

Updated: As we expected, the “Vista” supercomputer that the Texas Advanced Computing Center installed last year as a bridge between the current “Stampede-3” and “Frontera” production systems and its future “Horizon” system coming next year was indeed a precursor of the architecture that TACC would choose for the Horizon machine.
What TACC does – and doesn’t do – matters because as the flagship datacenter for academic supercomputing at the National Science Foundation, the company sets the pace for those HPC organizations that need to embrace AI and that have not only large jobs that require an entire system to run (so-called capability-class machines) but also have a wide diversity of smaller jobs that need to be stacked up and pushed through the system (making it also a capacity-class system). As the prior six major supercomputers installed at TACC aptly demonstrate, you can have the best of both worlds, although you do have to make different architectural choices (based on technology and economics) to accomplish what is arguably a tougher set of goals.
Some details of the Horizon machine were revealed at the SC25 supercomputing conference last week, which we have been mulling over, and initially there were a lot of things that we didn’t know. Until we came across the presentation by TACC executive director Dan Stanzione, who was speaking alongside Spectra Logic about exabyte-class tape subsystems but dropped some specs on Horizon, which will use that storage.
The Horizon that will be fired up in the spring of 2026 is a bit different than we expected, with the big change being a downshift from an expected 400 petaflops of peak FP64 floating point performance down to 300 petaflops. TACC has not explained the difference, but it might have something to do with the increasing costs of GPU-accelerated systems. As far as we know, the budget for the Horizon system, which was set in July 2024 and which includes facilities rental from Sabey Data Centers as well as other operational costs, is still $457 million. (We are attempting to confirm this as we write, but in the wake of SC25 and ahead of the Thanksgiving vacation, it is hard to reach people.)
Here is the Horizon node specs Stanzione gave out:

Horizon, as it turns out, looks very much like a more modern and heftier version of Vista, as the table below shows:
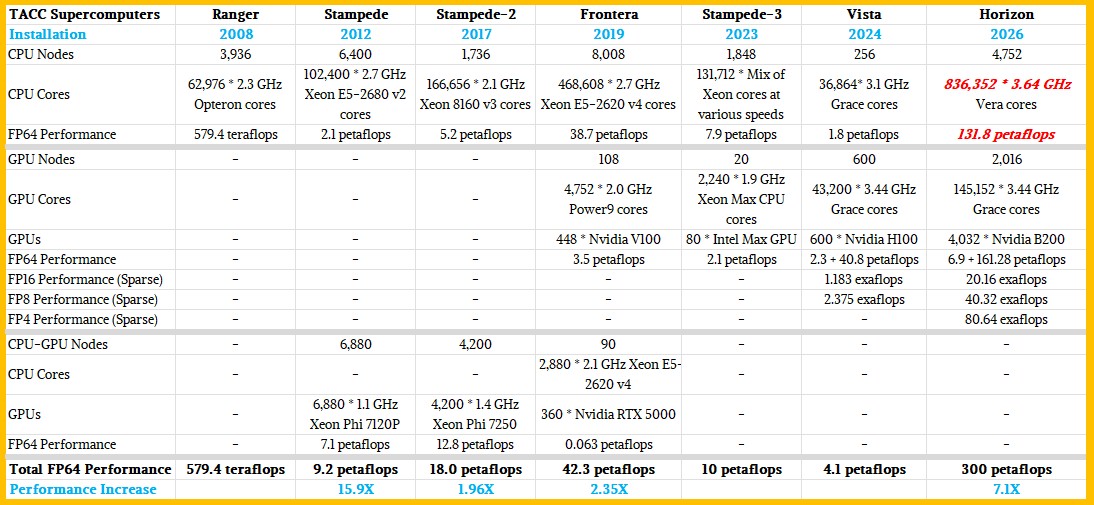
The Vista machine had a CPU partition and a CPU-GPU partition, as shown above and comprising a total of 44.9 aggregate peak theoretical FP64 performance across its CPUs and GPUs. The system also had 30 PB of capacity in the all-flash data platform from VAST Data. TACC tested out 13 PB of VAST Data storage with the “Stampede-3” upgrade two years ago, and the NFS file system storage (which also supports object and table formats natively) saw primary use on Vista and will also be the primary storage for Horizon, weighing in at 400 PB of capacity to be precise. And thanks to the way that the VAST Data platform works, all of this flash looks native and local to the CPU and GPU nodes in the Horizon cluster. That 400 PB of storage has more than 10 TB/sec of read and write bandwidth and layers on multi-tenancy security and quality of service features.
Horizon is comprised of Dell PowerEdge servers and will be integrated in Dell’s Integrated Rack Scalable Systems, which will have liquid cooling on the compute elements. We also know that the combined platforms will have systems using “Grace” CG100 Arm server CPUs and “Blackwell” GPUs, and presumably the B200 variant that has reasonable FP64 performance. (There are 40 petaflops of FP64 compute on the tensor cores in the B200 compared to a mere 1 petaflops on the B300. The latter is a very bad choice for an HPC center, unless it is only going to run GPU inference on this portion of the machine.) TACC also said that the machine would have more than 1 million cores and will have around 4,000 GPUs. (The number is actually 4,032, despite what the chart above says.)
The numbers in the press materials from TACC and Nvidia were vague and we did two different scenarios to hit the numbers. Our thanks to Glenn Lockwood of VAST Data for pointing out Stanzione’s Horizon presentation, which you can see here.
No matter how the Horizon nodes are built, we know that TACC has chosen 400 Gb/sec Quantum-2 switches (also known as Quantum X400) from Nvidia to lash the CPU and GPU compute engines together. It is very likely that ConnectX-7 network interface cards are used in the server nodes, but the announcements from TACC, Dell, and Nvidia did not say. The 800 Gb/sec Quantum X800 switches that were unveiled at GTC 2025 back in March are paired with the ConnectX-8 NICs, and these future switches are also the ones that will deliver co-packaged optics to link the switch ASICs to their front panels. We thought it was a bit strange that the switching was not doubled up to 800 Gb/sec ports with Horizon, particularly if TACC could be a testbed for the technology as HPC centers are supposed to be. We surmised that maybe TACC just wants to get Horizon running and Frontera dismantled and move on to the next problem. . . .and as it turns out, it looks like the Grace-Blackwell node has two 400 Gb/sec ports per node, for a total of 800 Gb/sec.
We are getting some time with TACC executive director Dan Stanzione to talk about the architecture of the machine and how it maps to NSF workloads. Stay tuned for that.
Horizon is expected to be in full production by next summer, and it looks like it will be one of the first systems in the world to get the Vera Arm server CPUs at scale.
One last thing: Why doesn’t TACC, which is the flagship HPC datacenter for the NSF, get an exascale-class supercomputer? Such a machine would be able to get at least three times the work done as Horizon will be able to do.


AMD Widens Server CPU Line To Take Bites Out Of Intel, Arm
The best defense is a good offense, and as it turns out, the best offense is also a good offense. So while AMD is all polite-like in its presentations, rest assured that with the ever enwidening and embiggening Epyc server chip lineup, AMD is absolutely meaning to bring offense to …
The “Hopper” GPU Compute Ramp Finally Starts
You can’t be certain about a lot of things in the world these days, but one thing you can count on is the voracious appetite for parallel compute, high bandwidth memory, and high bandwidth networking for AI training workloads. And that is why Nvidia can afford to milk its prior …

Datacenter Spending Forecast Revised Upwards – Yet Again
This is turning into a “dog bites man” story, but the forecasts for spending in the datacenter for this year keep going up and up, and a few days ago Gartner’s economists and prognosticators finished up their tea and looked at the leaves at the bottom of a cup through …