


Some details are emerging on Europe’s first exascale system, codenamed “Jupiter” and to be installed at the Jülich Supercomputing Center in Germany in 2024. There has been a lot of speculation about what Jupiter will include for its compute engines and networking and who will build and maintain the system. We now know some of this and can infer some more from the statements that were made by the organizations participating in the Jupiter effort.
In June 2022, the Forschungszentrum Jülich in Germany, which has played host to many supercomputers since it was founded in 1987, was chosen to host the first of three European exascale-class supercomputers to be funded through the EuroHPC Joint Undertaking and through the European national and state governments countries who are essentially paying to make sure these HPC and AI clusters are where they want them. With Germany having the largest economy in Europe and being a heavy user of HPC thanks to its manufacturing focus, Jülich was the obvious place to park the first machine in Europe to break the exaflops barrier.
That barrier is as much an economic one as it is a technical one. The six-year budget for Jupiter weighs in at €500 million, which is around $526.1 million at current exchange rates between the US dollar and the European euro. That is in the same ballpark price as what the “Frontier” exascale machine at Oak Ridge National Laboratory and the “El Capitan” machine that is being installed right now at Lawrence Livermore National Laboratory – both of which are based on a combination of AMD CPUs and GPUs and Hewlett Packard Enterprise’s Slingshot variant of Ethernet with HPE as the prime contractor.
Everybody knows that Jupiter was going to use SiPearl’s first generation Arm processor based on the Neoverse “Zeus” V1 core from Arm Ltd, which is codenamed “Rhea” by SiPearl and which is appropriate since Zeus and Jupiter are the same god of sky, thunder, and lightning – the Greek “Zeus Pater” with a Celtic accent becomes “Jupiter”. Rhea, of course, is the wife of Cronos and the mother of Zeus in the Greek and therefore Roman mythology. It is a pity that the French semiconductor startup could not do a design based on the Neoverse “Demeter” V2 core – the one that Nvidia is using in its “Grace” Arm server CPU. But frankly, the CPU host is not as important as the GPU accelerators when it comes to vector and matrix math oomph. To be sure, the vector performance of the CPU host is important for all-CPU applications that haven’t been ported to accelerators or can’t easily or economically be ported to GPUs or other kinds of accelerators, and there is every indication that the Rhea1 chips will be able to do these jobs better than existing supercomputers at Jülich. We shall see when more feeds and speeds of the system are announced at the upcoming SC23 supercomputing conference in Denver next month.
The word on the street is that the 1 exaflops figure that the EuroHPC project and that Jülich has talked about when referring to the Jupiter system is a metric gauging the High Performance Linpack (HPL) benchmark performance on this system, and that allows us to do some rough math on how many accelerators might be in the Jupiter machine and what the peak theoretical performance of the Jupiter machine might be.
Back in June last year, we did not think that Jülich was going to be using Intel’s “Ponte Vecchio” Max Series GPUs in Jupiter, although there may be a partition for a few dozen of these devices in there just to give Intel something to talk about. And the reason is simple: The Intel GPUs burn a lot more power than AMD and Nvidia alternatives for a given performance. We also did not think Jülich would be able to get its hands on enough of AMD’s “Antares” Instinct MI300X or MI300A GPU accelerators to build an exaflops-class system, but again, we think there will probably be a partition inside Jupiter based on AMD GPUs so researchers can do bakeoffs between architectures.
This week, EuroHPC confirmed that Nvidia was supplying the accelerators for the GPU Booster modules that will account for the bulk of the computational power in the Jupiter system.
As was the case with the LUMI pre-exascale system at CSC Finland, EuroHPC is taking a modular approach to the Jupiter system, as you can see below:

The Universal Cluster at the heart of the system is the one based on the SiPearl Rhea1 CPUs, which is also known as the Cluster Module in the EuroHPC presentations. No details were given about what Nvidia technology would be deployed in the Booster Module. We walked through the possible scenarios to get to 1 exaflops in our June 2022 coverage, and just for the heck of it we are going to guess that EuroHPC will make the right price/performance and the right thermal choice and employ the PCI-Express versions of the “Hopper” H100 GPUs – not the SXM5 versions on the HGX motherboards that have NVSwitch interconnects to provide NUMA memory sharing across the GPUs inside of a server node.
To get 1 exaflops sustained Linpack performance, we think it might take 60,000 H100 PCI-Express H100s, which would have a peak theoretical FP64 performance of around 1.56 exaflops; on FP16 processing for AI on the tensor cores, such a machine would be rated at 45.4 exaflops. All of these numbers seem impossibly large, but that is how the math works out. Moving the SXM versions of the H100 would double the watts but only boost the FP64 vector performance per GPU by 30.8 percent, from 26 teraflops to 34 teraflops in the most recent incarnations of the H100 (which are a bit faster than they were when announced in the summer of 2022). Moving from 350 watts to 750 watts to get tighter memory coupling and a little less than third more performance is a bad trade for an energy-conscious European exascale system.
We strongly suspect that InfiniBand interconnect will be used in the Jupiter system, but nothing has been said about this. In the prior generation Juwels supercomputer, the Booster Module had a pair of AMD “Rome” Epyc 7402 processors that linked through a PCI-Express switch to a quad of Nvidia A100 GPUs with NVLink3 ports cross-coupled to each other without NVSwitch interconnects, like this:
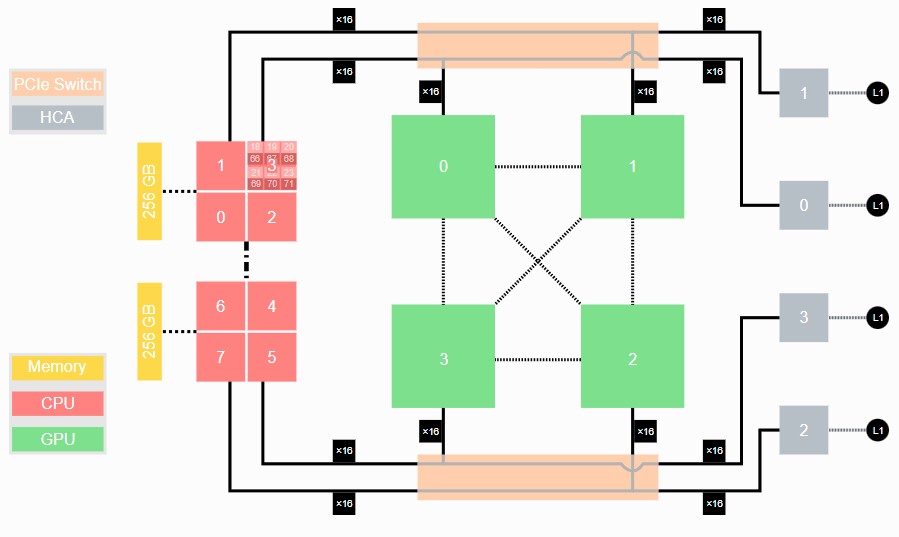
Each Rome Epyc processor had 24 cores and with SMT-2 threading turned on presented a total of 96 threads to the Linux operating system. The Juwels node had 512 GB of memory, which is pretty hefty for an HPC node but not for a GPU accelerator node. The four “Ampere” A100 GPUs had 40 GB of HBM2e memory each, for a total of 160 GB. On the right side of the block diagram, you see a quad of ConnectX-6 network interfaces from Nvidia, which provided four 200 Gb/sec InfiniBand ports into and out of the Booster Module. There are two PCI-Express 4.0 switches to link the GPUs to the InfiniBand NICs and to the CPUs.
It is highly likely that the Jupiter Booster Module will be an upgraded version of this setup. A Rhea1 processor could replace the AMD processor to start, and the Booster Modules could also be equipped with Nvidia Grace CPUs. Given that memory prices have come down, the Jupiter Booster Module will probably have 1 TB of memory, which probably means it is not a Grace GPU. It seems logical that a pair of PCI-Express 5.0 switches from Broadcom or Microchip will be used to link the CPU to the GPUs and both to the network. The PCI-Express version of Hopper H100 GPU has three NVLink 4 ports, so they can be cross coupled in a quad without an NVSwitch in the middle.
The GPU performance in the Jupiter Booster Module would be 3X to 6X that of the existing one in Juwels (depending on sparsity and whether you are doing math on the vector or tensor cores). The GPU HBM3 memory would be 2X higher and the GPU memory bandwidth inside the booster, at 9.4 TB/sec, would be 1.6X that of the A100 quad. It seems obvious that Jupiter would use a hierarchy of 400 Gb/sec Quantum 2 InfiniBand switches to link this all together. At 60,000 GPUs, we are talking about 15,000 nodes just for the Booster Modules in Jupiter. There will probably be a couple of tens of petaflops across the Cluster Modules in the CPU-only partitions.
There is also a chance that Jupiter is based on the next-gen “Blackwell” GPUs, which could be a doubled-up GPU compared to the Hopper H100s with a much lower price and much fewer of them. So maybe it is more like 8,000 nodes with a Blackwell, which works out to 32,000 GPUs. We expect for Blackwell to be Nvidia’s first chiplet architecture, and that would help drive the cost down as well as the number of units required.
These are, of course, just guesses.
Here is how this conjectured Jupiter machine might stack up to other big AI/HPC systems we have seen built in the past couple of months and its exascale peers in the United States:
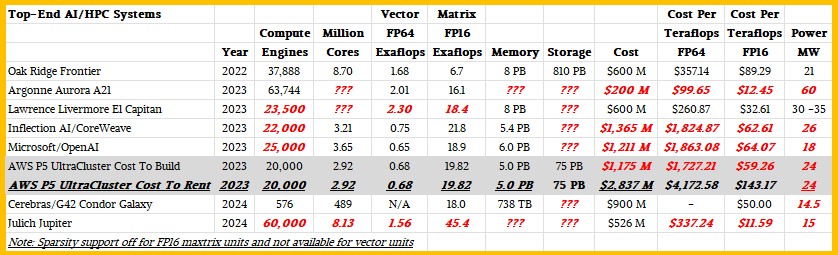
As you can see, Jupiter can compete with Frontier in terms of FP64 price/performance, but will not beat El Capitan and none of them come close to the artificially lowered price of Aurora given the $300 million writeoff Intel took against the deal with Argonne.
Everyone suspected that the Eviden HPC division of Atos would be the prime contractor on the Jupiter deal, and indeed this has come to pass. The compute elements will be installed in the liquid-cooled BullSequana XH3000 system, which we detailed here back in February 2022. German supercomputing and quantum computing vendor ParTec is supplying the ParaStation Modulo operating system, which is a custom Linux platform with an MPI stack and other cluster management and system monitoring tools all integrated together.
EuroHPC says in a statement that the cost of building, delivering, installing, and maintaining the Jupiter machine is €273 million ($287.3 million), and presumably the remaining part of that €500 million is to build or retrofit a datacenter for Jupiter and pay for power and cooling for the machine. Electricity is three times as expensive in Germany as it is in the United States, and over six years, a 15 megawatt machine could easily eat the lion’s share of the rest of that budget. Yeah, it’s crazy.
By the way: We are well aware that at a current street price of around $25,000 to $30,000 a pop for an H100 in the PCI-Express I/O variant that just the cost of 60,000 GPUs would add up to $1.5 billion to $1.8 billion. Something doesn’t add up. Maybe EuropeHPC was able to swing a killer pricing deal before the pricing on H100s popped? We still think it is more likely that Jupiter has 32,000 of the future Blackwell B100 GPU accelerators, which we expect to have close to twice the oomph of Hopper after a 3 nanometer process shrink and perhaps four GPU chiplets on a socket.
Installation of the Jupiter system will start at Jülich in the beginning of 2024. It is unclear when it will be finished, but it will almost certainly make the June or November Top500 supercomputing rankings next year. We look forward to seeing what this machine looks like, inside and out. It is likely that the CPU nodes will go in first, and that the GPU nodes will come later. We think maybe the November list, depending on when Blackwell is available in volume.