
Intel’s forthcoming “Knights Landing” Xeon Phi processor is certainly an impressive beast, as The Next Platform revealed earlier this week. It has many more cores and vector units, and much more memory bandwidth, than a standard Xeon processor, and it should provide a significant performance density advantage compared to even Xeon processors in the future “Broadwell” and “Skylake” generations. But who, outside of the major national supercomputing labs and hyperscale giants that have thus far done most of the accelerated computing in the world, is going to use Knights Landing for production work?
The honest answer is that no one knows for sure. But the Knights Landing chip has technical attributes and support from Intel and the software community that are going to be attractive to customers for a lot of workloads outside of traditional HPC. And provided that Intel has prices (and therefore profit margins) that are commensurate with the performance of both the Xeon and Xeon Phi lines, there is no reason to believe the company will care one whit if a customer chooses one or the other style – or both. This is precisely the attitude that Intel took with Atom-based server chips, and there is every reason to believe that the future Xeon Phi will find work in the datacenter.
MIC Grows Up, Gets A Socket Of Its Own
Everyone knew from the beginning that the original “Knights Ferry” Many-Integrate Core (MIC) coprocessor and its follow-on “Knights Corner” coprocessor, which Intel is currently selling, were a bit of a science project. (Knights Ferry in particular had only 32 cores and could do only single precision floating point math.) By the way, there is absolutely nothing wrong with experimentation, and in fact this is how the IT industry is supposed to work. Companies should develop new architectures, finding big organizations to take a risk and start porting their code to the machines to see how those architectures work in the real world. This is how the largest HPC organizations work, the hyperscalers work, and the largest enterprises work. The Knights Landing chip that will be launched later this year using Intel’s 14 nanometer processes is the one Knights chip that customers no doubt would have liked to have years ago, and the “Knights Hill” variant that follows it will shrink the processes to 10 nanometers and add more features to boost performance even further.
Intel has not said when Knights Landing will launch, but The Next Platform has suggested to Intel that if it wants to make a point that Knights Landing has applicability well beyond traditional HPC, then launching it at the ISC 2015 event in July or the SC15 event in November is not necessarily the way to make that point. Intel’s launch plan is unclear, but Hugo Saleh, director of marketing and industry development for the Technical Computing Group at the chip maker, tells us that well before that launch date bunches of Knights Landing chips will ship to early access customers, much as Intel has done with prior Xeon E5 launches.
“This allows us to be a little more accessible to other parallel applications, even beyond HPC. Once we have silicon out in the market, we will see.” – Avinash Sodani, Knights Landing chief architect
The Knights Landing Xeon Phi chip will have a number of breakthrough technologies, which we discussed in our review of the processor and its architecture. The chip will have somewhere north of 60 cores and have four threads per core, with decent sized L1 caches in its heavily modified “Silvermont” Atom core plus a 1 MB L2 cache shared by core pairs and four vector math units across those core pairs. The Knights Landing cores will have three times the integer performance of the prior modified Pentium 54C cores used in the Knights Corner, which is important for a chip claiming to be a true server processor, as Intel most certainly is. But equally importantly, Knights Landing will pack more than 3 teraflops of double precision and more than 6 teraflops at single precision of floating point math performance into a single socket, and it will do so with 16 GB of what Intel calls high bandwidth memory and near memory hooked right into the 2D mesh that lashes the cores to each other and to the DDR4 memory controllers that link to so-called far memory. That near memory will deliver more than 400 GB/sec of aggregate bandwidth, coupled with around 90 GB/sec of bandwidth out to the DDR4 memory. What this means is that Knights Landing will be able to chew up and spit out any datasets that fit into a 16 GB space, and it will be able to also handle jobs that are as large as 400 GB in size, thanks to the DDR4 memory, without going to a flash or disk device.
One variant of the Knights Landing chip will also have integrated Omni-Path networking ports, and it is our guess that Intel will be providing two ports because many supercomputers have dual-rail networks. Intel has not said much about Omni-Path yet (and if you are confused about the name, it used to be called Omni-Scale for a while), but we know it uses a 100 Gb/sec protocol that is a follow-on to Intel’s QDR InfiniBand and that may or may not borrow technologies from the “Aries” interconnect developed by Cray for its XC30 and XC40 systems and acquired by Intel a few years back. The important thing is this: Knights Landing is for all intents and purposes a baby supercomputer on a chip, with its own MCDRAM burst buffer on the chip package along with very fast and presumably low latency networking also built into the chip. A variant of Knights Landing will be available without this Omni-Path networking, and another will come as a PCI-Express 3.0 coprocessor card.
Up until now, the PCI-Express 2.0 interface with the Knights Corner coprocessor has been something of a bottleneck, but with Knights Landing as a full-on processor or a coprocessor with PCI-Express 3.0 links, those bottlenecks are largely removed. And those facts, coupled with the tripling of performance over Knights Corner, should expand the market for Xeon Phi chips considerably.
“We have very high expectations for Knights Landing,” says Saleh. “There are many applications, and some are outside of the HPC realm, that can take advantage of the features on this die. Machine learning is one example that folks are taking a look at.” There will be other workloads in the financial services, life sciences, oil and gas, and pharmaceutical sectors that will see some uptake on Knights Landing, too.
Investing For The Long Haul
To get customers to adopt its Xeon Phi chips as true processors at the heart of massively parallel clusters, Intel had to do a few things.
The first thing it needed do is what it has hinted it would do almost from the beginning, and that is to make the Xeon Phi a full-fledge processor in its own right with its own socket. Intel also had to provide a roadmap that showed the Knights family of chip had some depth, which it did last November at the SC14 supercomputing conference in New Orleans.

Intel disclosed last fall that it had over 50 system makers committed to adding Knights Landing Xeon Phi chips, in one form or another, to their new or existing systems.
In some cases, companies will be using the raw processor and clustering nodes with Ethernet or InfiniBand, in others they will be using the integrated Omni-Path networking, and in still others they will be using the coprocessor variant and plugging it into multiple systems. (It is technically possible to plug a Knights Landing coprocessor into a Knights Landing processor, which has its own PCI-Express 3.0 ports, but it seems unlikely anyone will do this.) Through last fall, Intel had over 100 petaflops of supercomputing power, including the “Cori” and “Trinity” supercomputers at the US Department of Energy, already booked using Knights Landing as either a processor or coprocessor. And in speaking with Intel this week, we got the impression that there are many other deals in the works for both government agencies and commercial enterprises that have not – and will not – disclose their intentions.
With the roadmap, customers know they can invest for the future, which is something customers want to be sure of before they try a radically new architecture. This is particularly true of conservative large enterprises, who perhaps don’t mind investing in new architectures but who want to know a technology will have a reasonably long life before they do. This has been an important distinction between enterprise and supercomputing centers, although in recent years, the largest HPC customers have been chosen their architectures and stuck with them for several generations before making any big leaps. The reason is simple: Changing hardware is easy, but adapting different software to new hardware can be a bear.
Here is an interesting chart that shows what applications have already been ported to the Xeon Phi architecture and the relative revenue market size of the slices of the HPC market these applications address (not exclusively, mind you).
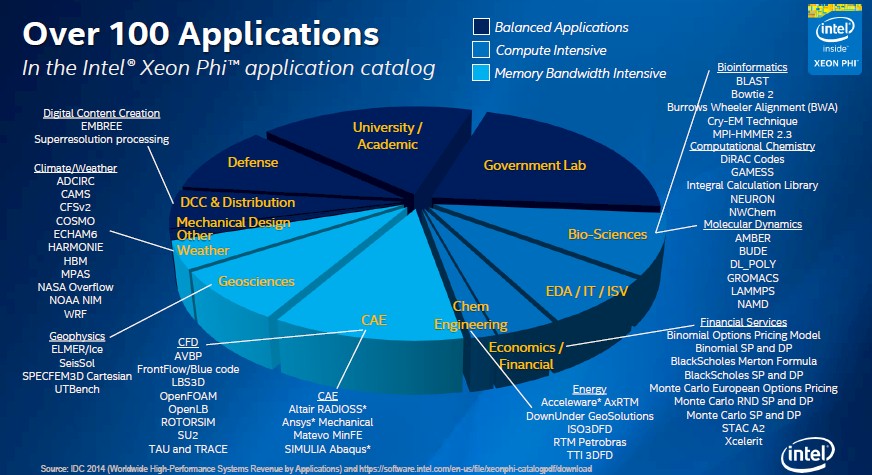
“We have several investments in open codes as well as in ISV codes right now,” explains Saleh. “But as you can imagine, running on a highly parallel processor, although we are guaranteeing that the applications will run, there are significant changes going on that as a software designer you need to parallelize and make sure you are fully utilizing all the resources that are on-die. We are happy to say that we have over 100 applications out there that we have worked on with the ecosystem in preparedness for Knights Landing.”
You can see a few things from this chart. First many of the applications that have been tuned for Knights Landing are aimed at apps that are intensive when it comes to memory bandwidth and others are more focused on compute. But about half the apps – particularly those in government labs, defense, and academia – require a balance between compute and memory bandwidth. It is hard to know where Knights Landing will shine best, since it really depends on dataset size and how scalable the code is across a network of nodes, but Intel has a number of different programming models that will allow companies to make Knights Landing machines (or have someone else do it for them) that are tuned for compute or memory bandwidth.
“Any set of applications we look at, whether they are scientific applications or broader, there is always a portion of the code that is parallel portion and then another portion that is single-thread dominant or have non-floating point calculations in it,” explains Avinash Sodani, Knights Landing chief architect at Intel. “This is why we improved the single-thread performance quite a bit with Knights Landing compared to the prior generations of parallel processor, Knights Corner. So a 3X improvement there. This is in recognition of the fact that now that it is a standalone processor, that means everything will run on it. We don’t have the option of running the single-thread dominant portion of the code somewhere else and only running the parallel section on this.”
Intel also ensured binary compatibility with the Xeon chips for those modified Silvermont cores, too, so existing codes can run on Knights Landing. Presumably codes will be tweaked to take advantage of the three different memory addressing modes that are part of the Knights Landing chip. (These memory modes are explained in detail in our initial Knights Landing story from this week.)
The Knights Landing chip will run the usual major Linux distributions as well as Microsoft’s Windows Server, which should also broaden the appeal of the chip for shops – take Microsoft’s own Azure public cloud, for instance – that are not built on a Linux base.
“This allows us to be a little more accessible to other parallel applications, even beyond HPC,” Sodani says. “Once we have silicon out in the market, we will see.”


CXL And Gen-Z Iron Out A Coherent Interconnect Strategy
To one way of looking at it, a reprise of the Bus Wars from days gone by in the late 1980s and early 1990s would have been a lot of fun. The fighting among vendors to create standards that they controlled ultimately resulted in the creation of the PCI-X and …
The Increasingly Graphic Nature Of Intel Datacenter Compute
When you get to the place where Intel is at in datacenter compute, you cannot dictate terms to customers. You have to listen very carefully and deliver what customers need or one of myriad different competitors will steal your milk money, eat your lunch, and send you to bed without …

How Far Can You Push Integration With FPGAs?
If you squint your eyes, a modern FPGA looks like a programmable logic device was crossbred with the mutt of a switch ASIC and an SoC. As architected today, FPGA sort of embodies the compute heterogeneity that is happening inside of server nodes and across datacenter clusters as well as …
Be the first to comment