
A new performance tool in the HPE Deep Learning Cookbook is providing access to a massive knowledge base of performance results to help guide users through technology selection and configuration.
Deep learning is an increasingly popular machine learning technique that many of today’s businesses are eager to capitalize on. However, the complexity surrounding the infrastructure and expertise needed for deep learning may leave you unsure of how to get started. To help resolve these issues, we developed the HPE Deep Learning Cookbook, a set of tools incorporating actual benchmarks, performance prediction and analysis, and best-practice reference designs to simplify deep learning. The HPE Deep Learning Cookbook is helping users select the optimal technology infrastructure with ease, quickly demystify deep learning techniques, and realize faster intelligence from these cutting-edge workloads.
Starting your deep learning journey
Deep learning, a subfield of artificial intelligence (AI) that uses algorithms to learn and recognize patterns similar to the human brain, has seen significant investment and research recently because of its proven ability to solve the highly complex and data-intensive challenges plaguing modern society. The extreme performance offered by high performance computing (HPC) systems powers these cognitive computing models, allowing today’s businesses to quickly train artificial neural networks (ANNs) and accelerate time-to-insight from vast volumes of data. The massively parallel computing capabilities offered by NVIDIA’s graphics processing units (GPUs) have sparked widespread adoption of deep learning techniques, helping data scientists more easily train ANNs using far larger training sets, in an order of magnitude less time, and using far less data center infrastructure.
However, while many businesses understand the value of deep learning, many lack the expertise and/or compute infrastructure to power AI-based analytics or deep learning workloads. The start of a typical journey into deep learning is filled with many questions, including:
- What GPU is best to choose for the application?
- How many GPUs are needed?
- How many systems do I need in my cluster?
- Which interconnect to use?
- Which deep learning framework is best?
For many businesses, the answers to these questions are not obvious. You may need help to make informed decisions regarding the optimal hardware and software configurations that will enable your deep learning workloads to run efficiently.
Turn to the HPE Deep Learning Cookbook
The HPE Deep Learning Cookbook addresses these challenges by offering a set of tools to help guide businesses as they choose the best hardware/software environment for a particular deep learning workload. The HPE Deep Learning Cookbook is just what it sounds like: a book of “recipes” for deep learning workloads. With the HPE Deep Learning Cookbook, HPE is setting the standard for deep learning and streamlining the process of helping businesses choose the optimal technology for implementing deep learning. The tool also helps users design the compute infrastructure that will provide the necessary performance, including purpose-built deep learning servers and next-generation GPU architectures designed specifically for deep learning, including the NVIDIA Volta GPUs .
3 key components in the HPE Deep Learning Cookbook and Performance Guide
The HPE Deep Learning Cookbook includes three key components: an automated benchmarking tool that collects performance measurements on various hardware/software configurations, a performance tool which aggregates these benchmarking results in one place and makes it easy to analyze these results, and best-practice reference designs for selected deep learning workloads. There’s also the HPE Deep Learning Performance Guide, a relatively new addition to the HPE Deep Learning Cookbook released to the public in March 2018.
The HPE Deep Learning Performance Guide has a web-based interface that provides access to a massive knowledge base of performance results that are meant to help guide technology selection and configuration. A unified place to explore benchmarking data collected with the HPE Deep Learning Benchmarking Suite, the Performance Guide enables querying and analysis of actual measured results in the current version, and in the future, will provide performance predictions based on a combination of these actual results and analytical performance models. While it is impossible to run benchmarks on all viable iterations of hardware, HPE can combine real results with analytical models to predict the performance of untested hardware configurations, and estimate how long it will take to train or run inference using a particular model or set of hardware.
Here is a sample of one of the reports available on the Performance Guide portal, which compares the training performance (in terms of throughput in images/s) using a variety of NVIDIA® Tesla® GPUs and the most common deep learning models:
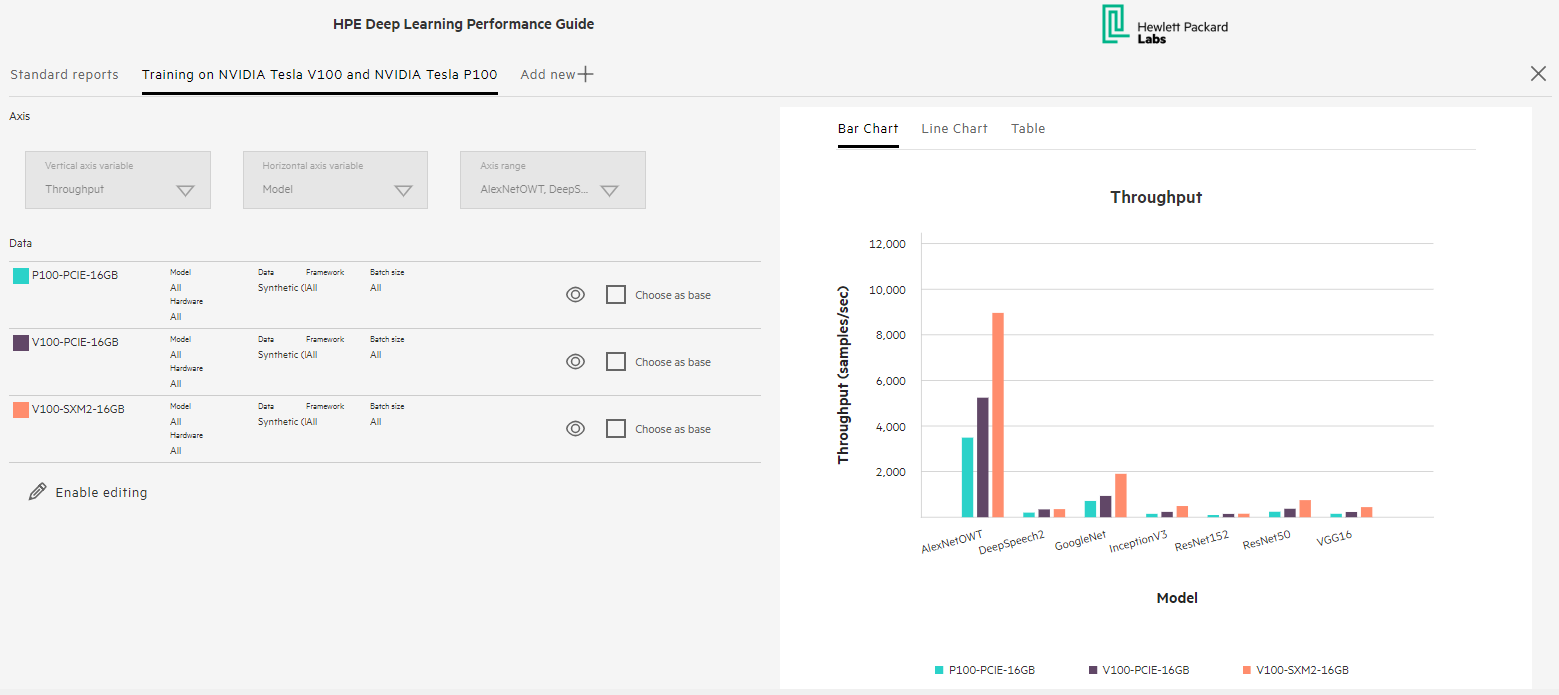
Source: HPE Deep Learning Performance Guide, “Training on NVIDIA Tesla V100 and NVIDIA Tesla P100” report, 2018
The Performance Guide is flexible enough that users can slice and dice existing performance data to create a wide range of plots to visualize different aspects of performance. It also provides an easy way to do side-by-side comparisons of multiple hardware options, deep learning frameworks, runtimes, and models, and helps detect bottlenecks in existing hardware as well as guide the design of future systems for AI and deep learning.
With the HPE Deep Learning Cookbook, HPE is creating the standard for deep learning and helping users design the optimal HW/SW stack for their real-world deep learning workloads. To learn more about how this breakthrough tool can boost your deep learning activities, please follow us on Twitter at @HPE_HPC. To stay up-to-date with recent advances in NVIDIA GPUs, please follow @NVIDIADC.
Pankaj Goyal, VP, AI Business & Data Center Strategy, Hewlett Packard Enterprise