceptable standard’ … hmmm.
An excellent article on interconnect